 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's in a Query: Polarity-Aware Distribution-Based Fair Ranking
Feb 17, 2025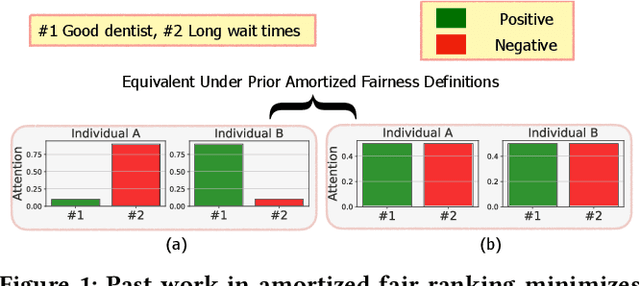
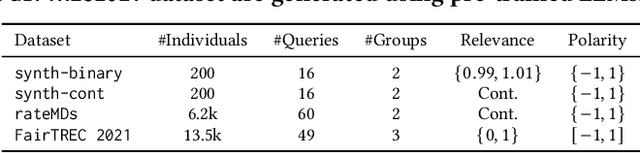
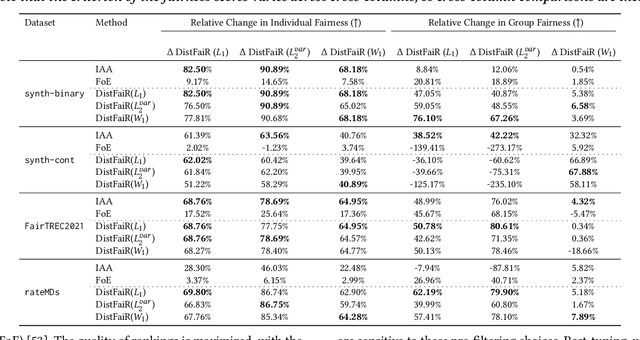
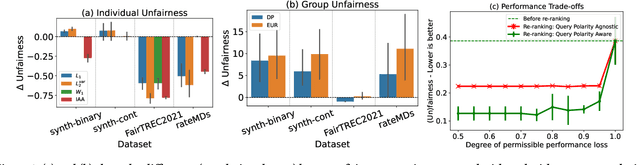
Machine learning-driven rankings, where individuals (or items) are ranked in response to a query, mediate search exposure or attention in a variety of safety-critical settings. Thus, it is important to ensure that such rankings are fair. Under the goal of equal opportunity, attention allocated to an individual on a ranking interface should be proportional to their relevance across search queries. In this work, we examine amortized fair ranking -- where relevance and attention are cumulated over a sequence of user queries to make fair ranking more feasible in practice. Unlike prior methods that operate on expected amortized attention for each individual, we define new divergence-based measures for attention distribution-based fairness in ranking (DistFaiR), characterizing unfairness as the divergence between the distribution of attention and relevance corresponding to an individual over time. This allows us to propose new definitions of unfairness, which are more reliable at test time. Second, we prove that group fairness is upper-bounded by individual fairness under this definition for a useful class of divergence measures, and experimentally show that maximizing individual fairness through an integer linear programming-based optimization is often beneficial to group fairness. Lastly, we find that prior research in amortized fair ranking ignores critical information about queries, potentially leading to a fairwashing risk in practice by making rankings appear more fair than they actually are.
Unlocking Fair Use in the Generative AI Supply Chain: A Systematized Literature Review
Aug 01, 2024

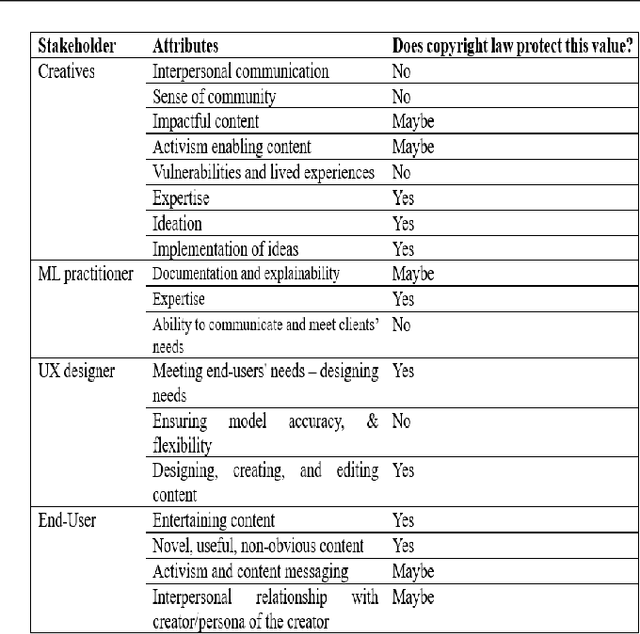
Through a systematization of generative AI (GenAI) stakeholder goals and expectations, this work seeks to uncover what value different stakeholders see in their contributions to the GenAI supply line. This valuation enables us to understand whether fair use advocated by GenAI companies to train model progresses the copyright law objective of promoting science and arts. While assessing the validity and efficacy of the fair use argument, we uncover research gaps and potential avenues for future works for researchers and policymakers to address.
