 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning fMRI activations dictionaries across individual geometries via optimal transport
May 20, 2026Dictionary learning is a powerful tool for creating interpretable representations. When applied to functional magnetic resonance imaging (fMRI) data, the resulting patterns of brain activity can be used for various downstream tasks, such as brain state classification or population-level analysis. However, a major challenge is the variability in brain geometry across individuals. This is usually addressed by projecting each individual brain geometry onto a common template, which removes subject-specific information. In this work, we introduce a novel approach to dictionary learning on fMRI data that explicitly accounts for this variability. We use the optimal transport-based Fused Gromov-Wasserstein (FGW) distance to compare graphs with different geometries and features. To address the challenge of computing multiple FGW distances for large graphs such as those arising from fMRI data, we rely on amortized optimization to learn a neural network that predicts an approximation of the optimal transport plans, which substantially reduces the computational cost. Additionally, we learn dictionary atoms that depend on the FGW trade-off parameter, which controls the balance between feature alignment and structural consistency. Numerical experiments on the HCP dataset demonstrate that the proposed approach captures different levels of geometric variability in the data and provides representations that preserve essential information.
SPD Learn: A Geometric Deep Learning Python Library for Neural Decoding Through Trivialization
Feb 26, 2026Implementations of symmetric positive definite (SPD) matrix-based neural networks for neural decoding remain fragmented across research codebases and Python packages. Existing implementations often employ ad hoc handling of manifold constraints and non-unified training setups, which hinders reproducibility and integration into modern deep-learning workflows. To address this gap, we introduce SPD Learn, a unified and modular Python package for geometric deep learning with SPD matrices. SPD Learn provides core SPD operators and neural-network layers, including numerically stable spectral operators, and enforces Stiefel/SPD constraints via trivialization-based parameterizations. This design enables standard backpropagation and optimization in unconstrained Euclidean spaces while producing manifold-constrained parameters by construction. The package also offers reference implementations of representative SPDNet-based models and interfaces with widely used brain computer interface/neuroimaging toolkits and modern machine-learning libraries (e.g., MOABB, Braindecode, Nilearn, and SKADA), facilitating reproducible benchmarking and practical deployment.
GICDM: Mitigating Hubness for Reliable Distance-Based Generative Model Evaluation
Feb 18, 2026Generative model evaluation commonly relies on high-dimensional embedding spaces to compute distances between samples. We show that dataset representations in these spaces are affected by the hubness phenomenon, which distorts nearest neighbor relationships and biases distance-based metrics. Building on the classical Iterative Contextual Dissimilarity Measure (ICDM), we introduce Generative ICDM (GICDM), a method to correct neighborhood estimation for both real and generated data. We introduce a multi-scale extension to improve empirical behavior. Extensive experiments on synthetic and real benchmarks demonstrate that GICDM resolves hubness-induced failures, restores reliable metric behavior, and improves alignment with human judgment.
Aggregate Models, Not Explanations: Improving Feature Importance Estimation
Feb 12, 2026Feature-importance methods show promise in transforming machine learning models from predictive engines into tools for scientific discovery. However, due to data sampling and algorithmic stochasticity, expressive models can be unstable, leading to inaccurate variable importance estimates and undermining their utility in critical biomedical applications. Although ensembling offers a solution, deciding whether to explain a single ensemble model or aggregate individual model explanations is difficult due to the nonlinearity of importance measures and remains largely understudied. Our theoretical analysis, developed under assumptions accommodating complex state-of-the-art ML models, reveals that this choice is primarily driven by the model's excess risk. In contrast to prior literature, we show that ensembling at the model level provides more accurate variable-importance estimates, particularly for expressive models, by reducing this leading error term. We validate these findings on classical benchmarks and a large-scale proteomic study from the UK Biobank.
Hierarchical Variable Importance with Statistical Control for Medical Data-Based Prediction
Aug 12, 2025Recent advances in machine learning have greatly expanded the repertoire of predictive methods for medical imaging. However, the interpretability of complex models remains a challenge, which limits their utility in medical applications. Recently, model-agnostic methods have been proposed to measure conditional variable importance and accommodate complex non-linear models. However, they often lack power when dealing with highly correlated data, a common problem in medical imaging. We introduce Hierarchical-CPI, a model-agnostic variable importance measure that frames the inference problem as the discovery of groups of variables that are jointly predictive of the outcome. By exploring subgroups along a hierarchical tree, it remains computationally tractable, yet also enjoys explicit family-wise error rate control. Moreover, we address the issue of vanishing conditional importance under high correlation with a tree-based importance allocation mechanism. We benchmarked Hierarchical-CPI against state-of-the-art variable importance methods. Its effectiveness is demonstrated in two neuroimaging datasets: classifying dementia diagnoses from MRI data (ADNI dataset) and analyzing the Berger effect on EEG data (TDBRAIN dataset), identifying biologically plausible variables.
Enhanced Generative Model Evaluation with Clipped Density and Coverage
Jul 02, 2025



Although generative models have made remarkable progress in recent years, their use in critical applications has been hindered by their incapacity to reliably evaluate sample quality. Quality refers to at least two complementary concepts: fidelity and coverage. Current quality metrics often lack reliable, interpretable values due to an absence of calibration or insufficient robustness to outliers. To address these shortcomings, we introduce two novel metrics, Clipped Density and Clipped Coverage. By clipping individual sample contributions and, for fidelity, the radii of nearest neighbor balls, our metrics prevent out-of-distribution samples from biasing the aggregated values. Through analytical and empirical calibration, these metrics exhibit linear score degradation as the proportion of poor samples increases. Thus, they can be straightforwardly interpreted as equivalent proportions of good samples. Extensive experiments on synthetic and real-world datasets demonstrate that Clipped Density and Clipped Coverage outperform existing methods in terms of robustness, sensitivity, and interpretability for evaluating generative models.
