 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Brain Context-Sensitivity with Masked-Attention Generation
May 23, 2023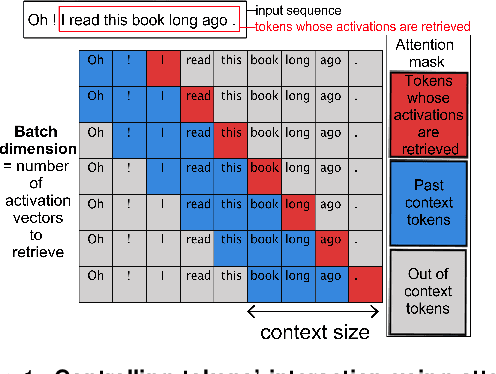
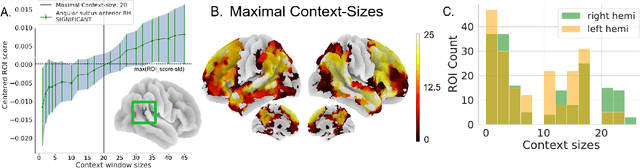
Two fundamental questions in neurolinguistics concerns the brain regions that integrate information beyond the lexical level, and the size of their window of integration. To address these questions we introduce a new approach named masked-attention generation. It uses GPT-2 transformers to generate word embeddings that capture a fixed amount of contextual information. We then tested whether these embeddings could predict fMRI brain activity in humans listening to naturalistic text. The results showed that most of the cortex within the language network is sensitive to contextual information, and that the right hemisphere is more sensitive to longer contexts than the left. Masked-attention generation supports previous analyses of context-sensitivity in the brain, and complements them by quantifying the window size of context integration per voxel.
* 2 pages, 2 figures, CCN 2023
Information-Restricted Neural Language Models Reveal Different Brain Regions' Sensitivity to Semantics, Syntax and Context
Feb 28, 2023A fundamental question in neurolinguistics concerns the brain regions involved in syntactic and semantic processing during speech comprehension, both at the lexical (word processing) and supra-lexical levels (sentence and discourse processing). To what extent are these regions separated or intertwined? To address this question, we trained a lexical language model, Glove, and a supra-lexical language model, GPT-2, on a text corpus from which we selectively removed either syntactic or semantic information. We then assessed to what extent these information-restricted models were able to predict the time-courses of fMRI signal of humans listening to naturalistic text. We also manipulated the size of contextual information provided to GPT-2 in order to determine the windows of integration of brain regions involved in supra-lexical processing. Our analyses show that, while most brain regions involved in language are sensitive to both syntactic and semantic variables, the relative magnitudes of these effects vary a lot across these regions. Furthermore, we found an asymmetry between the left and right hemispheres, with semantic and syntactic processing being more dissociated in the left hemisphere than in the right, and the left and right hemispheres showing respectively greater sensitivity to short and long contexts. The use of information-restricted NLP models thus shed new light on the spatial organization of syntactic processing, semantic processing and compositionality.
Neural Language Models are not Born Equal to Fit Brain Data, but Training Helps
Jul 07, 2022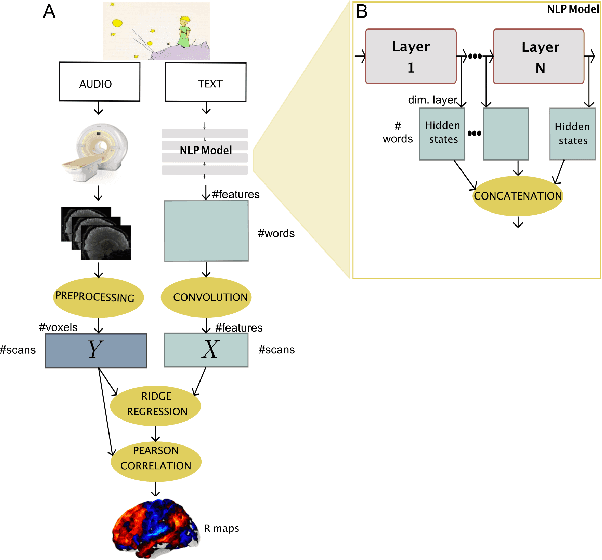
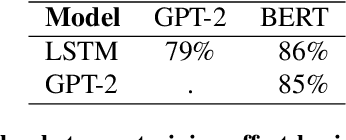
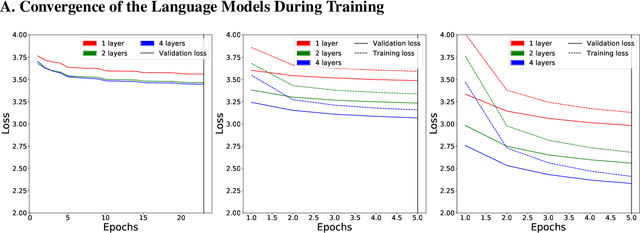
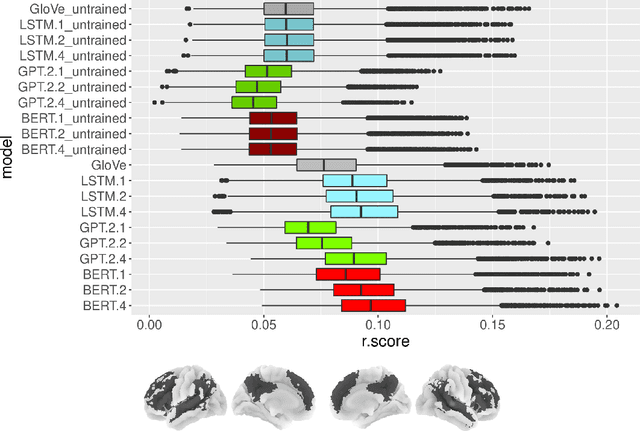
Neural Language Models (NLMs) have made tremendous advances during the last years, achieving impressive performance on various linguistic tasks. Capitalizing on this, studies in neuroscience have started to use NLMs to study neural activity in the human brain during language processing. However, many questions remain unanswered regarding which factors determine the ability of a neural language model to capture brain activity (aka its 'brain score'). Here, we make first steps in this direction and examine the impact of test loss, training corpus and model architecture (comparing GloVe, LSTM, GPT-2 and BERT), on the prediction of functional Magnetic Resonance Imaging timecourses of participants listening to an audiobook. We find that (1) untrained versions of each model already explain significant amount of signal in the brain by capturing similarity in brain responses across identical words, with the untrained LSTM outperforming the transformerbased models, being less impacted by the effect of context; (2) that training NLP models improves brain scores in the same brain regions irrespective of the model's architecture; (3) that Perplexity (test loss) is not a good predictor of brain score; (4) that training data have a strong influence on the outcome and, notably, that off-the-shelf models may lack statistical power to detect brain activations. Overall, we outline the impact of modeltraining choices, and suggest good practices for future studies aiming at explaining the human language system using neural language models.