The Role of Relevance in Fair Ranking
May 09, 2023Online platforms mediate access to opportunity: relevance-based rankings create and constrain options by allocating exposure to job openings and job candidates in hiring platforms, or sellers in a marketplace. In order to do so responsibly, these socially consequential systems employ various fairness measures and interventions, many of which seek to allocate exposure based on worthiness. Because these constructs are typically not directly observable, platforms must instead resort to using proxy scores such as relevance and infer them from behavioral signals such as searcher clicks. Yet, it remains an open question whether relevance fulfills its role as such a worthiness score in high-stakes fair rankings. In this paper, we combine perspectives and tools from the social sciences, information retrieval, and fairness in machine learning to derive a set of desired criteria that relevance scores should satisfy in order to meaningfully guide fairness interventions. We then empirically show that not all of these criteria are met in a case study of relevance inferred from biased user click data. We assess the impact of these violations on the estimated system fairness and analyze whether existing fairness interventions may mitigate the identified issues. Our analyses and results surface the pressing need for new approaches to relevance collection and generation that are suitable for use in fair ranking.
On the Trade-Off between Actionable Explanations and the Right to be Forgotten
Aug 30, 2022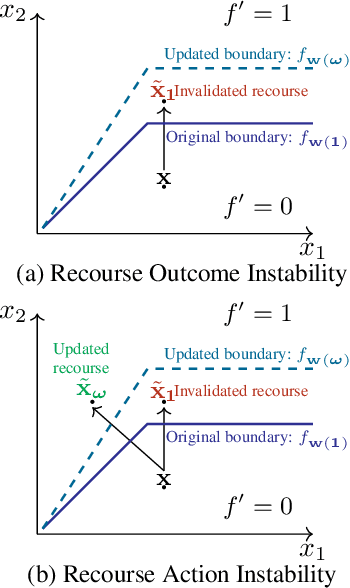

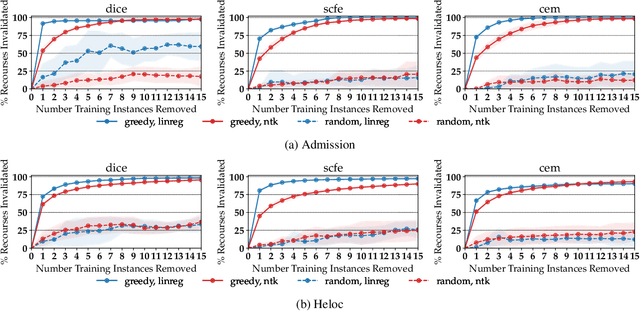
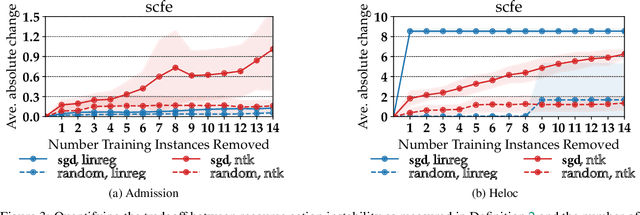
As machine learning (ML) models are increasingly being deployed in high-stakes applications, policymakers have suggested tighter data protection regulations (e.g., GDPR, CCPA). One key principle is the ``right to be forgotten'' which gives users the right to have their data deleted. Another key principle is the right to an actionable explanation, also known as algorithmic recourse, allowing users to reverse unfavorable decisions. To date it is unknown whether these two principles can be operationalized simultaneously. Therefore, we introduce and study the problem of recourse invalidation in the context of data deletion requests. More specifically, we theoretically and empirically analyze the behavior of popular state-of-the-art algorithms and demonstrate that the recourses generated by these algorithms are likely to be invalidated if a small number of data deletion requests (e.g., 1 or 2) warrant updates of the predictive model. For the setting of linear models and overparameterized neural networks -- studied through the lens of neural tangent kernels (NTKs) -- we suggest a framework to identify a minimal subset of critical training points, which when removed, would lead to maximize the fraction of invalidated recourses. Using our framework, we empirically establish that the removal of as little as 2 data instances from the training set can invalidate up to 95 percent of all recourses output by popular state-of-the-art algorithms. Thus, our work raises fundamental questions about the compatibility of ``the right to an actionable explanation'' in the context of the ``right to be forgotten''.
