 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEPC: Group-Equivariant Posterior Consistency for Out-of-Distribution Detection in Diffusion Models
Jan 30, 2026Diffusion models learn a time-indexed score field $\mathbf{s}_θ(\mathbf{x}_t,t)$ that often inherits approximate equivariances (flips, rotations, circular shifts) from in-distribution (ID) data and convolutional backbones. Most diffusion-based out-of-distribution (OOD) detectors exploit score magnitude or local geometry (energies, curvature, covariance spectra) and largely ignore equivariances. We introduce Group-Equivariant Posterior Consistency (GEPC), a training-free probe that measures how consistently the learned score transforms under a finite group $\mathcal{G}$, detecting equivariance breaking even when score magnitude remains unchanged. At the population level, we propose the ideal GEPC residual, which averages an equivariance-residual functional over $\mathcal{G}$, and we derive ID upper bounds and OOD lower bounds under mild assumptions. GEPC requires only score evaluations and produces interpretable equivariance-breaking maps. On OOD image benchmark datasets, we show that GEPC achieves competitive or improved AUROC compared to recent diffusion-based baselines while remaining computationally lightweight. On high-resolution synthetic aperture radar imagery where OOD corresponds to targets or anomalies in clutter, GEPC yields strong target-background separation and visually interpretable equivariance-breaking maps. Code is available at https://github.com/RouzAY/gepc-diffusion/.
Out-of-Distribution Radar Detection with Complex VAEs: Theory, Whitening, and ANMF Fusion
Jan 26, 2026We investigate the detection of weak complex-valued signals immersed in non-Gaussian, range-varying interference, with emphasis on maritime radar scenarios. The proposed methodology exploits a Complex-valued Variational AutoEncoder (CVAE) trained exclusively on clutter-plus-noise to perform Out-Of-Distribution detection. By operating directly on in-phase / quadrature samples, the CVAE preserves phase and Doppler structure and is assessed in two configurations: (i) using unprocessed range profiles and (ii) after local whitening, where per-range covariance estimates are obtained from neighboring profiles. Using extensive simulations together with real sea-clutter data from the CSIR maritime dataset, we benchmark performance against classical and adaptive detectors (MF, NMF, AMF-SCM, ANMF-SCM, ANMF-Tyler). In both configurations, the CVAE yields a higher detection probability Pd at matched false-alarm rate Pfa, with the most notable improvements observed under whitening. We further integrate the CVAE with the ANMF through a weighted log-p fusion rule at the decision level, attaining enhanced robustness in strongly non-Gaussian clutter and enabling empirically calibrated Pfa control under H0. Overall, the results demonstrate that statistical normalization combined with complex-valued generative modeling substantively improves detection in realistic sea-clutter conditions, and that the fused CVAE-ANMF scheme constitutes a competitive alternative to established model-based detectors.
General Feature Extraction In SAR Target Classification: A Contrastive Learning Approach Across Sensor Types
Feb 03, 2025The increased availability of SAR data has raised a growing interest in applying deep learning algorithms. However, the limited availability of labeled data poses a significant challenge for supervised training. This article introduces a new method for classifying SAR data with minimal labeled images. The method is based on a feature extractor Vit trained with contrastive learning. It is trained on a dataset completely different from the one on which classification is made. The effectiveness of the method is assessed through 2D visualization using t-SNE for qualitative evaluation and k-NN classification with a small number of labeled data for quantitative evaluation. Notably, our results outperform a k-NN on data processed with PCA and a ResNet-34 specifically trained for the task, achieving a 95.9% accuracy on the MSTAR dataset with just ten labeled images per class.
SAFE: a SAR Feature Extractor based on self-supervised learning and masked Siamese ViTs
Jun 30, 2024



Due to its all-weather and day-and-night capabilities, Synthetic Aperture Radar imagery is essential for various applications such as disaster management, earth monitoring, change detection and target recognition. However, the scarcity of labeled SAR data limits the performance of most deep learning algorithms. To address this issue, we propose a novel self-supervised learning framework based on masked Siamese Vision Transformers to create a General SAR Feature Extractor coined SAFE. Our method leverages contrastive learning principles to train a model on unlabeled SAR data, extracting robust and generalizable features. SAFE is applicable across multiple SAR acquisition modes and resolutions. We introduce tailored data augmentation techniques specific to SAR imagery, such as sub-aperture decomposition and despeckling. Comprehensive evaluations on various downstream tasks, including few-shot classification, segmentation, visualization, and pattern detection, demonstrate the effectiveness and versatility of the proposed approach. Our network competes with or surpasses other state-of-the-art methods in few-shot classification and segmentation tasks, even without being trained on the sensors used for the evaluation.
