 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Questions to Trust Reports: A LLM-IR Framework for the TREC 2025 DRAGUN Track
Mar 24, 2026The DRAGUN Track at TREC 2025 targets the growing need for effective support tools that help users evaluate the trustworthiness of online news. We describe the UR_Trecking system submitted for both Task 1 (critical question generation) and Task 2 (retrieval-augmented trustworthiness reporting). Our approach combines LLM-based question generation with semantic filtering, diversity enforcement using clustering, and several query expansion strategies (including reasoning-based Chain-of-Thought expansion) to retrieve relevant evidence from the MS MARCO V2.1 segmented corpus. Retrieved documents are re-ranked using a monoT5 model and filtered using an LLM relevance judge together with a domain-level trustworthiness dataset. For Task 2, selected evidence is synthesized by an LLM into concise trustworthiness reports with citations. Results from the official evaluation indicate that Chain-of-Thought query expansion and re-ranking substantially improve both relevance and domain trust compared to baseline retrieval, while question-generation performance shows moderate quality with room for improvement. We conclude by outlining key challenges encountered and suggesting directions for enhancing robustness and trustworthiness assessment in future iterations of the system.
MedNuggetizer: Confidence-Based Information Nugget Extraction from Medical Documents
Dec 17, 2025We present MedNuggetizer, https://mednugget-ai.de/; access is available upon request.}, a tool for query-driven extraction and clustering of information nuggets from medical documents to support clinicians in exploring underlying medical evidence. Backed by a large language model (LLM), \textit{MedNuggetizer} performs repeated extractions of information nuggets that are then grouped to generate reliable evidence within and across multiple documents. We demonstrate its utility on the clinical use case of \textit{antibiotic prophylaxis before prostate biopsy} by using major urological guidelines and recent PubMed studies as sources of information. Evaluation by domain experts shows that \textit{MedNuggetizer} provides clinicians and researchers with an efficient way to explore long documents and easily extract reliable, query-focused medical evidence.
Can Language Models Critique Themselves? Investigating Self-Feedback for Retrieval Augmented Generation at BioASQ 2025
Aug 07, 2025Agentic Retrieval Augmented Generation (RAG) and 'deep research' systems aim to enable autonomous search processes where Large Language Models (LLMs) iteratively refine outputs. However, applying these systems to domain-specific professional search, such as biomedical research, presents challenges, as automated systems may reduce user involvement and misalign with expert information needs. Professional search tasks often demand high levels of user expertise and transparency. The BioASQ CLEF 2025 challenge, using expert-formulated questions, can serve as a platform to study these issues. We explored the performance of current reasoning and nonreasoning LLMs like Gemini-Flash 2.0, o3-mini, o4-mini and DeepSeek-R1. A key aspect of our methodology was a self-feedback mechanism where LLMs generated, evaluated, and then refined their outputs for query expansion and for multiple answer types (yes/no, factoid, list, ideal). We investigated whether this iterative self-correction improves performance and if reasoning models are more capable of generating useful feedback. Preliminary results indicate varied performance for the self-feedback strategy across models and tasks. This work offers insights into LLM self-correction and informs future work on comparing the effectiveness of LLM-generated feedback with direct human expert input in these search systems.
Query Smarter, Trust Better? Exploring Search Behaviours for Verifying News Accuracy
Apr 07, 2025



While it is often assumed that searching for information to evaluate misinformation will help identify false claims, recent work suggests that search behaviours can instead reinforce belief in misleading news, particularly when users generate queries using vocabulary from the source articles. Our research explores how different query generation strategies affect news verification and whether the way people search influences the accuracy of their information evaluation. A mixed-methods approach was used, consisting of three parts: (1) an analysis of existing data to understand how search behaviour influences trust in fake news, (2) a simulation of query generation strategies using a Large Language Model (LLM) to assess the impact of different query formulations on search result quality, and (3) a user study to examine how 'Boost' interventions in interface design can guide users to adopt more effective query strategies. The results show that search behaviour significantly affects trust in news, with successful searches involving multiple queries and yielding higher-quality results. Queries inspired by different parts of a news article produced search results of varying quality, and weak initial queries improved when reformulated using full SERP information. Although 'Boost' interventions had limited impact, the study suggests that interface design encouraging users to thoroughly review search results can enhance query formulation. This study highlights the importance of query strategies in evaluating news and proposes that interface design can play a key role in promoting more effective search practices, serving as one component of a broader set of interventions to combat misinformation.
BioRAGent: A Retrieval-Augmented Generation System for Showcasing Generative Query Expansion and Domain-Specific Search for Scientific Q&A
Dec 16, 2024We present BioRAGent, an interactive web-based retrieval-augmented generation (RAG) system for biomedical question answering. The system uses large language models (LLMs) for query expansion, snippet extraction, and answer generation while maintaining transparency through citation links to the source documents and displaying generated queries for further editing. Building on our successful participation in the BioASQ 2024 challenge, we demonstrate how few-shot learning with LLMs can be effectively applied for a professional search setting. The system supports both direct short paragraph style responses and responses with inline citations. Our demo is available online, and the source code is publicly accessible through GitHub.