Estimation of Fair Ranking Metrics with Incomplete Judgments
Aug 11, 2021
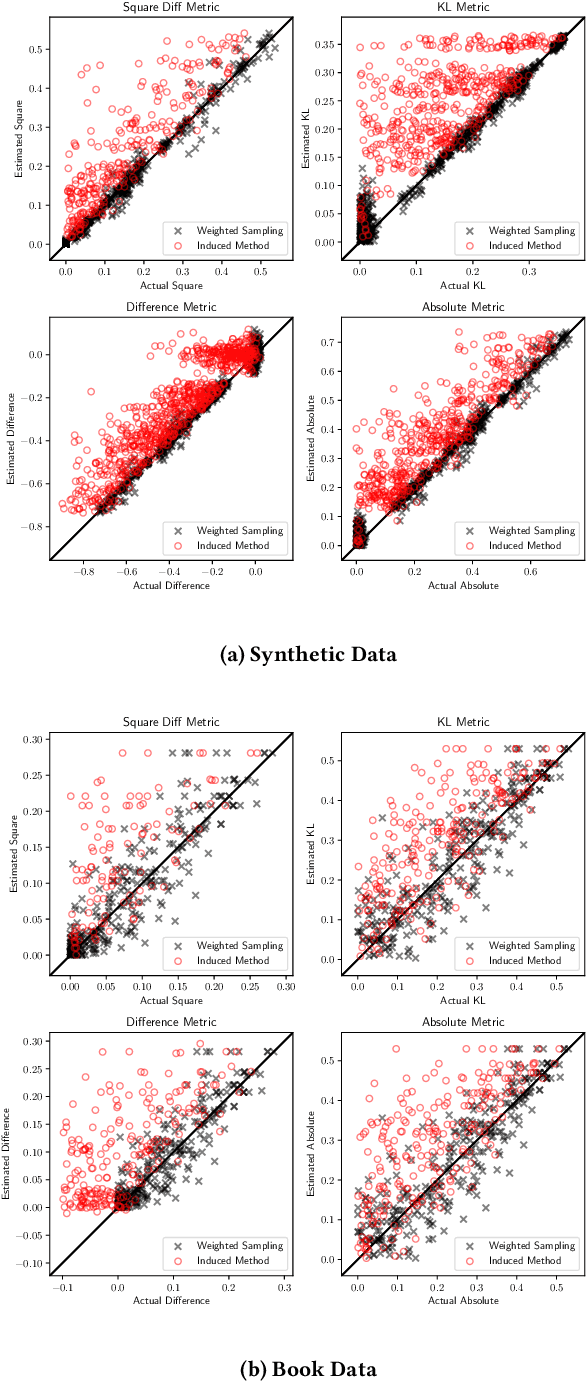
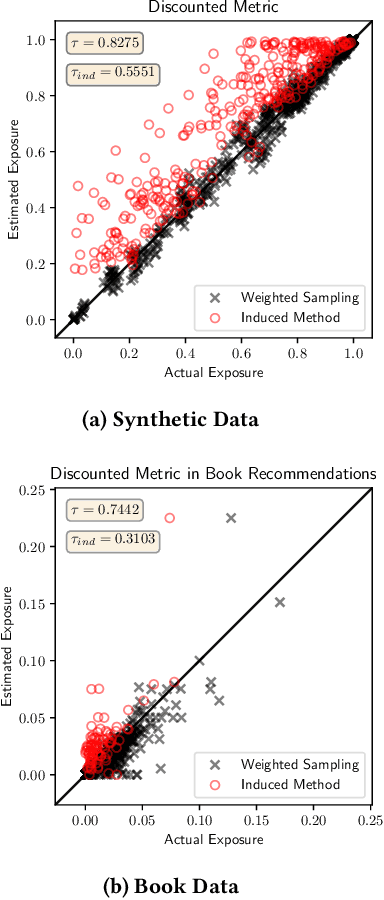

There is increasing attention to evaluating the fairness of search system ranking decisions. These metrics often consider the membership of items to particular groups, often identified using protected attributes such as gender or ethnicity. To date, these metrics typically assume the availability and completeness of protected attribute labels of items. However, the protected attributes of individuals are rarely present, limiting the application of fair ranking metrics in large scale systems. In order to address this problem, we propose a sampling strategy and estimation technique for four fair ranking metrics. We formulate a robust and unbiased estimator which can operate even with very limited number of labeled items. We evaluate our approach using both simulated and real world data. Our experimental results demonstrate that our method can estimate this family of fair ranking metrics and provides a robust, reliable alternative to exhaustive or random data annotation.
