 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedNuggetizer: Confidence-Based Information Nugget Extraction from Medical Documents
Dec 17, 2025We present MedNuggetizer, https://mednugget-ai.de/; access is available upon request.}, a tool for query-driven extraction and clustering of information nuggets from medical documents to support clinicians in exploring underlying medical evidence. Backed by a large language model (LLM), \textit{MedNuggetizer} performs repeated extractions of information nuggets that are then grouped to generate reliable evidence within and across multiple documents. We demonstrate its utility on the clinical use case of \textit{antibiotic prophylaxis before prostate biopsy} by using major urological guidelines and recent PubMed studies as sources of information. Evaluation by domain experts shows that \textit{MedNuggetizer} provides clinicians and researchers with an efficient way to explore long documents and easily extract reliable, query-focused medical evidence.
Why am I seeing this? Towards recognizing social media recommender systems with missing recommendations
Apr 15, 2025Social media plays a crucial role in shaping society, often amplifying polarization and spreading misinformation. These effects stem from complex dynamics involving user interactions, individual traits, and recommender algorithms driving content selection. Recommender systems, which significantly shape the content users see and decisions they make, offer an opportunity for intervention and regulation. However, assessing their impact is challenging due to algorithmic opacity and limited data availability. To effectively model user decision-making, it is crucial to recognize the recommender system adopted by the platform. This work introduces a method for Automatic Recommender Recognition using Graph Neural Networks (GNNs), based solely on network structure and observed behavior. To infer the hidden recommender, we first train a Recommender Neutral User model (RNU) using a GNN and an adapted hindsight academic network recommender, aiming to reduce reliance on the actual recommender in the data. We then generate several Recommender Hypothesis-specific Synthetic Datasets (RHSD) by combining the RNU with different known recommenders, producing ground truths for testing. Finally, we train Recommender Hypothesis-specific User models (RHU) under various hypotheses and compare each candidate with the original used to generate the RHSD. Our approach enables accurate detection of hidden recommenders and their influence on user behavior. Unlike audit-based methods, it captures system behavior directly, without ad hoc experiments that often fail to reflect real platforms. This study provides insights into how recommenders shape behavior, aiding efforts to reduce polarization and misinformation.
A Reproducibility Study of Graph-Based Legal Case Retrieval
Apr 11, 2025Legal retrieval is a widely studied area in Information Retrieval (IR) and a key task in this domain is retrieving relevant cases based on a given query case, often done by applying language models as encoders to model case similarity. Recently, Tang et al. proposed CaseLink, a novel graph-based method for legal case retrieval, which models both cases and legal charges as nodes in a network, with edges representing relationships such as references and shared semantics. This approach offers a new perspective on the task by capturing higher-order relationships of cases going beyond the stand-alone level of documents. However, while this shift in approaching legal case retrieval is a promising direction in an understudied area of graph-based legal IR, challenges in reproducing novel results have recently been highlighted, with multiple studies reporting difficulties in reproducing previous findings. Thus, in this work we reproduce CaseLink, a graph-based legal case retrieval method, to support future research in this area of IR. In particular, we aim to assess its reliability and generalizability by (i) first reproducing the original study setup and (ii) applying the approach to an additional dataset. We then build upon the original implementations by (iii) evaluating the approach's performance when using a more sophisticated graph data representation and (iv) using an open large language model (LLM) in the pipeline to address limitations that are known to result from using closed models accessed via an API. Our findings aim to improve the understanding of graph-based approaches in legal IR and contribute to improving reproducibility in the field. To achieve this, we share all our implementations and experimental artifacts with the community.