Optimizing fMRI Data Acquisition for Decoding Natural Speech with Limited Participants
May 27, 2025We investigate optimal strategies for decoding perceived natural speech from fMRI data acquired from a limited number of participants. Leveraging Lebel et al. (2023)'s dataset of 8 participants, we first demonstrate the effectiveness of training deep neural networks to predict LLM-derived text representations from fMRI activity. Then, in this data regime, we observe that multi-subject training does not improve decoding accuracy compared to single-subject approach. Furthermore, training on similar or different stimuli across subjects has a negligible effect on decoding accuracy. Finally, we find that our decoders better model syntactic than semantic features, and that stories containing sentences with complex syntax or rich semantic content are more challenging to decode. While our results demonstrate the benefits of having extensive data per participant (deep phenotyping), they suggest that leveraging multi-subject for natural speech decoding likely requires deeper phenotyping or a substantially larger cohort.
Causal mediation analysis with one or multiple mediators: a comparative study
May 12, 2025Mediation analysis breaks down the causal effect of a treatment on an outcome into an indirect effect, acting through a third group of variables called mediators, and a direct effect, operating through other mechanisms. Mediation analysis is hard because confounders between treatment, mediators, and outcome blur effect estimates in observational studies. Many estimators have been proposed to adjust on those confounders and provide accurate causal estimates. We consider parametric and non-parametric implementations of classical estimators and provide a thorough evaluation for the estimation of the direct and indirect effects in the context of causal mediation analysis for binary, continuous, and multi-dimensional mediators. We assess several approaches in a comprehensive benchmark on simulated data. Our results show that advanced statistical approaches such as the multiply robust and the double machine learning estimators achieve good performances in most of the simulated settings and on real data. As an example of application, we propose a thorough analysis of factors known to influence cognitive functions to assess if the mechanism involves modifications in brain morphology using the UK Biobank brain imaging cohort. This analysis shows that for several physiological factors, such as hypertension and obesity, a substantial part of the effect is mediated by changes in the brain structure. This work provides guidance to the practitioner from the formulation of a valid causal mediation problem, including the verification of the identification assumptions, to the choice of an adequate estimator.
SPD Learning for Covariance-Based Neuroimaging Analysis: Perspectives, Methods, and Challenges
Apr 26, 2025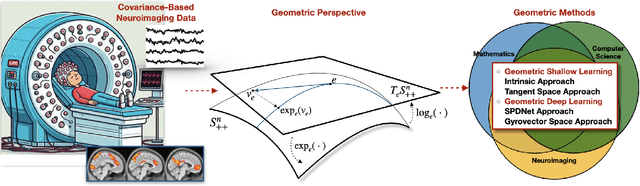

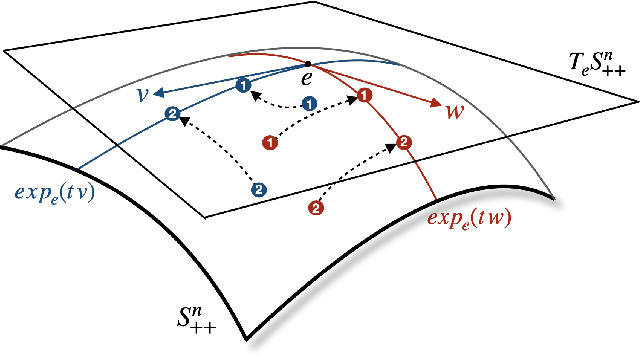
Neuroimaging provides a critical framework for characterizing brain activity by quantifying connectivity patterns and functional architecture across modalities. While modern machine learning has significantly advanced our understanding of neural processing mechanisms through these datasets, decoding task-specific signatures must contend with inherent neuroimaging constraints, for example, low signal-to-noise ratios in raw electrophysiological recordings, cross-session non-stationarity, and limited sample sizes. This review focuses on machine learning approaches for covariance-based neuroimaging data, where often symmetric positive definite (SPD) matrices under full-rank conditions encode inter-channel relationships. By equipping the space of SPD matrices with Riemannian metrics (e.g., affine-invariant or log-Euclidean), their space forms a Riemannian manifold enabling geometric analysis. We unify methodologies operating on this manifold under the SPD learning framework, which systematically leverages the SPD manifold's geometry to process covariance features, thereby advancing brain imaging analytics.
Measuring Variable Importance in Individual Treatment Effect Estimation with High Dimensional Data
Aug 23, 2024Causal machine learning (ML) promises to provide powerful tools for estimating individual treatment effects. Although causal ML methods are now well established, they still face the significant challenge of interpretability, which is crucial for medical applications. In this work, we propose a new algorithm based on the Conditional Permutation Importance (CPI) method for statistically rigorous variable importance assessment in the context of Conditional Average Treatment Effect (CATE) estimation. Our method termed PermuCATE is agnostic to both the meta-learner and the ML model used. Through theoretical analysis and empirical studies, we show that this approach provides a reliable measure of variable importance and exhibits lower variance compared to the standard Leave-One-Covariate-Out (LOCO) method. We illustrate how this property leads to increased statistical power, which is crucial for the application of explainable ML in small sample sizes or high-dimensional settings. We empirically demonstrate the benefits of our approach in various simulation scenarios, including previously proposed benchmarks as well as more complex settings with high-dimensional and correlated variables that require advanced CATE estimators.