 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPD Learn: A Geometric Deep Learning Python Library for Neural Decoding Through Trivialization
Feb 26, 2026Implementations of symmetric positive definite (SPD) matrix-based neural networks for neural decoding remain fragmented across research codebases and Python packages. Existing implementations often employ ad hoc handling of manifold constraints and non-unified training setups, which hinders reproducibility and integration into modern deep-learning workflows. To address this gap, we introduce SPD Learn, a unified and modular Python package for geometric deep learning with SPD matrices. SPD Learn provides core SPD operators and neural-network layers, including numerically stable spectral operators, and enforces Stiefel/SPD constraints via trivialization-based parameterizations. This design enables standard backpropagation and optimization in unconstrained Euclidean spaces while producing manifold-constrained parameters by construction. The package also offers reference implementations of representative SPDNet-based models and interfaces with widely used brain computer interface/neuroimaging toolkits and modern machine-learning libraries (e.g., MOABB, Braindecode, Nilearn, and SKADA), facilitating reproducible benchmarking and practical deployment.
Hierarchical Variable Importance with Statistical Control for Medical Data-Based Prediction
Aug 12, 2025Recent advances in machine learning have greatly expanded the repertoire of predictive methods for medical imaging. However, the interpretability of complex models remains a challenge, which limits their utility in medical applications. Recently, model-agnostic methods have been proposed to measure conditional variable importance and accommodate complex non-linear models. However, they often lack power when dealing with highly correlated data, a common problem in medical imaging. We introduce Hierarchical-CPI, a model-agnostic variable importance measure that frames the inference problem as the discovery of groups of variables that are jointly predictive of the outcome. By exploring subgroups along a hierarchical tree, it remains computationally tractable, yet also enjoys explicit family-wise error rate control. Moreover, we address the issue of vanishing conditional importance under high correlation with a tree-based importance allocation mechanism. We benchmarked Hierarchical-CPI against state-of-the-art variable importance methods. Its effectiveness is demonstrated in two neuroimaging datasets: classifying dementia diagnoses from MRI data (ADNI dataset) and analyzing the Berger effect on EEG data (TDBRAIN dataset), identifying biologically plausible variables.
SPD Learning for Covariance-Based Neuroimaging Analysis: Perspectives, Methods, and Challenges
Apr 26, 2025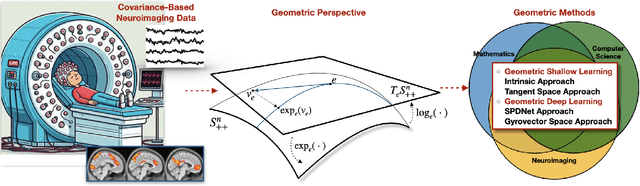

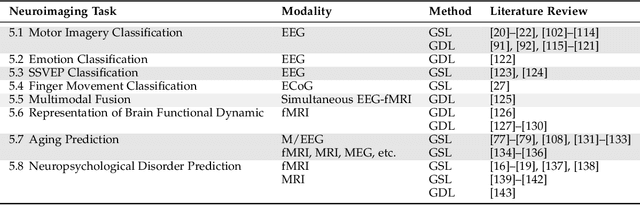
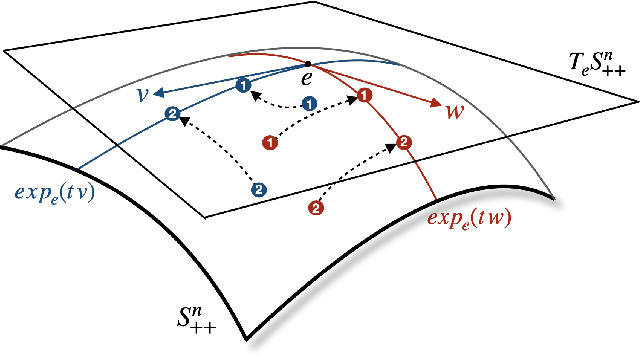
Neuroimaging provides a critical framework for characterizing brain activity by quantifying connectivity patterns and functional architecture across modalities. While modern machine learning has significantly advanced our understanding of neural processing mechanisms through these datasets, decoding task-specific signatures must contend with inherent neuroimaging constraints, for example, low signal-to-noise ratios in raw electrophysiological recordings, cross-session non-stationarity, and limited sample sizes. This review focuses on machine learning approaches for covariance-based neuroimaging data, where often symmetric positive definite (SPD) matrices under full-rank conditions encode inter-channel relationships. By equipping the space of SPD matrices with Riemannian metrics (e.g., affine-invariant or log-Euclidean), their space forms a Riemannian manifold enabling geometric analysis. We unify methodologies operating on this manifold under the SPD learning framework, which systematically leverages the SPD manifold's geometry to process covariance features, thereby advancing brain imaging analytics.
PSDNorm: Test-Time Temporal Normalization for Deep Learning on EEG Signals
Mar 06, 2025