Understanding Learner-LLM Chatbot Interactions and the Impact of Prompting Guidelines
Apr 10, 2025Large Language Models (LLMs) have transformed human-computer interaction by enabling natural language-based communication with AI-powered chatbots. These models are designed to be intuitive and user-friendly, allowing users to articulate requests with minimal effort. However, despite their accessibility, studies reveal that users often struggle with effective prompting, resulting in inefficient responses. Existing research has highlighted both the limitations of LLMs in interpreting vague or poorly structured prompts and the difficulties users face in crafting precise queries. This study investigates learner-AI interactions through an educational experiment in which participants receive structured guidance on effective prompting. We introduce and compare three types of prompting guidelines: a task-specific framework developed through a structured methodology and two baseline approaches. To assess user behavior and prompting efficacy, we analyze a dataset of 642 interactions from 107 users. Using Von NeuMidas, an extended pragmatic annotation schema for LLM interaction analysis, we categorize common prompting errors and identify recurring behavioral patterns. We then evaluate the impact of different guidelines by examining changes in user behavior, adherence to prompting strategies, and the overall quality of AI-generated responses. Our findings provide a deeper understanding of how users engage with LLMs and the role of structured prompting guidance in enhancing AI-assisted communication. By comparing different instructional frameworks, we offer insights into more effective approaches for improving user competency in AI interactions, with implications for AI literacy, chatbot usability, and the design of more responsive AI systems.
Query Smarter, Trust Better? Exploring Search Behaviours for Verifying News Accuracy
Apr 07, 2025



While it is often assumed that searching for information to evaluate misinformation will help identify false claims, recent work suggests that search behaviours can instead reinforce belief in misleading news, particularly when users generate queries using vocabulary from the source articles. Our research explores how different query generation strategies affect news verification and whether the way people search influences the accuracy of their information evaluation. A mixed-methods approach was used, consisting of three parts: (1) an analysis of existing data to understand how search behaviour influences trust in fake news, (2) a simulation of query generation strategies using a Large Language Model (LLM) to assess the impact of different query formulations on search result quality, and (3) a user study to examine how 'Boost' interventions in interface design can guide users to adopt more effective query strategies. The results show that search behaviour significantly affects trust in news, with successful searches involving multiple queries and yielding higher-quality results. Queries inspired by different parts of a news article produced search results of varying quality, and weak initial queries improved when reformulated using full SERP information. Although 'Boost' interventions had limited impact, the study suggests that interface design encouraging users to thoroughly review search results can enhance query formulation. This study highlights the importance of query strategies in evaluating news and proposes that interface design can play a key role in promoting more effective search practices, serving as one component of a broader set of interventions to combat misinformation.
