 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUse Me Wisely: AI-Driven Assessment for LLM Prompting Skills Development
Paper and Code
Mar 04, 2025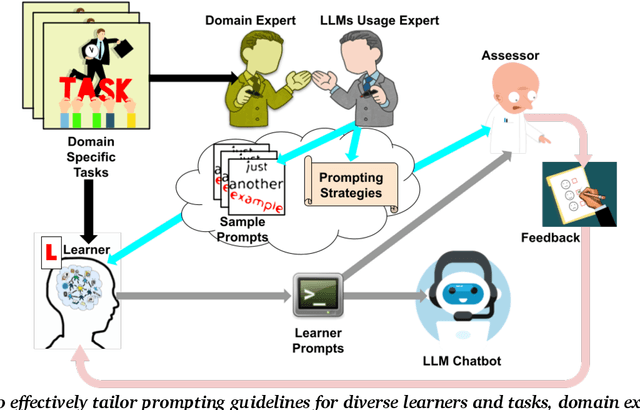
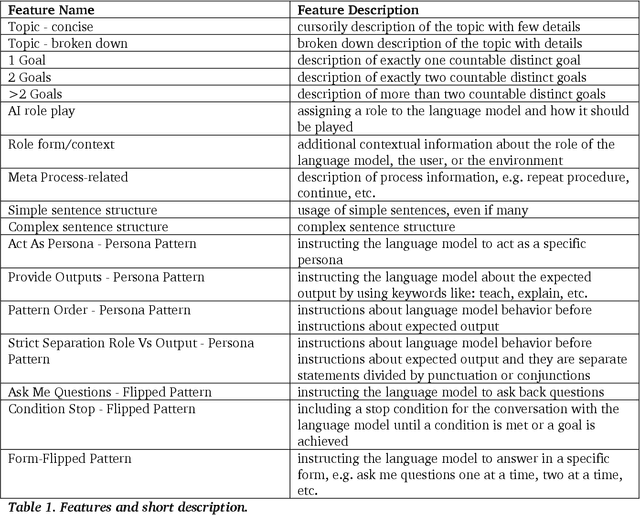
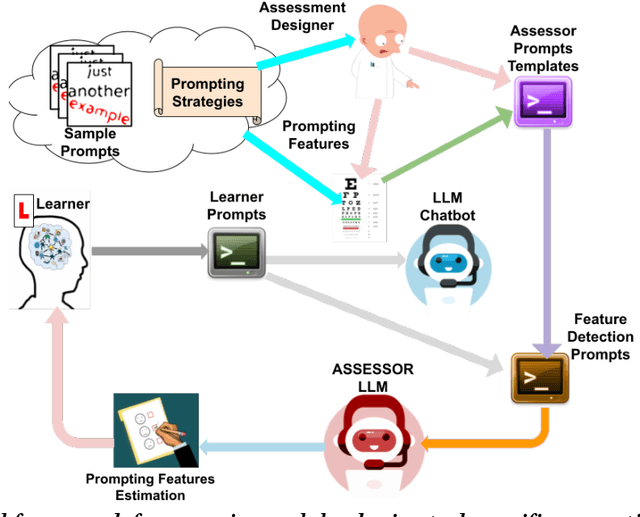
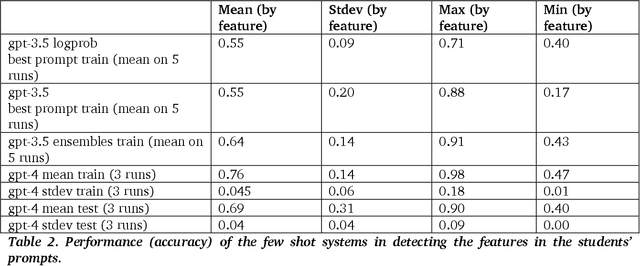
The use of large language model (LLM)-powered chatbots, such as ChatGPT, has become popular across various domains, supporting a range of tasks and processes. However, due to the intrinsic complexity of LLMs, effective prompting is more challenging than it may seem. This highlights the need for innovative educational and support strategies that are both widely accessible and seamlessly integrated into task workflows. Yet, LLM prompting is highly task- and domain-dependent, limiting the effectiveness of generic approaches. In this study, we explore whether LLM-based methods can facilitate learning assessments by using ad-hoc guidelines and a minimal number of annotated prompt samples. Our framework transforms these guidelines into features that can be identified within learners' prompts. Using these feature descriptions and annotated examples, we create few-shot learning detectors. We then evaluate different configurations of these detectors, testing three state-of-the-art LLMs and ensembles. We run experiments with cross-validation on a sample of original prompts, as well as tests on prompts collected from task-naive learners. Our results show how LLMs perform on feature detection. Notably, GPT- 4 demonstrates strong performance on most features, while closely related models, such as GPT-3 and GPT-3.5 Turbo (Instruct), show inconsistent behaviors in feature classification. These differences highlight the need for further research into how design choices impact feature selection and prompt detection. Our findings contribute to the fields of generative AI literacy and computer-supported learning assessment, offering valuable insights for both researchers and practitioners.