 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSPDnet: Geometry-Aware Federated Deep Learning with SPDnet
Apr 24, 2026We introduce two federated learning frameworks for the classical SPDnet model operating on symmetric positive definite (SPD) matrices with Stiefel-constrained parameters. Unlike standard Euclidean averaging, which violates orthogonality, our approach preserves geometric structure through two efficient aggregation strategies: ProjAvg, projecting arithmetic means onto the Stiefel manifold, and RLAvg, approximating tangent-space averaging via retractions and liftings. Both methods are computationally efficient, independent of the optimizer, and enable scalable federated learning for signal processing applications whose features are SPD matrices. Simulations on EEG motor imagery benchmarks show that FedSPDnet outperforms federated EEGnet in F1 score and robustness to federation and partial participation, while using fewer parameters per communication round.
SPD Learn: A Geometric Deep Learning Python Library for Neural Decoding Through Trivialization
Feb 26, 2026Implementations of symmetric positive definite (SPD) matrix-based neural networks for neural decoding remain fragmented across research codebases and Python packages. Existing implementations often employ ad hoc handling of manifold constraints and non-unified training setups, which hinders reproducibility and integration into modern deep-learning workflows. To address this gap, we introduce SPD Learn, a unified and modular Python package for geometric deep learning with SPD matrices. SPD Learn provides core SPD operators and neural-network layers, including numerically stable spectral operators, and enforces Stiefel/SPD constraints via trivialization-based parameterizations. This design enables standard backpropagation and optimization in unconstrained Euclidean spaces while producing manifold-constrained parameters by construction. The package also offers reference implementations of representative SPDNet-based models and interfaces with widely used brain computer interface/neuroimaging toolkits and modern machine-learning libraries (e.g., MOABB, Braindecode, Nilearn, and SKADA), facilitating reproducible benchmarking and practical deployment.
Leveraging Low-rank Factorizations of Conditional Correlation Matrices in Graph Learning
Jun 12, 2025This paper addresses the problem of learning an undirected graph from data gathered at each nodes. Within the graph signal processing framework, the topology of such graph can be linked to the support of the conditional correlation matrix of the data. The corresponding graph learning problem then scales to the squares of the number of variables (nodes), which is usually problematic at large dimension. To tackle this issue, we propose a graph learning framework that leverages a low-rank factorization of the conditional correlation matrix. In order to solve for the resulting optimization problems, we derive tools required to apply Riemannian optimization techniques for this particular structure. The proposal is then particularized to a low-rank constrained counterpart of the GLasso algorithm, i.e., the penalized maximum likelihood estimation of a Gaussian graphical model. Experiments on synthetic and real data evidence that a very efficient dimension-versus-performance trade-off can be achieved with this approach.
Beyond R-barycenters: an effective averaging method on Stiefel and Grassmann manifolds
Jan 20, 2025In this paper, the issue of averaging data on a manifold is addressed. While the Fr\'echet mean resulting from Riemannian geometry appears ideal, it is unfortunately not always available and often computationally very expensive. To overcome this, R-barycenters have been proposed and successfully applied to Stiefel and Grassmann manifolds. However, R-barycenters still suffer severe limitations as they rely on iterative algorithms and complicated operators. We propose simpler, yet efficient, barycenters that we call RL-barycenters. We show that, in the setting relevant to most applications, our framework yields astonishingly simple barycenters: arithmetic means projected onto the manifold. We apply this approach to the Stiefel and Grassmann manifolds. On simulated data, our approach is competitive with respect to existing averaging methods, while computationally cheaper.
Elliptical Wishart distributions: information geometry, maximum likelihood estimator, performance analysis and statistical learning
Nov 05, 2024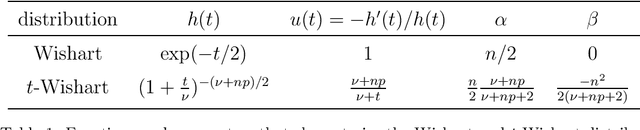
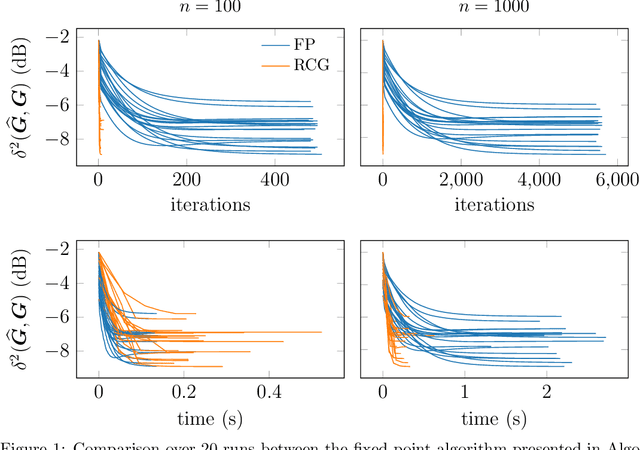
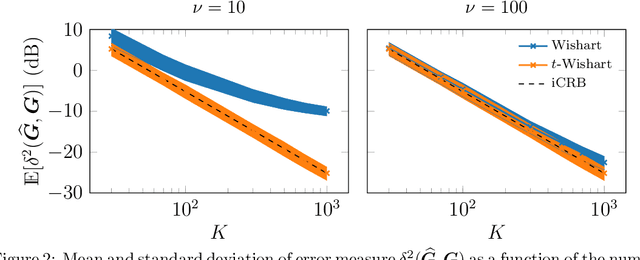
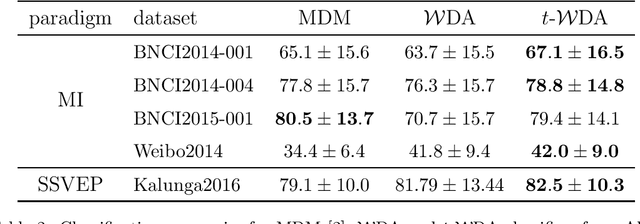
This paper deals with Elliptical Wishart distributions - which generalize the Wishart distribution - in the context of signal processing and machine learning. Two algorithms to compute the maximum likelihood estimator (MLE) are proposed: a fixed point algorithm and a Riemannian optimization method based on the derived information geometry of Elliptical Wishart distributions. The existence and uniqueness of the MLE are characterized as well as the convergence of both estimation algorithms. Statistical properties of the MLE are also investigated such as consistency, asymptotic normality and an intrinsic version of Fisher efficiency. On the statistical learning side, novel classification and clustering methods are designed. For the $t$-Wishart distribution, the performance of the MLE and statistical learning algorithms are evaluated on both simulated and real EEG and hyperspectral data, showcasing the interest of our proposed methods.
Random matrix theory improved Fréchet mean of symmetric positive definite matrices
May 10, 2024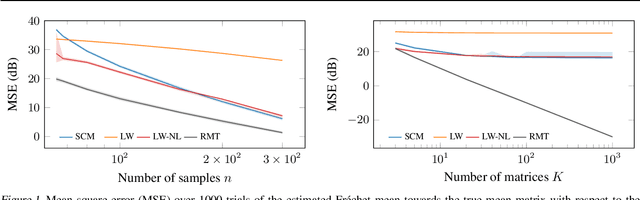


