 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining the Model, Protecting Your Data: Revealing and Mitigating the Data Privacy Risks of Post-Hoc Model Explanations via Membership Inference
Jul 24, 2024



Predictive machine learning models are becoming increasingly deployed in high-stakes contexts involving sensitive personal data; in these contexts, there is a trade-off between model explainability and data privacy. In this work, we push the boundaries of this trade-off: with a focus on foundation models for image classification fine-tuning, we reveal unforeseen privacy risks of post-hoc model explanations and subsequently offer mitigation strategies for such risks. First, we construct VAR-LRT and L1/L2-LRT, two new membership inference attacks based on feature attribution explanations that are significantly more successful than existing explanation-leveraging attacks, particularly in the low false-positive rate regime that allows an adversary to identify specific training set members with confidence. Second, we find empirically that optimized differentially private fine-tuning substantially diminishes the success of the aforementioned attacks, while maintaining high model accuracy. We carry out a systematic empirical investigation of our 2 new attacks with 5 vision transformer architectures, 5 benchmark datasets, 4 state-of-the-art post-hoc explanation methods, and 4 privacy strength settings.
Accurate, Explainable, and Private Models: Providing Recourse While Minimizing Training Data Leakage
Aug 08, 2023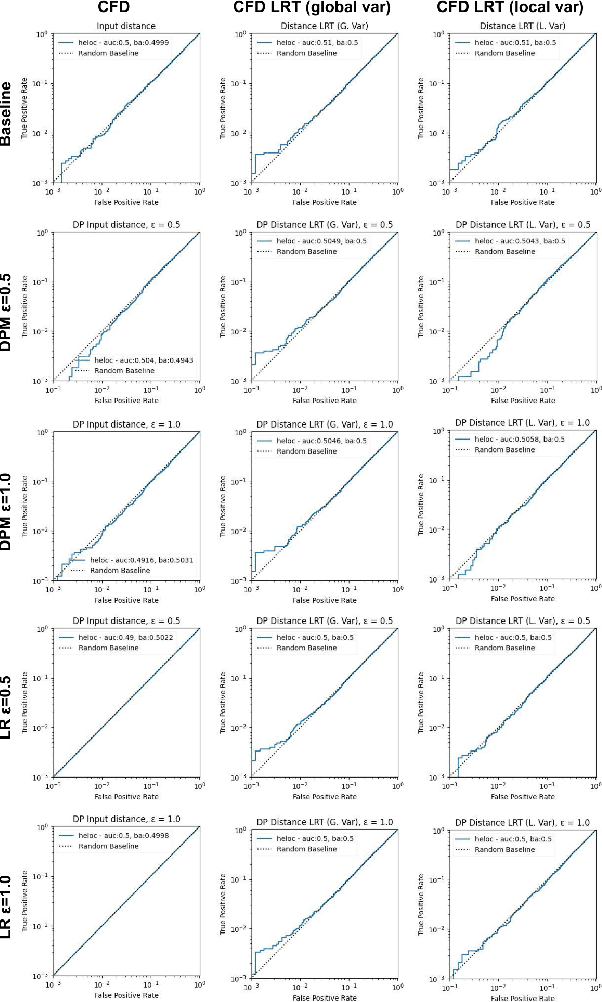
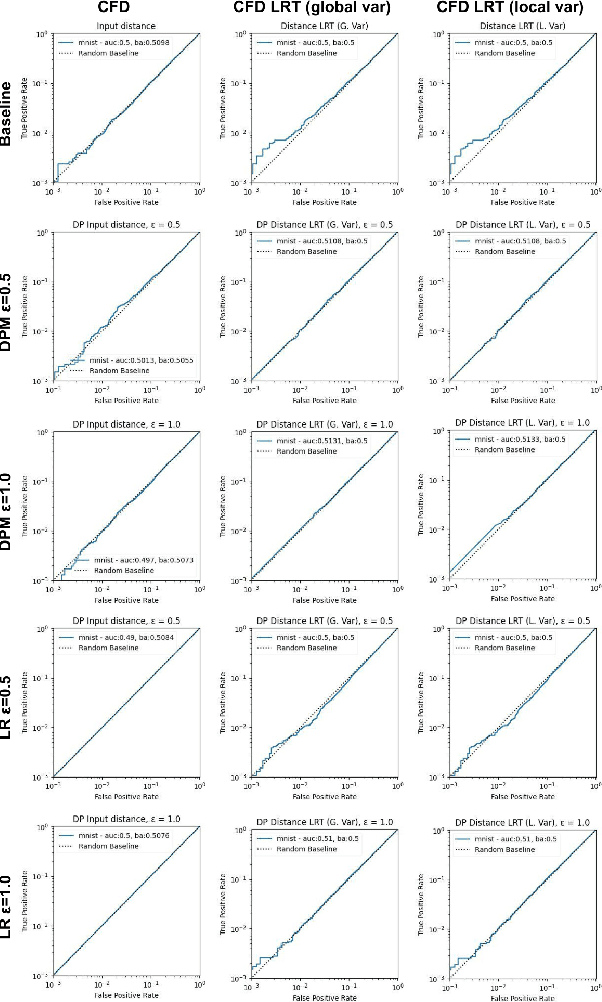
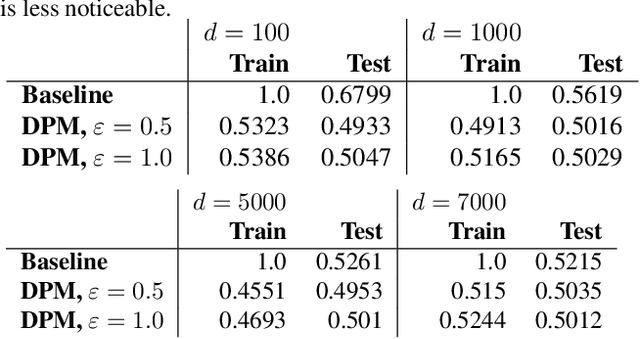
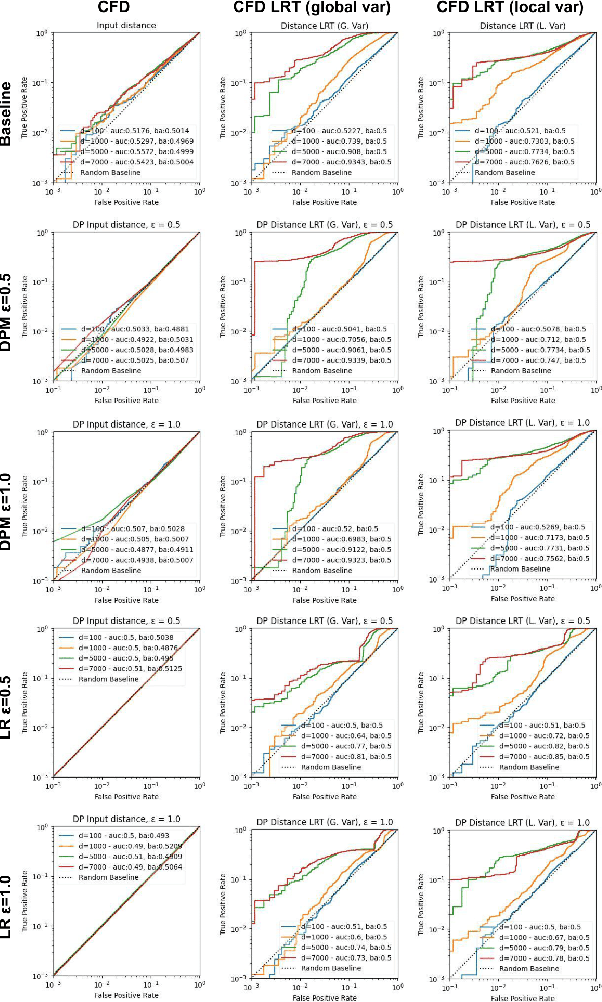
Machine learning models are increasingly utilized across impactful domains to predict individual outcomes. As such, many models provide algorithmic recourse to individuals who receive negative outcomes. However, recourse can be leveraged by adversaries to disclose private information. This work presents the first attempt at mitigating such attacks. We present two novel methods to generate differentially private recourse: Differentially Private Model (DPM) and Laplace Recourse (LR). Using logistic regression classifiers and real world and synthetic datasets, we find that DPM and LR perform well in reducing what an adversary can infer, especially at low FPR. When training dataset size is large enough, we find particular success in preventing privacy leakage while maintaining model and recourse accuracy with our novel LR method.
