 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Model Prior Overcomes Cold-Start Items
Nov 13, 2024
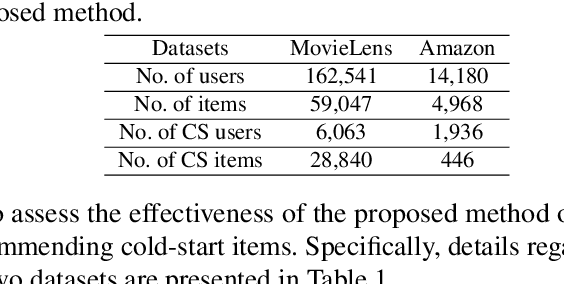
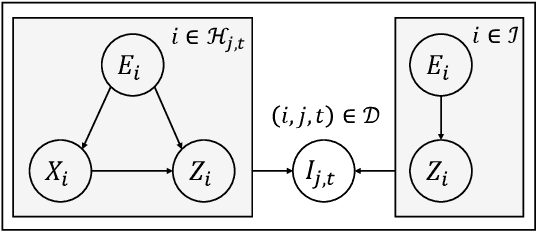

The growth of recommender systems (RecSys) is driven by digitization and the need for personalized content in areas such as e-commerce and video streaming. The content in these systems often changes rapidly and therefore they constantly face the ongoing cold-start problem, where new items lack interaction data and are hard to value. Existing solutions for the cold-start problem, such as content-based recommenders and hybrid methods, leverage item metadata to determine item similarities. The main challenge with these methods is their reliance on structured and informative metadata to capture detailed item similarities, which may not always be available. This paper introduces a novel approach for cold-start item recommendation that utilizes the language model (LM) to estimate item similarities, which are further integrated as a Bayesian prior with classic recommender systems. This approach is generic and able to boost the performance of various recommenders. Specifically, our experiments integrate it with both sequential and collaborative filtering-based recommender and evaluate it on two real-world datasets, demonstrating the enhanced performance of the proposed approach.
Every Preference Changes Differently: Neural Multi-Interest Preference Model with Temporal Dynamics for Recommendation
Jul 21, 2022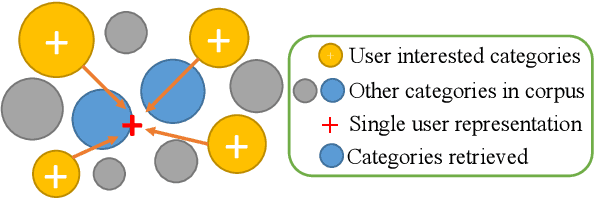

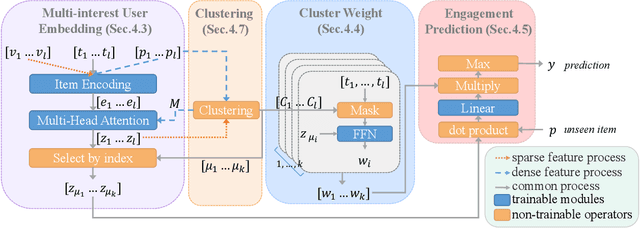
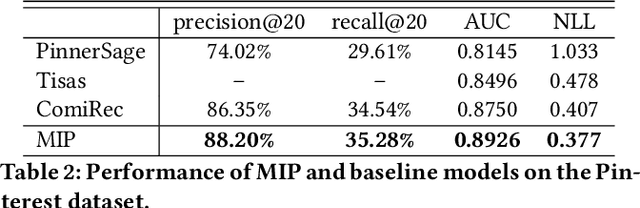
User embeddings (vectorized representations of a user) are essential in recommendation systems. Numerous approaches have been proposed to construct a representation for the user in order to find similar items for retrieval tasks, and they have been proven effective in industrial recommendation systems as well. Recently people have discovered the power of using multiple embeddings to represent a user, with the hope that each embedding represents the user's interest in a certain topic. With multi-interest representation, it's important to model the user's preference over the different topics and how the preference change with time. However, existing approaches either fail to estimate the user's affinity to each interest or unreasonably assume every interest of every user fades with an equal rate with time, thus hurting the recall of candidate retrieval. In this paper, we propose the Multi-Interest Preference (MIP) model, an approach that not only produces multi-interest for users by using the user's sequential engagement more effectively but also automatically learns a set of weights to represent the preference over each embedding so that the candidates can be retrieved from each interest proportionally. Extensive experiments have been done on various industrial-scale datasets to demonstrate the effectiveness of our approach.