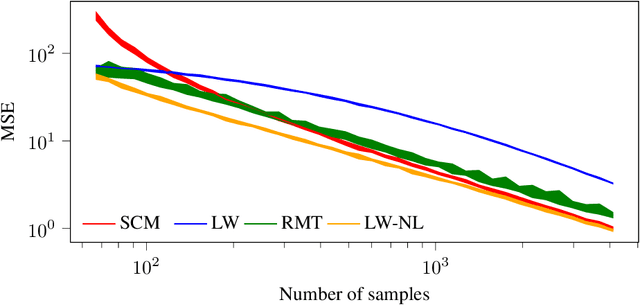
In this study, we consider the realm of covariance matrices in machine learning, particularly focusing on computing Fr\'echet means on the manifold of symmetric positive definite matrices, commonly referred to as Karcher or geometric means. Such means are leveraged in numerous machine-learning tasks. Relying on advanced statistical tools, we introduce a random matrix theory-based method that estimates Fr\'echet means, which is particularly beneficial when dealing with low sample support and a high number of matrices to average. Our experimental evaluation, involving both synthetic and real-world EEG and hyperspectral datasets, shows that we largely outperform state-of-the-art methods.
Natural Bayesian Cramér-Rao Bound with an Application to Covariance Estimation
Nov 08, 2023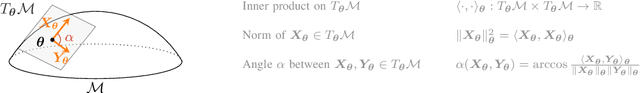