Distribution shift poses a significant challenge in machine learning, particularly in biomedical applications such as EEG signals collected across different subjects, institutions, and recording devices. While existing normalization layers, Batch-Norm, LayerNorm and InstanceNorm, help address distribution shifts, they fail to capture the temporal dependencies inherent in temporal signals. In this paper, we propose PSDNorm, a layer that leverages Monge mapping and temporal context to normalize feature maps in deep learning models. Notably, the proposed method operates as a test-time domain adaptation technique, addressing distribution shifts without additional training. Evaluations on 10 sleep staging datasets using the U-Time model demonstrate that PSDNorm achieves state-of-the-art performance at test time on datasets not seen during training while being 4x more data-efficient than the best baseline. Additionally, PSDNorm provides a significant improvement in robustness, achieving markedly higher F1 scores for the 20% hardest subjects.
Multi-Source and Test-Time Domain Adaptation on Multivariate Signals using Spatio-Temporal Monge Alignment
Jul 19, 2024Machine learning applications on signals such as computer vision or biomedical data often face significant challenges due to the variability that exists across hardware devices or session recordings. This variability poses a Domain Adaptation (DA) problem, as training and testing data distributions often differ. In this work, we propose Spatio-Temporal Monge Alignment (STMA) to mitigate these variabilities. This Optimal Transport (OT) based method adapts the cross-power spectrum density (cross-PSD) of multivariate signals by mapping them to the Wasserstein barycenter of source domains (multi-source DA). Predictions for new domains can be done with a filtering without the need for retraining a model with source data (test-time DA). We also study and discuss two special cases of the method, Temporal Monge Alignment (TMA) and Spatial Monge Alignment (SMA). Non-asymptotic concentration bounds are derived for the mappings estimation, which reveals a bias-plus-variance error structure with a variance decay rate of $\mathcal{O}(n_\ell^{-1/2})$ with $n_\ell$ the signal length. This theoretical guarantee demonstrates the efficiency of the proposed computational schema. Numerical experiments on multivariate biosignals and image data show that STMA leads to significant and consistent performance gains between datasets acquired with very different settings. Notably, STMA is a pre-processing step complementary to state-of-the-art deep learning methods.
SKADA-Bench: Benchmarking Unsupervised Domain Adaptation Methods with Realistic Validation
Jul 16, 2024



Unsupervised Domain Adaptation (DA) consists of adapting a model trained on a labeled source domain to perform well on an unlabeled target domain with some data distribution shift. While many methods have been proposed in the literature, fair and realistic evaluation remains an open question, particularly due to methodological difficulties in selecting hyperparameters in the unsupervised setting. With SKADA-Bench, we propose a framework to evaluate DA methods and present a fair evaluation of existing shallow algorithms, including reweighting, mapping, and subspace alignment. Realistic hyperparameter selection is performed with nested cross-validation and various unsupervised model selection scores, on both simulated datasets with controlled shifts and real-world datasets across diverse modalities, such as images, text, biomedical, and tabular data with specific feature extraction. Our benchmark highlights the importance of realistic validation and provides practical guidance for real-life applications, with key insights into the choice and impact of model selection approaches. SKADA-Bench is open-source, reproducible, and can be easily extended with novel DA methods, datasets, and model selection criteria without requiring re-evaluating competitors. SKADA-Bench is available on GitHub at https://github.com/scikit-adaptation/skada-bench.
Geodesic Optimization for Predictive Shift Adaptation on EEG data
Jul 04, 2024



