 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Level Graphs for Short Text Classification
Paper and Code
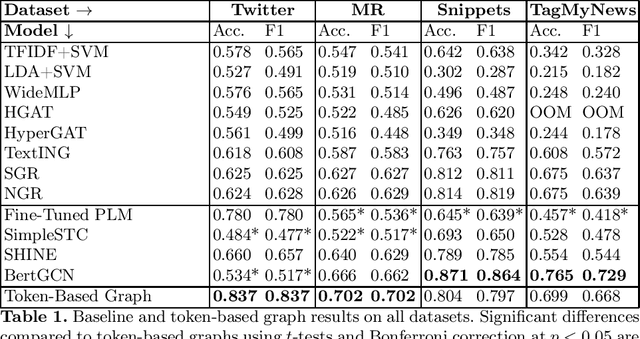
The classification of short texts is a common subtask in Information Retrieval (IR). Recent advances in graph machine learning have led to interest in graph-based approaches for low resource scenarios, showing promise in such settings. However, existing methods face limitations such as not accounting for different meanings of the same words or constraints from transductive approaches. We propose an approach which constructs text graphs entirely based on tokens obtained through pre-trained language models (PLMs). By applying a PLM to tokenize and embed the texts when creating the graph(-nodes), our method captures contextual and semantic information, overcomes vocabulary constraints, and allows for context-dependent word meanings. Our approach also makes classification more efficient with reduced parameters compared to classical PLM fine-tuning, resulting in more robust training with few samples. Experimental results demonstrate how our method consistently achieves higher scores or on-par performance with existing methods, presenting an advancement in graph-based text classification techniques. To support reproducibility of our work we make all implementations publicly available to the community\footnote{\url{https://github.com/doGregor/TokenGraph}}.