Use Me Wisely: AI-Driven Assessment for LLM Prompting Skills Development
Mar 04, 2025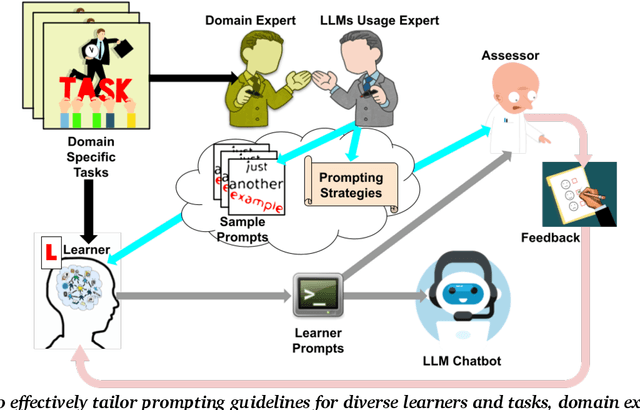
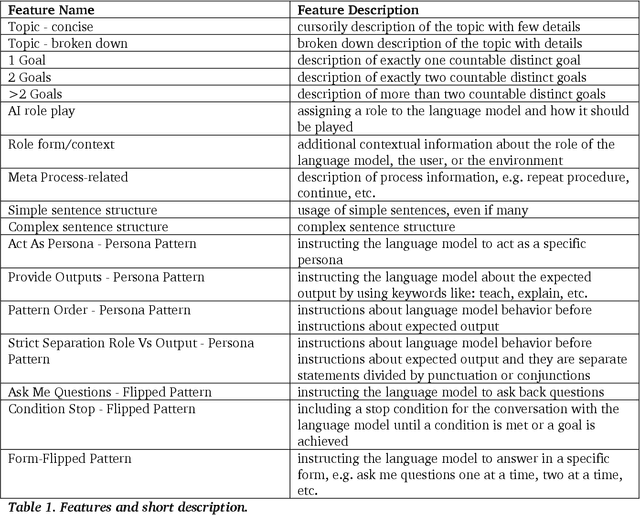
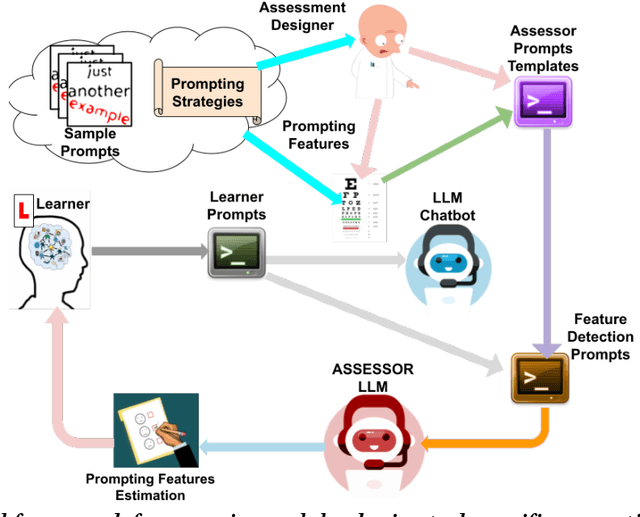
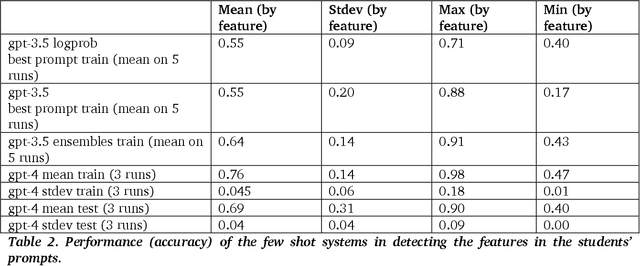
The use of large language model (LLM)-powered chatbots, such as ChatGPT, has become popular across various domains, supporting a range of tasks and processes. However, due to the intrinsic complexity of LLMs, effective prompting is more challenging than it may seem. This highlights the need for innovative educational and support strategies that are both widely accessible and seamlessly integrated into task workflows. Yet, LLM prompting is highly task- and domain-dependent, limiting the effectiveness of generic approaches. In this study, we explore whether LLM-based methods can facilitate learning assessments by using ad-hoc guidelines and a minimal number of annotated prompt samples. Our framework transforms these guidelines into features that can be identified within learners' prompts. Using these feature descriptions and annotated examples, we create few-shot learning detectors. We then evaluate different configurations of these detectors, testing three state-of-the-art LLMs and ensembles. We run experiments with cross-validation on a sample of original prompts, as well as tests on prompts collected from task-naive learners. Our results show how LLMs perform on feature detection. Notably, GPT- 4 demonstrates strong performance on most features, while closely related models, such as GPT-3 and GPT-3.5 Turbo (Instruct), show inconsistent behaviors in feature classification. These differences highlight the need for further research into how design choices impact feature selection and prompt detection. Our findings contribute to the fields of generative AI literacy and computer-supported learning assessment, offering valuable insights for both researchers and practitioners.
Token-Level Graphs for Short Text Classification
Dec 17, 2024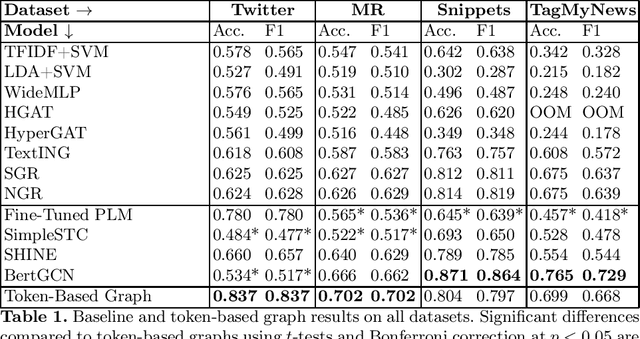
The classification of short texts is a common subtask in Information Retrieval (IR). Recent advances in graph machine learning have led to interest in graph-based approaches for low resource scenarios, showing promise in such settings. However, existing methods face limitations such as not accounting for different meanings of the same words or constraints from transductive approaches. We propose an approach which constructs text graphs entirely based on tokens obtained through pre-trained language models (PLMs). By applying a PLM to tokenize and embed the texts when creating the graph(-nodes), our method captures contextual and semantic information, overcomes vocabulary constraints, and allows for context-dependent word meanings. Our approach also makes classification more efficient with reduced parameters compared to classical PLM fine-tuning, resulting in more robust training with few samples. Experimental results demonstrate how our method consistently achieves higher scores or on-par performance with existing methods, presenting an advancement in graph-based text classification techniques. To support reproducibility of our work we make all implementations publicly available to the community\footnote{\url{https://github.com/doGregor/TokenGraph}}.
