 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRules, Resources, and Restrictions: A Taxonomy of Task-Based Information Request Intents
Jan 19, 2026Understanding and classifying query intents can improve retrieval effectiveness by helping align search results with the motivations behind user queries. However, existing intent taxonomies are typically derived from system log data and capture mostly isolated information needs, while the broader task context often remains unaddressed. This limitation becomes increasingly relevant as interactions with Large Language Models (LLMs) expand user expectations from simple query answering toward comprehensive task support, for example, with purchasing decisions or in travel planning. At the same time, current LLMs still struggle to fully interpret complex and multifaceted tasks. To address this gap, we argue for a stronger task-based perspective on query intent. Drawing on a grounded-theory-based interview study with airport information clerks, we present a taxonomy of task-based information request intents that bridges the gap between traditional query-focused approaches and the emerging demands of AI-driven task-oriented search.
Seek and You Shall Find: Design & Evaluation of a Context-Aware Interactive Search Companion
Jan 16, 2026Many users struggle with effective online search and critical evaluation, especially in high-stakes domains like health, while often overestimating their digital literacy. Thus, in this demo, we present an interactive search companion that seamlessly integrates expert search strategies into existing search engine result pages. Providing context-aware tips on clarifying information needs, improving query formulation, encouraging result exploration, and mitigating biases, our companion aims to foster reflective search behaviour while minimising cognitive burden. A user study demonstrates the companion's successful encouragement of more active and exploratory search, leading users to submit 75 % more queries and view roughly twice as many results, as well as performance gains in difficult tasks. This demo illustrates how lightweight, contextual guidance can enhance search literacy and empower users through micro-learning opportunities. While the vision involves real-time LLM adaptivity, this study utilises a controlled implementation to test the underlying intervention strategies.
"Can You Tell Me?": Designing Copilots to Support Human Judgement in Online Information Seeking
Jan 16, 2026Generative AI (GenAI) tools are transforming information seeking, but their fluent, authoritative responses risk overreliance and discourage independent verification and reasoning. Rather than replacing the cognitive work of users, GenAI systems should be designed to support and scaffold it. Therefore, this paper introduces an LLM-based conversational copilot designed to scaffold information evaluation rather than provide answers and foster digital literacy skills. In a pre-registered, randomised controlled trial (N=261) examining three interface conditions including a chat-based copilot, our mixed-methods analysis reveals that users engaged deeply with the copilot, demonstrating metacognitive reflection. However, the copilot did not significantly improve answer correctness or search engagement, largely due to a "time-on-chat vs. exploration" trade-off and users' bias toward positive information. Qualitative findings reveal tension between the copilot's Socratic approach and users' desire for efficiency. These results highlight both the promise and pitfalls of pedagogical copilots, and we outline design pathways to reconcile literacy goals with efficiency demands.
From Tool to Teacher: Rethinking Search Systems as Instructive Interfaces
Jan 12, 2026Information access systems such as search engines and generative AI are central to how people seek, evaluate, and interpret information. Yet most systems are designed to optimise retrieval rather than to help users develop better search strategies or critical awareness. This paper introduces a pedagogical perspective on information access, conceptualising search and conversational systems as instructive interfaces that can teach, guide, and scaffold users' learning. We draw on seven didactic frameworks from education and behavioural science to analyse how existing and emerging system features, including query suggestions, source labels, and conversational or agentic AI, support or limit user learning. Using two illustrative search tasks, we demonstrate how different design choices promote skills such as critical evaluation, metacognitive reflection, and strategy transfer. The paper contributes a conceptual lens for evaluating the instructional value of information access systems and outlines design implications for technologies that foster more effective, reflective, and resilient information seekers.
Blending Queries and Conversations: Understanding Tactics, Trust, Verification, and System Choice in Web Search and Chat Interactions
Apr 07, 2025



This paper presents a user study (N=22) where participants used an interface combining Web Search and a Generative AI-Chat feature to solve health-related information tasks. We study how people behaved with the interface, why they behaved in certain ways, and what the outcomes of these behaviours were. A think-aloud protocol captured their thought processes during searches. Our findings suggest that GenAI is neither a search panacea nor a major regression compared to standard Web Search interfaces. Qualitative and quantitative analyses identified 78 tactics across five categories and provided insight into how and why different interface features were used. We find evidence that pre-task confidence and trust both influenced which interface feature was used. In both systems, but particularly when using the chat feature, trust was often misplaced in favour of ease-of-use and seemingly perfect answers, leading to increased confidence post-search despite having incorrect results. We discuss what our findings mean in the context of our defined research questions and outline several open questions for future research.
Query Smarter, Trust Better? Exploring Search Behaviours for Verifying News Accuracy
Apr 07, 2025



