 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing Trust: Weak-to-Strong Trustworthiness in Language Models
Dec 31, 2024



The rapid proliferation of generative AI, especially large language models, has led to their integration into a variety of applications. A key phenomenon known as weak-to-strong generalization - where a strong model trained on a weak model's outputs surpasses the weak model in task performance - has gained significant attention. Yet, whether critical trustworthiness properties such as robustness, fairness, and privacy can generalize similarly remains an open question. In this work, we study this question by examining if a stronger model can inherit trustworthiness properties when fine-tuned on a weaker model's outputs, a process we term weak-to-strong trustworthiness generalization. To address this, we introduce two foundational training strategies: 1) Weak Trustworthiness Finetuning (Weak TFT), which leverages trustworthiness regularization during the fine-tuning of the weak model, and 2) Weak and Weak-to-Strong Trustworthiness Finetuning (Weak+WTS TFT), which extends regularization to both weak and strong models. Our experimental evaluation on real-world datasets reveals that while some trustworthiness properties, such as fairness, adversarial, and OOD robustness, show significant improvement in transfer when both models were regularized, others like privacy do not exhibit signs of weak-to-strong trustworthiness. As the first study to explore trustworthiness generalization via weak-to-strong generalization, our work provides valuable insights into the potential and limitations of weak-to-strong generalization.
Explaining the Model, Protecting Your Data: Revealing and Mitigating the Data Privacy Risks of Post-Hoc Model Explanations via Membership Inference
Jul 24, 2024



Predictive machine learning models are becoming increasingly deployed in high-stakes contexts involving sensitive personal data; in these contexts, there is a trade-off between model explainability and data privacy. In this work, we push the boundaries of this trade-off: with a focus on foundation models for image classification fine-tuning, we reveal unforeseen privacy risks of post-hoc model explanations and subsequently offer mitigation strategies for such risks. First, we construct VAR-LRT and L1/L2-LRT, two new membership inference attacks based on feature attribution explanations that are significantly more successful than existing explanation-leveraging attacks, particularly in the low false-positive rate regime that allows an adversary to identify specific training set members with confidence. Second, we find empirically that optimized differentially private fine-tuning substantially diminishes the success of the aforementioned attacks, while maintaining high model accuracy. We carry out a systematic empirical investigation of our 2 new attacks with 5 vision transformer architectures, 5 benchmark datasets, 4 state-of-the-art post-hoc explanation methods, and 4 privacy strength settings.
Machine Unlearning Fails to Remove Data Poisoning Attacks
Jun 25, 2024We revisit the efficacy of several practical methods for approximate machine unlearning developed for large-scale deep learning. In addition to complying with data deletion requests, one often-cited potential application for unlearning methods is to remove the effects of training on poisoned data. We experimentally demonstrate that, while existing unlearning methods have been demonstrated to be effective in a number of evaluation settings (e.g., alleviating membership inference attacks), they fail to remove the effects of data poisoning, across a variety of types of poisoning attacks (indiscriminate, targeted, and a newly-introduced Gaussian poisoning attack) and models (image classifiers and LLMs); even when granted a relatively large compute budget. In order to precisely characterize unlearning efficacy, we introduce new evaluation metrics for unlearning based on data poisoning. Our results suggest that a broader perspective, including a wider variety of evaluations, is required to avoid a false sense of confidence in machine unlearning procedures for deep learning without provable guarantees. Moreover, while unlearning methods show some signs of being useful to efficiently remove poisoned datapoints without having to retrain, our work suggests that these methods are not yet "ready for prime time", and currently provide limited benefit over retraining.