Modeling Social Media Recommendation Impacts Using Academic Networks: A Graph Neural Network Approach
Oct 06, 2024The widespread use of social media has highlighted potential negative impacts on society and individuals, largely driven by recommendation algorithms that shape user behavior and social dynamics. Understanding these algorithms is essential but challenging due to the complex, distributed nature of social media networks as well as limited access to real-world data. This study proposes to use academic social networks as a proxy for investigating recommendation systems in social media. By employing Graph Neural Networks (GNNs), we develop a model that separates the prediction of academic infosphere from behavior prediction, allowing us to simulate recommender-generated infospheres and assess the model's performance in predicting future co-authorships. Our approach aims to improve our understanding of recommendation systems' roles and social networks modeling. To support the reproducibility of our work we publicly make available our implementations: https://github.com/DimNeuroLab/academic_network_project
Challenges in Pre-Training Graph Neural Networks for Context-Based Fake News Detection: An Evaluation of Current Strategies and Resource Limitations
Feb 28, 2024Pre-training of neural networks has recently revolutionized the field of Natural Language Processing (NLP) and has before demonstrated its effectiveness in computer vision. At the same time, advances around the detection of fake news were mainly driven by the context-based paradigm, where different types of signals (e.g. from social media) form graph-like structures that hold contextual information apart from the news article to classify. We propose to merge these two developments by applying pre-training of Graph Neural Networks (GNNs) in the domain of context-based fake news detection. Our experiments provide an evaluation of different pre-training strategies for graph-based misinformation detection and demonstrate that transfer learning does currently not lead to significant improvements over training a model from scratch in the domain. We argue that a major current issue is the lack of suitable large-scale resources that can be used for pre-training.
Learning to Prompt in the Classroom to Understand AI Limits: A pilot study
Jul 04, 2023Artificial intelligence's progress holds great promise in assisting society in addressing pressing societal issues. In particular Large Language Models (LLM) and the derived chatbots, like ChatGPT, have highly improved the natural language processing capabilities of AI systems allowing them to process an unprecedented amount of unstructured data. The consequent hype has also backfired, raising negative sentiment even after novel AI methods' surprising contributions. One of the causes, but also an important issue per se, is the rising and misleading feeling of being able to access and process any form of knowledge to solve problems in any domain with no effort or previous expertise in AI or problem domain, disregarding current LLMs limits, such as hallucinations and reasoning limits. Acknowledging AI fallibility is crucial to address the impact of dogmatic overconfidence in possibly erroneous suggestions generated by LLMs. At the same time, it can reduce fear and other negative attitudes toward AI. AI literacy interventions are necessary that allow the public to understand such LLM limits and learn how to use them in a more effective manner, i.e. learning to "prompt". With this aim, a pilot educational intervention was performed in a high school with 30 students. It involved (i) presenting high-level concepts about intelligence, AI, and LLM, (ii) an initial naive practice with ChatGPT in a non-trivial task, and finally (iii) applying currently-accepted prompting strategies. Encouraging preliminary results have been collected such as students reporting a) high appreciation of the activity, b) improved quality of the interaction with the LLM during the educational activity, c) decreased negative sentiments toward AI, d) increased understanding of limitations and specifically We aim to study factors that impact AI acceptance and to refine and repeat this activity in more controlled settings.