 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixtureKit: A General Framework for Composing, Training, and Visualizing Mixture-of-Experts Models
Dec 13, 2025We introduce MixtureKit, a modular open-source framework for constructing, training, and analyzing Mixture-of-Experts (MoE) models from arbitrary pre-trained or fine-tuned models. MixtureKit currently supports three complementary methods: (i) \emph{Traditional MoE}, which uses a single router per transformer block to select experts, (ii) \emph{BTX} (Branch-Train-Mix), which introduces separate routers for each specified sub-layer enabling fine-grained token routing, and (iii) \emph{BTS} (Branch-Train-Stitch), which keeps experts fully intact and introduces trainable stitch layers for controlled information exchange between hub and experts. MixtureKit automatically modifies the model configuration, patches decoder and causal LM classes, and saves a unified checkpoint ready for inference or fine-tuning. We further provide a visualization interface to inspect per-token routing decisions, expert weight distributions, and layer-wise contributions. Experiments with multilingual code-switched data (e.g. Arabic-Latin) show that a BTX-based model trained using MixtureKit can outperform baseline dense models on multiple benchmarks. We release MixtureKit as a practical foundation for research and development of MoE-based systems across diverse domains.
Variable Importance in High-Dimensional Settings Requires Grouping
Dec 18, 2023Explaining the decision process of machine learning algorithms is nowadays crucial for both model's performance enhancement and human comprehension. This can be achieved by assessing the variable importance of single variables, even for high-capacity non-linear methods, e.g. Deep Neural Networks (DNNs). While only removal-based approaches, such as Permutation Importance (PI), can bring statistical validity, they return misleading results when variables are correlated. Conditional Permutation Importance (CPI) bypasses PI's limitations in such cases. However, in high-dimensional settings, where high correlations between the variables cancel their conditional importance, the use of CPI as well as other methods leads to unreliable results, besides prohibitive computation costs. Grouping variables statistically via clustering or some prior knowledge gains some power back and leads to better interpretations. In this work, we introduce BCPI (Block-Based Conditional Permutation Importance), a new generic framework for variable importance computation with statistical guarantees handling both single and group cases. Furthermore, as handling groups with high cardinality (such as a set of observations of a given modality) are both time-consuming and resource-intensive, we also introduce a new stacking approach extending the DNN architecture with sub-linear layers adapted to the group structure. We show that the ensuing approach extended with stacking controls the type-I error even with highly-correlated groups and shows top accuracy across benchmarks. Furthermore, we perform a real-world data analysis in a large-scale medical dataset where we aim to show the consistency between our results and the literature for a biomarker prediction.
Statistically Valid Variable Importance Assessment through Conditional Permutations
Sep 14, 2023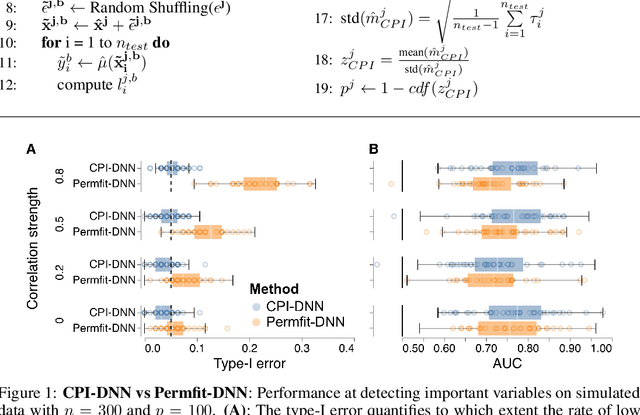
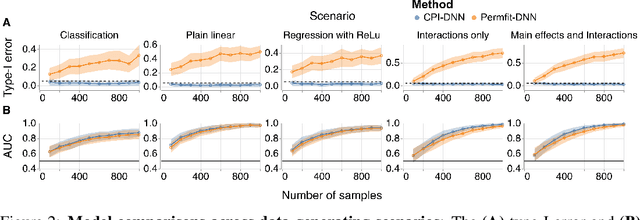

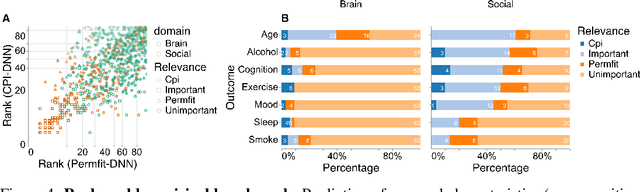
Variable importance assessment has become a crucial step in machine-learning applications when using complex learners, such as deep neural networks, on large-scale data. Removal-based importance assessment is currently the reference approach, particularly when statistical guarantees are sought to justify variable inclusion. It is often implemented with variable permutation schemes. On the flip side, these approaches risk misidentifying unimportant variables as important in the presence of correlations among covariates. Here we develop a systematic approach for studying Conditional Permutation Importance (CPI) that is model agnostic and computationally lean, as well as reusable benchmarks of state-of-the-art variable importance estimators. We show theoretically and empirically that $\textit{CPI}$ overcomes the limitations of standard permutation importance by providing accurate type-I error control. When used with a deep neural network, $\textit{CPI}$ consistently showed top accuracy across benchmarks. An empirical benchmark on real-world data analysis in a large-scale medical dataset showed that $\textit{CPI}$ provides a more parsimonious selection of statistically significant variables. Our results suggest that $\textit{CPI}$ can be readily used as drop-in replacement for permutation-based methods.