Towards Non-Adversarial Algorithmic Recourse
Mar 15, 2024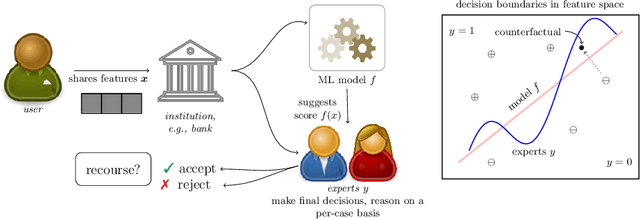
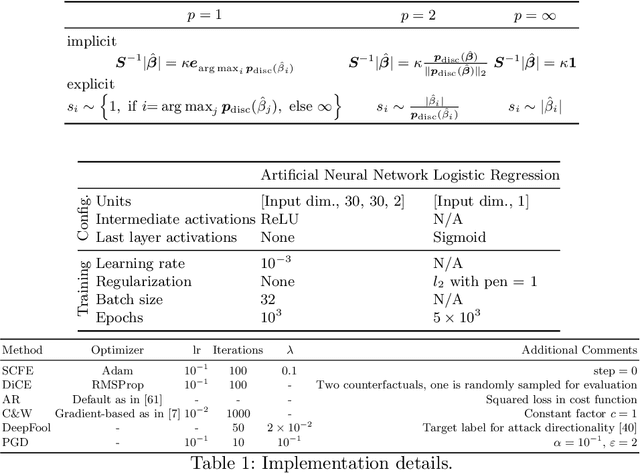
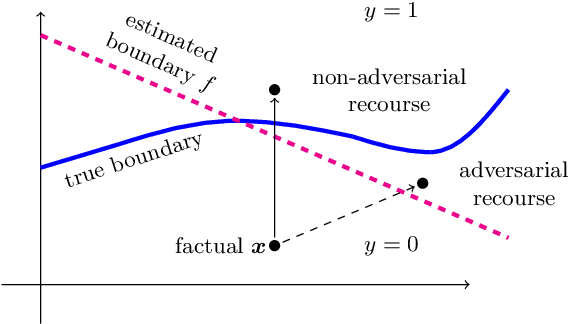

The streams of research on adversarial examples and counterfactual explanations have largely been growing independently. This has led to several recent works trying to elucidate their similarities and differences. Most prominently, it has been argued that adversarial examples, as opposed to counterfactual explanations, have a unique characteristic in that they lead to a misclassification compared to the ground truth. However, the computational goals and methodologies employed in existing counterfactual explanation and adversarial example generation methods often lack alignment with this requirement. Using formal definitions of adversarial examples and counterfactual explanations, we introduce non-adversarial algorithmic recourse and outline why in high-stakes situations, it is imperative to obtain counterfactual explanations that do not exhibit adversarial characteristics. We subsequently investigate how different components in the objective functions, e.g., the machine learning model or cost function used to measure distance, determine whether the outcome can be considered an adversarial example or not. Our experiments on common datasets highlight that these design choices are often more critical in deciding whether recourse is non-adversarial than whether recourse or attack algorithms are used. Furthermore, we show that choosing a robust and accurate machine learning model results in less adversarial recourse desired in practice.
In-Context Unlearning: Language Models as Few Shot Unlearners
Oct 12, 2023Machine unlearning, the study of efficiently removing the impact of specific training points on the trained model, has garnered increased attention of late, driven by the need to comply with privacy regulations like the Right to be Forgotten. Although unlearning is particularly relevant for LLMs in light of the copyright issues they raise, achieving precise unlearning is computationally infeasible for very large models. To this end, recent work has proposed several algorithms which approximate the removal of training data without retraining the model. These algorithms crucially rely on access to the model parameters in order to update them, an assumption that may not hold in practice due to computational constraints or when the LLM is accessed via API. In this work, we propose a new class of unlearning methods for LLMs we call ''In-Context Unlearning'', providing inputs in context and without having to update model parameters. To unlearn a particular training instance, we provide the instance alongside a flipped label and additional correctly labelled instances which are prepended as inputs to the LLM at inference time. Our experimental results demonstrate that these contexts effectively remove specific information from the training set while maintaining performance levels that are competitive with (or in some cases exceed) state-of-the-art unlearning methods that require access to the LLM parameters.