Electroencephalography (EEG) data is often collected from diverse contexts involving different populations and EEG devices. This variability can induce distribution shifts in the data $X$ and in the biomedical variables of interest $y$, thus limiting the application of supervised machine learning (ML) algorithms. While domain adaptation (DA) methods have been developed to mitigate the impact of these shifts, such methods struggle when distribution shifts occur simultaneously in $X$ and $y$. As state-of-the-art ML models for EEG represent the data by spatial covariance matrices, which lie on the Riemannian manifold of Symmetric Positive Definite (SPD) matrices, it is appealing to study DA techniques operating on the SPD manifold. This paper proposes a novel method termed Geodesic Optimization for Predictive Shift Adaptation (GOPSA) to address test-time multi-source DA for situations in which source domains have distinct $y$ distributions. GOPSA exploits the geodesic structure of the Riemannian manifold to jointly learn a domain-specific re-centering operator representing site-specific intercepts and the regression model. We performed empirical benchmarks on the cross-site generalization of age-prediction models with resting-state EEG data from a large multi-national dataset (HarMNqEEG), which included $14$ recording sites and more than $1500$ human participants. Compared to state-of-the-art methods, our results showed that GOPSA achieved significantly higher performance on three regression metrics ($R^2$, MAE, and Spearman's $\rho$) for several source-target site combinations, highlighting its effectiveness in tackling multi-source DA with predictive shifts in EEG data analysis. Our method has the potential to combine the advantages of mixed-effects modeling with machine learning for biomedical applications of EEG, such as multicenter clinical trials.
Weakly supervised covariance matrices alignment through Stiefel matrices estimation for MEG applications
Jan 24, 2024This paper introduces a novel domain adaptation technique for time series data, called Mixing model Stiefel Adaptation (MSA), specifically addressing the challenge of limited labeled signals in the target dataset. Leveraging a domain-dependent mixing model and the optimal transport domain adaptation assumption, we exploit abundant unlabeled data in the target domain to ensure effective prediction by establishing pairwise correspondence with equivalent signal variances between domains. Theoretical foundations are laid for identifying crucial Stiefel matrices, essential for recovering underlying signal variances from a Riemannian representation of observed signal covariances. We propose an integrated cost function that simultaneously learns these matrices, pairwise domain relationships, and a predictor, classifier, or regressor, depending on the task. Applied to neuroscience problems, MSA outperforms recent methods in brain-age regression with task variations using magnetoencephalography (MEG) signals from the Cam-CAN dataset.
The Fisher-Rao geometry of CES distributions
Oct 02, 2023



When dealing with a parametric statistical model, a Riemannian manifold can naturally appear by endowing the parameter space with the Fisher information metric. The geometry induced on the parameters by this metric is then referred to as the Fisher-Rao information geometry. Interestingly, this yields a point of view that allows for leveragingmany tools from differential geometry. After a brief introduction about these concepts, we will present some practical uses of these geometric tools in the framework of elliptical distributions. This second part of the exposition is divided into three main axes: Riemannian optimization for covariance matrix estimation, Intrinsic Cram\'er-Rao bounds, and classification using Riemannian distances.
Entropic Wasserstein Component Analysis
Mar 09, 2023



Dimension reduction (DR) methods provide systematic approaches for analyzing high-dimensional data. A key requirement for DR is to incorporate global dependencies among original and embedded samples while preserving clusters in the embedding space. To achieve this, we combine the principles of optimal transport (OT) and principal component analysis (PCA). Our method seeks the best linear subspace that minimizes reconstruction error using entropic OT, which naturally encodes the neighborhood information of the samples. From an algorithmic standpoint, we propose an efficient block-majorization-minimization solver over the Stiefel manifold. Our experimental results demonstrate that our approach can effectively preserve high-dimensional clusters, leading to more interpretable and effective embeddings. Python code of the algorithms and experiments is available online.