 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Prefer not to Say: Operationalizing Fair and User-guided Data Minimization
Nov 01, 2022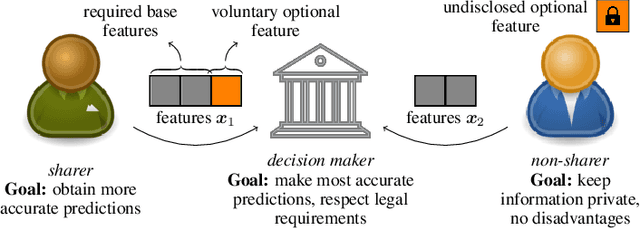
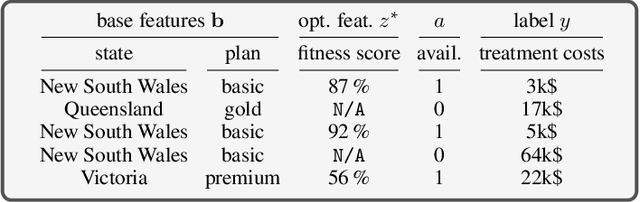
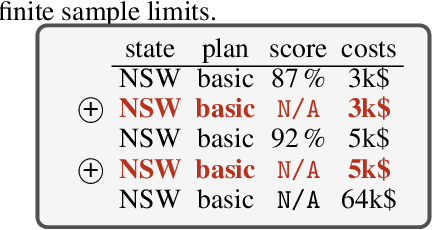
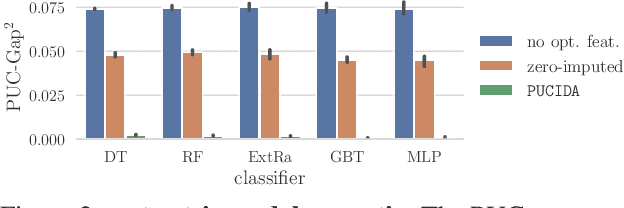
To grant users greater authority over their personal data, policymakers have suggested tighter data protection regulations (e.g., GDPR, CCPA). One key principle within these regulations is data minimization, which urges companies and institutions to only collect data that is relevant and adequate for the purpose of the data analysis. In this work, we take a user-centric perspective on this regulation, and let individual users decide which data they deem adequate and relevant to be processed by a machine-learned model. We require that users who decide to provide optional information should appropriately benefit from sharing their data, while users who rely on the mandate to leave their data undisclosed should not be penalized for doing so. This gives rise to the overlooked problem of fair treatment between individuals providing additional information and those choosing not to. While the classical fairness literature focuses on fair treatment between advantaged and disadvantaged groups, an initial look at this problem through the lens of classical fairness notions reveals that they are incompatible with these desiderata. We offer a solution to this problem by proposing the notion of Optional Feature Fairness (OFF) that follows from our requirements. To operationalize OFF, we derive a multi-model strategy and a tractable logistic regression model. We analyze the effect and the cost of applying OFF on several real-world data sets.