 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Language of Trauma: Modeling Traumatic Event Descriptions Across Domains with Explainable AI
Aug 12, 2024


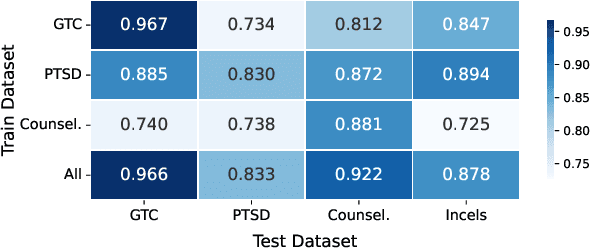
Psychological trauma can manifest following various distressing events and is captured in diverse online contexts. However, studies traditionally focus on a single aspect of trauma, often neglecting the transferability of findings across different scenarios. We address this gap by training language models with progressing complexity on trauma-related datasets, including genocide-related court data, a Reddit dataset on post-traumatic stress disorder (PTSD), counseling conversations, and Incel forum posts. Our results show that the fine-tuned RoBERTa model excels in predicting traumatic events across domains, slightly outperforming large language models like GPT-4. Additionally, SLALOM-feature scores and conceptual explanations effectively differentiate and cluster trauma-related language, highlighting different trauma aspects and identifying sexual abuse and experiences related to death as a common traumatic event across all datasets. This transferability is crucial as it allows for the development of tools to enhance trauma detection and intervention in diverse populations and settings.
Large Language Models and Thematic Analysis: Human-AI Synergy in Researching Hate Speech on Social Media
Aug 09, 2024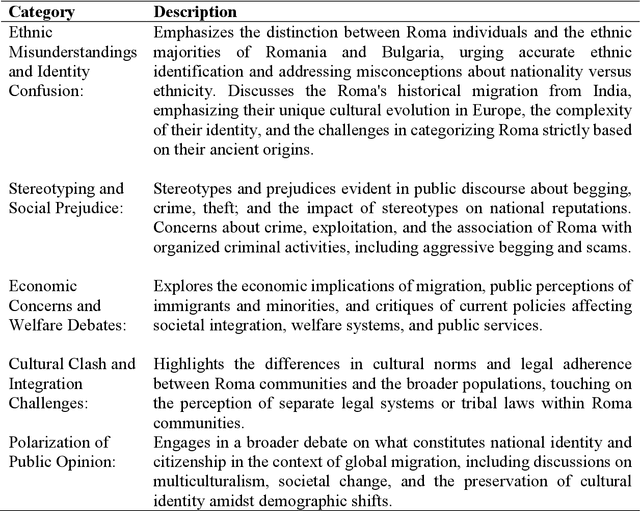
In the dynamic field of artificial intelligence (AI), the development and application of Large Language Models (LLMs) for text analysis are of significant academic interest. Despite the promising capabilities of various LLMs in conducting qualitative analysis, their use in the humanities and social sciences has not been thoroughly examined. This article contributes to the emerging literature on LLMs in qualitative analysis by documenting an experimental study involving GPT-4. The study focuses on performing thematic analysis (TA) using a YouTube dataset derived from an EU-funded project, which was previously analyzed by other researchers. This dataset is about the representation of Roma migrants in Sweden during 2016, a period marked by the aftermath of the 2015 refugee crisis and preceding the Swedish national elections in 2017. Our study seeks to understand the potential of combining human intelligence with AI's scalability and efficiency, examining the advantages and limitations of employing LLMs in qualitative research within the humanities and social sciences. Additionally, we discuss future directions for applying LLMs in these fields.
A New Dataset for Topic-Based Paragraph Classification in Genocide-Related Court Transcripts
Apr 06, 2022


Recent progress in natural language processing has been impressive in many different areas with transformer-based approaches setting new benchmarks for a wide range of applications. This development has also lowered the barriers for people outside the NLP community to tap into the tools and resources applied to a variety of domain-specific applications. The bottleneck however still remains the lack of annotated gold-standard collections as soon as one's research or professional interest falls outside the scope of what is readily available. One such area is genocide-related research (also including the work of experts who have a professional interest in accessing, exploring and searching large-scale document collections on the topic, such as lawyers). We present GTC (Genocide Transcript Corpus), the first annotated corpus of genocide-related court transcripts which serves three purposes: (1) to provide a first reference corpus for the community, (2) to establish benchmark performances (using state-of-the-art transformer-based approaches) for the new classification task of paragraph identification of violence-related witness statements, (3) to explore first steps towards transfer learning within the domain. We consider our contribution to be addressing in particular this year's hot topic on Language Technology for All.