Offline Meta-Reinforcement Learning with Online Self-Supervision
Jul 19, 2021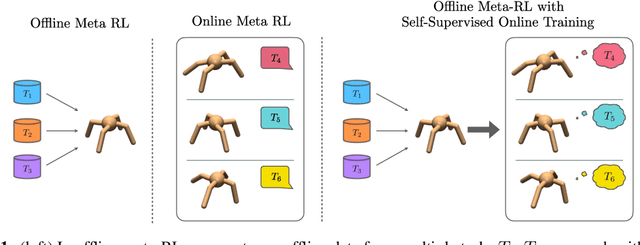
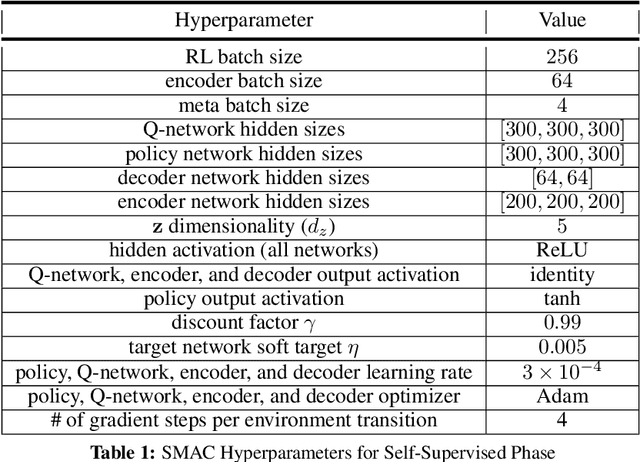
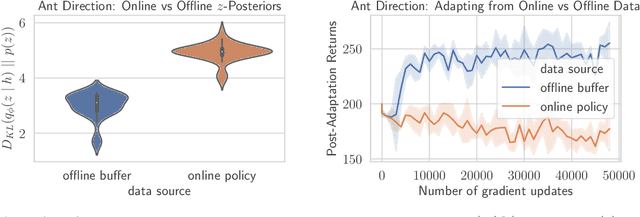
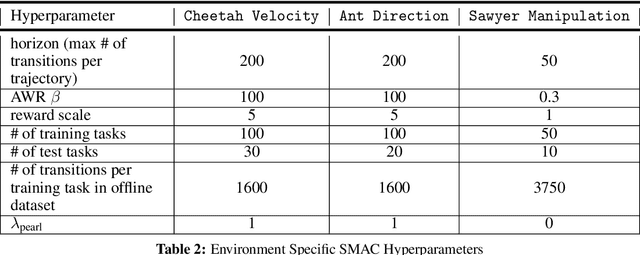
Meta-reinforcement learning (RL) can meta-train policies that adapt to new tasks with orders of magnitude less data than standard RL, but meta-training itself is costly and time-consuming. If we can meta-train on offline data, then we can reuse the same static dataset, labeled once with rewards for different tasks, to meta-train policies that adapt to a variety of new tasks at meta-test time. Although this capability would make meta-RL a practical tool for real-world use, offline meta-RL presents additional challenges beyond online meta-RL or standard offline RL settings. Meta-RL learns an exploration strategy that collects data for adapting, and also meta-trains a policy that quickly adapts to data from a new task. Since this policy was meta-trained on a fixed, offline dataset, it might behave unpredictably when adapting to data collected by the learned exploration strategy, which differs systematically from the offline data and thus induces distributional shift. We do not want to remove this distributional shift by simply adopting a conservative exploration strategy, because learning an exploration strategy enables an agent to collect better data for faster adaptation. Instead, we propose a hybrid offline meta-RL algorithm, which uses offline data with rewards to meta-train an adaptive policy, and then collects additional unsupervised online data, without any reward labels to bridge this distribution shift. By not requiring reward labels for online collection, this data can be much cheaper to collect. We compare our method to prior work on offline meta-RL on simulated robot locomotion and manipulation tasks and find that using additional unsupervised online data collection leads to a dramatic improvement in the adaptive capabilities of the meta-trained policies, matching the performance of fully online meta-RL on a range of challenging domains that require generalization to new tasks.