Gaussian Membership Inference Privacy
Jun 12, 2023We propose a new privacy notion called $f$-Membership Inference Privacy ($f$-MIP), which explicitly considers the capabilities of realistic adversaries under the membership inference attack threat model. By doing so $f$-MIP offers interpretable privacy guarantees and improved utility (e.g., better classification accuracy). Our novel theoretical analysis of likelihood ratio-based membership inference attacks on noisy stochastic gradient descent (SGD) results in a parametric family of $f$-MIP guarantees that we refer to as $\mu$-Gaussian Membership Inference Privacy ($\mu$-GMIP). Our analysis additionally yields an analytical membership inference attack that offers distinct advantages over previous approaches. First, unlike existing methods, our attack does not require training hundreds of shadow models to approximate the likelihood ratio. Second, our analytical attack enables straightforward auditing of our privacy notion $f$-MIP. Finally, our analysis emphasizes the importance of various factors, such as hyperparameters (e.g., batch size, number of model parameters) and data specific characteristics in controlling an attacker's success in reliably inferring a given point's membership to the training set. We demonstrate the effectiveness of our method on models trained across vision and tabular datasets.
On the Privacy Risks of Algorithmic Recourse
Nov 10, 2022



As predictive models are increasingly being employed to make consequential decisions, there is a growing emphasis on developing techniques that can provide algorithmic recourse to affected individuals. While such recourses can be immensely beneficial to affected individuals, potential adversaries could also exploit these recourses to compromise privacy. In this work, we make the first attempt at investigating if and how an adversary can leverage recourses to infer private information about the underlying model's training data. To this end, we propose a series of novel membership inference attacks which leverage algorithmic recourse. More specifically, we extend the prior literature on membership inference attacks to the recourse setting by leveraging the distances between data instances and their corresponding counterfactuals output by state-of-the-art recourse methods. Extensive experimentation with real world and synthetic datasets demonstrates significant privacy leakage through recourses. Our work establishes unintended privacy leakage as an important risk in the widespread adoption of recourse methods.
Decomposing Counterfactual Explanations for Consequential Decision Making
Nov 03, 2022The goal of algorithmic recourse is to reverse unfavorable decisions (e.g., from loan denial to approval) under automated decision making by suggesting actionable feature changes (e.g., reduce the number of credit cards). To generate low-cost recourse the majority of methods work under the assumption that the features are independently manipulable (IMF). To address the feature dependency issue the recourse problem is usually studied through the causal recourse paradigm. However, it is well known that strong assumptions, as encoded in causal models and structural equations, hinder the applicability of these methods in complex domains where causal dependency structures are ambiguous. In this work, we develop \texttt{DEAR} (DisEntangling Algorithmic Recourse), a novel and practical recourse framework that bridges the gap between the IMF and the strong causal assumptions. \texttt{DEAR} generates recourses by disentangling the latent representation of co-varying features from a subset of promising recourse features to capture the main practical recourse desiderata. Our experiments on real-world data corroborate our theoretically motivated recourse model and highlight our framework's ability to provide reliable, low-cost recourse in the presence of feature dependencies.
I Prefer not to Say: Operationalizing Fair and User-guided Data Minimization
Nov 01, 2022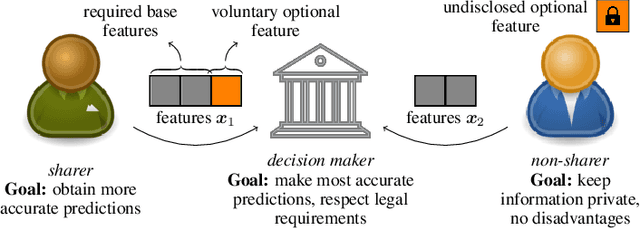
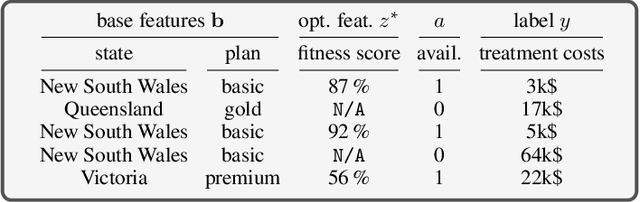
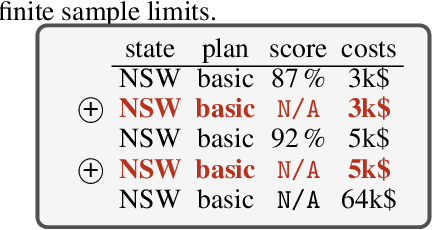
To grant users greater authority over their personal data, policymakers have suggested tighter data protection regulations (e.g., GDPR, CCPA). One key principle within these regulations is data minimization, which urges companies and institutions to only collect data that is relevant and adequate for the purpose of the data analysis. In this work, we take a user-centric perspective on this regulation, and let individual users decide which data they deem adequate and relevant to be processed by a machine-learned model. We require that users who decide to provide optional information should appropriately benefit from sharing their data, while users who rely on the mandate to leave their data undisclosed should not be penalized for doing so. This gives rise to the overlooked problem of fair treatment between individuals providing additional information and those choosing not to. While the classical fairness literature focuses on fair treatment between advantaged and disadvantaged groups, an initial look at this problem through the lens of classical fairness notions reveals that they are incompatible with these desiderata. We offer a solution to this problem by proposing the notion of Optional Feature Fairness (OFF) that follows from our requirements. To operationalize OFF, we derive a multi-model strategy and a tractable logistic regression model. We analyze the effect and the cost of applying OFF on several real-world data sets.