While it is often assumed that searching for information to evaluate misinformation will help identify false claims, recent work suggests that search behaviours can instead reinforce belief in misleading news, particularly when users generate queries using vocabulary from the source articles. Our research explores how different query generation strategies affect news verification and whether the way people search influences the accuracy of their information evaluation. A mixed-methods approach was used, consisting of three parts: (1) an analysis of existing data to understand how search behaviour influences trust in fake news, (2) a simulation of query generation strategies using a Large Language Model (LLM) to assess the impact of different query formulations on search result quality, and (3) a user study to examine how 'Boost' interventions in interface design can guide users to adopt more effective query strategies. The results show that search behaviour significantly affects trust in news, with successful searches involving multiple queries and yielding higher-quality results. Queries inspired by different parts of a news article produced search results of varying quality, and weak initial queries improved when reformulated using full SERP information. Although 'Boost' interventions had limited impact, the study suggests that interface design encouraging users to thoroughly review search results can enhance query formulation. This study highlights the importance of query strategies in evaluating news and proposes that interface design can play a key role in promoting more effective search practices, serving as one component of a broader set of interventions to combat misinformation.
"You tell me": A Dataset of GPT-4-Based Behaviour Change Support Conversations
Jan 29, 2024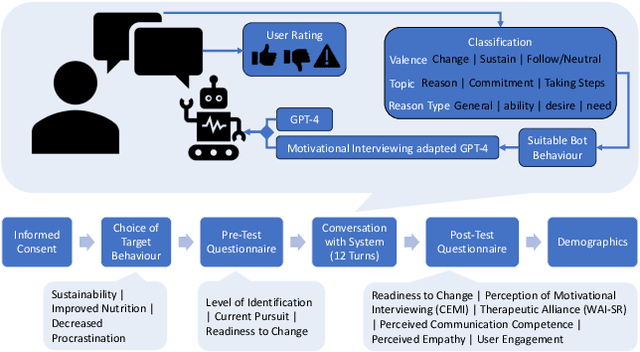

Conversational agents are increasingly used to address emotional needs on top of information needs. One use case of increasing interest are counselling-style mental health and behaviour change interventions, with large language model (LLM)-based approaches becoming more popular. Research in this context so far has been largely system-focused, foregoing the aspect of user behaviour and the impact this can have on LLM-generated texts. To address this issue, we share a dataset containing text-based user interactions related to behaviour change with two GPT-4-based conversational agents collected in a preregistered user study. This dataset includes conversation data, user language analysis, perception measures, and user feedback for LLM-generated turns, and can offer valuable insights to inform the design of such systems based on real interactions.
"What can I cook with these ingredients?" -- Understanding cooking-related information needs in conversational search
Dec 10, 2021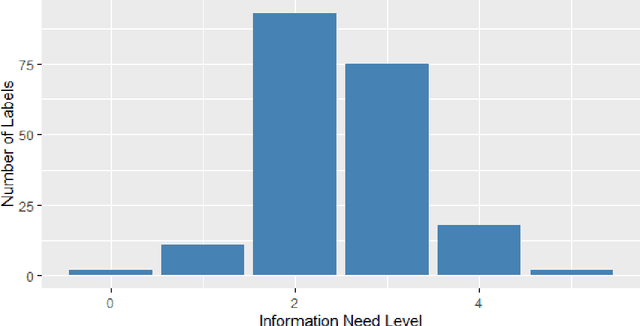
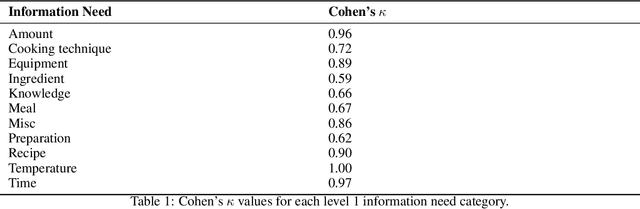

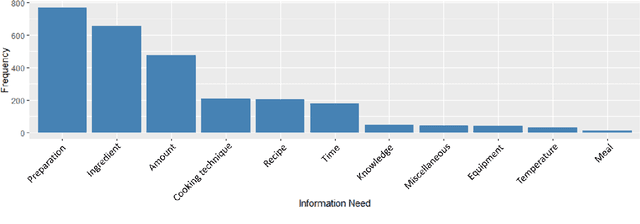
As conversational search becomes more pervasive, it becomes increasingly important to understand the user's underlying information needs when they converse with such systems in diverse domains. We conduct an in-situ study to understand information needs arising in a home cooking context as well as how they are verbally communicated to an assistant. A human experimenter plays this role in our study. Based on the transcriptions of utterances, we derive a detailed hierarchical taxonomy of diverse information needs occurring in this context, which require different levels of assistance to be solved. The taxonomy shows that needs can be communicated through different linguistic means and require different amounts of context to be understood. In a second contribution we perform classification experiments to determine the feasibility of predicting the type of information need a user has during a dialogue using the turn provided. For this multi-label classification problem, we achieve average F1 measures of 40% using BERT-based models. We demonstrate with examples, which types of need are difficult to predict and show why, concluding that models need to include more context information in order to improve both information need classification and assistance to make such systems usable.