Can Open-Source LLMs Compete with Commercial Models? Exploring the Few-Shot Performance of Current GPT Models in Biomedical Tasks
Jul 18, 2024Commercial large language models (LLMs), like OpenAI's GPT-4 powering ChatGPT and Anthropic's Claude 3 Opus, have dominated natural language processing (NLP) benchmarks across different domains. New competing Open-Source alternatives like Mixtral 8x7B or Llama 3 have emerged and seem to be closing the gap while often offering higher throughput and being less costly to use. Open-Source LLMs can also be self-hosted, which makes them interesting for enterprise and clinical use cases where sensitive data should not be processed by third parties. We participated in the 12th BioASQ challenge, which is a retrieval augmented generation (RAG) setting, and explored the performance of current GPT models Claude 3 Opus, GPT-3.5-turbo and Mixtral 8x7b with in-context learning (zero-shot, few-shot) and QLoRa fine-tuning. We also explored how additional relevant knowledge from Wikipedia added to the context-window of the LLM might improve their performance. Mixtral 8x7b was competitive in the 10-shot setting, both with and without fine-tuning, but failed to produce usable results in the zero-shot setting. QLoRa fine-tuning and Wikipedia context did not lead to measurable performance gains. Our results indicate that the performance gap between commercial and open-source models in RAG setups exists mainly in the zero-shot setting and can be closed by simply collecting few-shot examples for domain-specific use cases. The code needed to rerun these experiments is available through GitHub.
Is ChatGPT a Biomedical Expert? -- Exploring the Zero-Shot Performance of Current GPT Models in Biomedical Tasks
Jun 28, 2023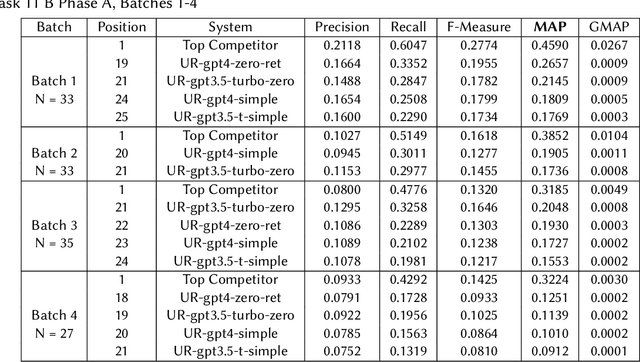
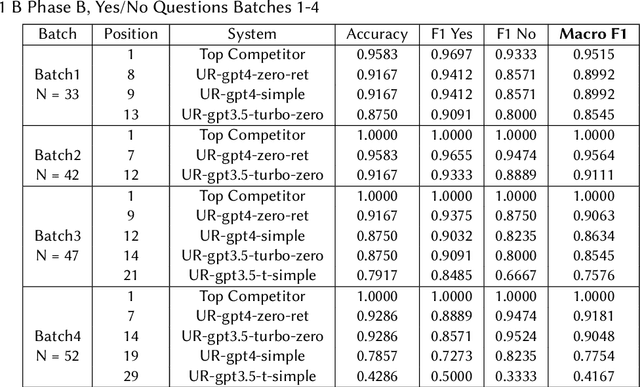
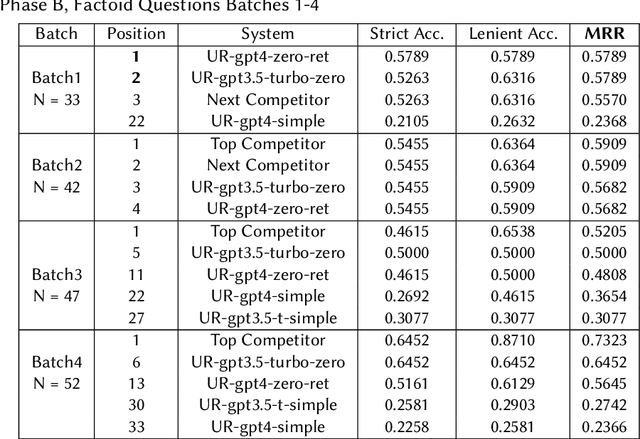
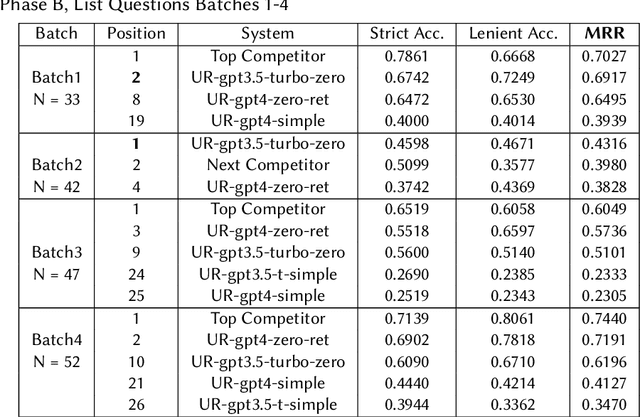
We assessed the performance of commercial Large Language Models (LLMs) GPT-3.5-Turbo and GPT-4 on tasks from the 2023 BioASQ challenge. In Task 11b Phase B, which is focused on answer generation, both models demonstrated competitive abilities with leading systems. Remarkably, they achieved this with simple zero-shot learning, grounded with relevant snippets. Even without relevant snippets, their performance was decent, though not on par with the best systems. Interestingly, the older and cheaper GPT-3.5-Turbo system was able to compete with GPT-4 in the grounded Q&A setting on factoid and list answers. In Task 11b Phase A, focusing on retrieval, query expansion through zero-shot learning improved performance, but the models fell short compared to other systems. The code needed to rerun these experiments is available through GitHub.