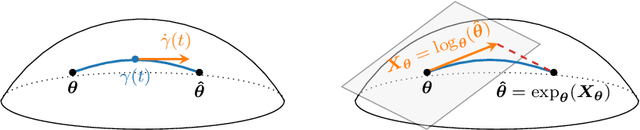

In this paper, we propose to develop a new Cram\'er-Rao Bound (CRB) when the parameter to estimate lies in a manifold and follows a prior distribution. This derivation leads to a natural inequality between an error criteria based on geometrical properties and this new bound. This main contribution is illustrated in the problem of covariance estimation when the data follow a Gaussian distribution and the prior distribution is an inverse Wishart. Numerical simulation shows new results where the proposed CRB allows to exhibit interesting properties of the MAP estimator which are not observed with the classical Bayesian CRB.
The Fisher-Rao geometry of CES distributions
Oct 02, 2023



When dealing with a parametric statistical model, a Riemannian manifold can naturally appear by endowing the parameter space with the Fisher information metric. The geometry induced on the parameters by this metric is then referred to as the Fisher-Rao information geometry. Interestingly, this yields a point of view that allows for leveragingmany tools from differential geometry. After a brief introduction about these concepts, we will present some practical uses of these geometric tools in the framework of elliptical distributions. This second part of the exposition is divided into three main axes: Riemannian optimization for covariance matrix estimation, Intrinsic Cram\'er-Rao bounds, and classification using Riemannian distances.
Riemannian classification of EEG signals with missing values
Oct 19, 2021


This paper proposes two strategies to handle missing data for the classification of electroencephalograms using covariance matrices. The first approach estimates the covariance from imputed data with the $k$-nearest neighbors algorithm; the second relies on the observed data by leveraging the observed-data likelihood within an expectation-maximization algorithm. Both approaches are combined with the minimum distance to Riemannian mean classifier and applied to a classification task of event related-potentials, a widely known paradigm of brain-computer interface paradigms. As results show, the proposed strategies perform better than the classification based on observed data and allow to keep a high accuracy even when the missing data ratio increases.
Riemannian geometry for Compound Gaussian distributions: application to recursive change detection
May 20, 2020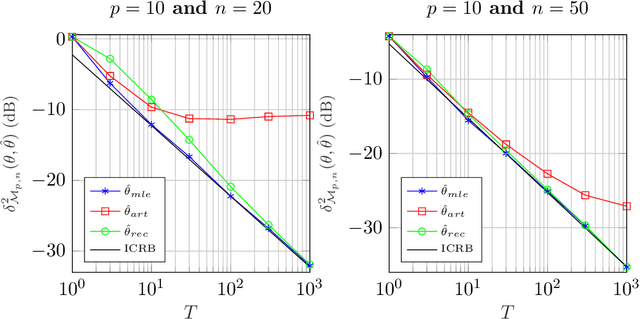
A new Riemannian geometry for the Compound Gaussian distribution is proposed. In particular, the Fisher information metric is obtained, along with corresponding geodesics and distance function. This new geometry is applied on a change detection problem on Multivariate Image Times Series: a recursive approach based on Riemannian optimization is developed. As shown on simulated data, it allows to reach optimal performance while being computationally more efficient.