Learning to Limit Data Collection via Scaling Laws: Data Minimization Compliance in Practice
Jul 16, 2021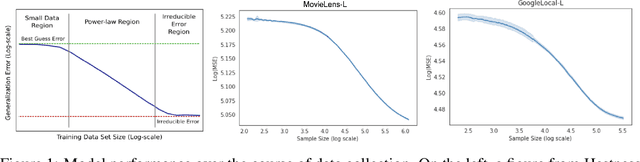
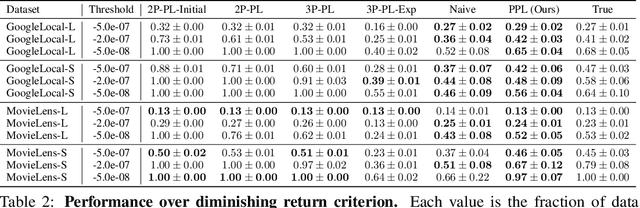
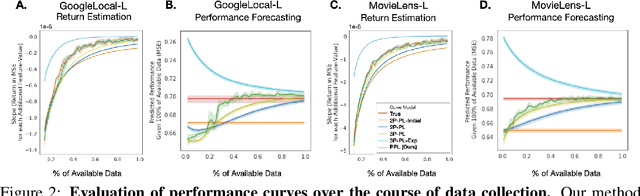
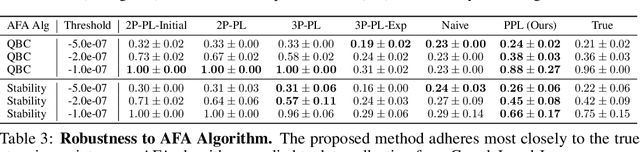
Data minimization is a legal obligation defined in the European Union's General Data Protection Regulation (GDPR) as the responsibility to process an adequate, relevant, and limited amount of personal data in relation to a processing purpose. However, unlike fairness or transparency, the principle has not seen wide adoption for machine learning systems due to a lack of computational interpretation. In this paper, we build on literature in machine learning and law to propose the first learning framework for limiting data collection based on an interpretation that ties the data collection purpose to system performance. We formalize a data minimization criterion based on performance curve derivatives and provide an effective and interpretable piecewise power law technique that models distinct stages of an algorithm's performance throughout data collection. Results from our empirical investigation offer deeper insights into the relevant considerations when designing a data minimization framework, including the choice of feature acquisition algorithm, initialization conditions, as well as impacts on individuals that hint at tensions between data minimization and fairness.
Reviving Purpose Limitation and Data Minimisation in Personalisation, Profiling and Decision-Making Systems
Jan 15, 2021This paper determines, through an interdisciplinary law and computer science lens, whether data minimisation and purpose limitation can be meaningfully implemented in data-driven algorithmic systems, including personalisation, profiling and decision-making systems. Our analysis reveals that the two legal principles continue to play an important role in mitigating the risks of personal data processing, allowing us to rebut claims that they have become obsolete. The paper goes beyond this finding, however. We highlight that even though these principles are important safeguards in the systems under consideration, there are important limits to their practical implementation, namely, (i) the difficulties of measuring law and the resulting open computational research questions as well as a lack of concrete guidelines for practitioners; (ii) the unacknowledged trade-offs between various GDPR principles, notably between data minimisation on the one hand and accuracy or fairness on the other; (iii) the lack of practical means of removing personal data from trained models in order to ensure legal compliance; and (iv) the insufficient enforcement of data protection law.