Language Models are Realistic Tabular Data Generators
Oct 12, 2022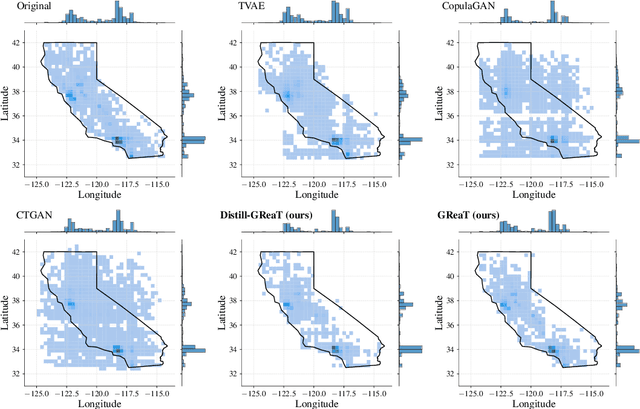
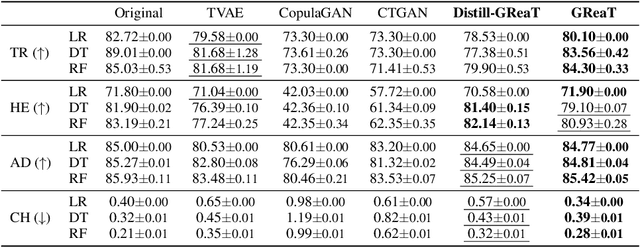
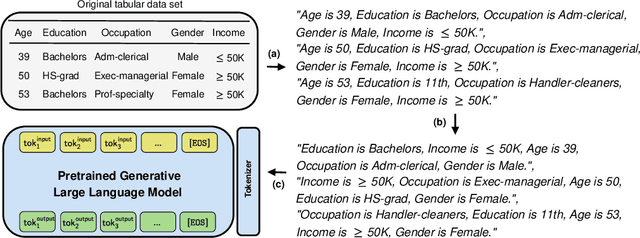
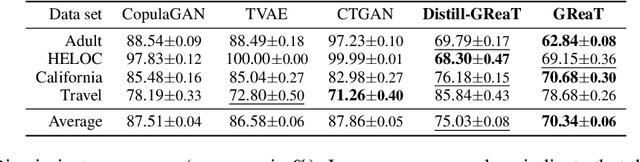
Tabular data is among the oldest and most ubiquitous forms of data. However, the generation of synthetic samples with the original data's characteristics still remains a significant challenge for tabular data. While many generative models from the computer vision domain, such as autoencoders or generative adversarial networks, have been adapted for tabular data generation, less research has been directed towards recent transformer-based large language models (LLMs), which are also generative in nature. To this end, we propose GReaT (Generation of Realistic Tabular data), which exploits an auto-regressive generative LLM to sample synthetic and yet highly realistic tabular data. Furthermore, GReaT can model tabular data distributions by conditioning on any subset of features; the remaining features are sampled without additional overhead. We demonstrate the effectiveness of the proposed approach in a series of experiments that quantify the validity and quality of the produced data samples from multiple angles. We find that GReaT maintains state-of-the-art performance across many real-world data sets with heterogeneous feature types.