Neural network scoring for efficient computing
Oct 14, 2023Much work has been dedicated to estimating and optimizing workloads in high-performance computing (HPC) and deep learning. However, researchers have typically relied on few metrics to assess the efficiency of those techniques. Most notably, the accuracy, the loss of the prediction, and the computational time with regard to GPUs or/and CPUs characteristics. It is rare to see figures for power consumption, partly due to the difficulty of obtaining accurate power readings. In this paper, we introduce a composite score that aims to characterize the trade-off between accuracy and power consumption measured during the inference of neural networks. For this purpose, we present a new open-source tool allowing researchers to consider more metrics: granular power consumption, but also RAM/CPU/GPU utilization, as well as storage, and network input/output (I/O). To our best knowledge, it is the first fit test for neural architectures on hardware architectures. This is made possible thanks to reproducible power efficiency measurements. We applied this procedure to state-of-the-art neural network architectures on miscellaneous hardware. One of the main applications and novelties is the measurement of algorithmic power efficiency. The objective is to allow researchers to grasp their algorithms' efficiencies better. This methodology was developed to explore trade-offs between energy usage and accuracy in neural networks. It is also useful when fitting hardware for a specific task or to compare two architectures more accurately, with architecture exploration in mind.
* 5 pages, 5 figures
Theory and Implementation of Complex-Valued Neural Networks
Feb 16, 2023



This work explains in detail the theory behind Complex-Valued Neural Network (CVNN), including Wirtinger calculus, complex backpropagation, and basic modules such as complex layers, complex activation functions, or complex weight initialization. We also show the impact of not adapting the weight initialization correctly to the complex domain. This work presents a strong focus on the implementation of such modules on Python using cvnn toolbox. We also perform simulations on real-valued data, casting to the complex domain by means of the Hilbert Transform, and verifying the potential interest of CVNN even for non-complex data.
Deep Learning-Based Anomaly Detection in Synthetic Aperture Radar Imaging
Oct 28, 2022In this paper, we proposed to investigate unsupervised anomaly detection in Synthetic Aperture Radar (SAR) images. Our approach considers anomalies as abnormal patterns that deviate from their surroundings but without any prior knowledge of their characteristics. In the literature, most model-based algorithms face three main issues. First, the speckle noise corrupts the image and potentially leads to numerous false detections. Second, statistical approaches may exhibit deficiencies in modeling spatial correlation in SAR images. Finally, neural networks based on supervised learning approaches are not recommended due to the lack of annotated SAR data, notably for the class of abnormal patterns. Our proposed method aims to address these issues through a self-supervised algorithm. The speckle is first removed through the deep learning SAR2SAR algorithm. Then, an adversarial autoencoder is trained to reconstruct an anomaly-free SAR image. Finally, a change detection processing step is applied between the input and the output to detect anomalies. Experiments are performed to show the advantages of our method compared to the conventional Reed-Xiaoli algorithm, highlighting the importance of an efficient despeckling pre-processing step.
Impact of PolSAR pre-processing and balancing methods on complex-valued neural networks segmentation tasks
Oct 28, 2022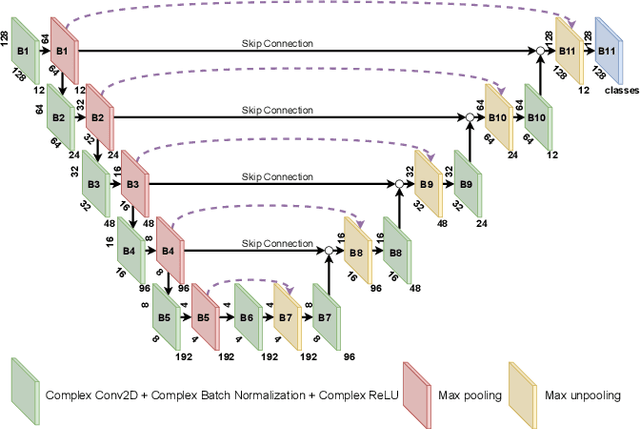
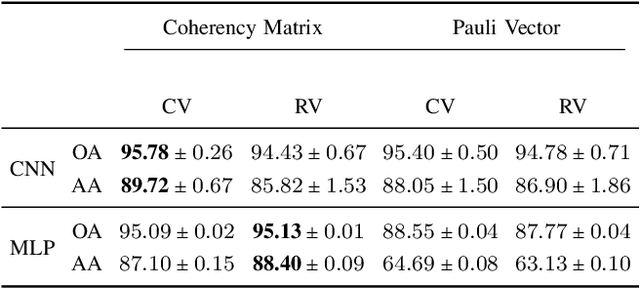
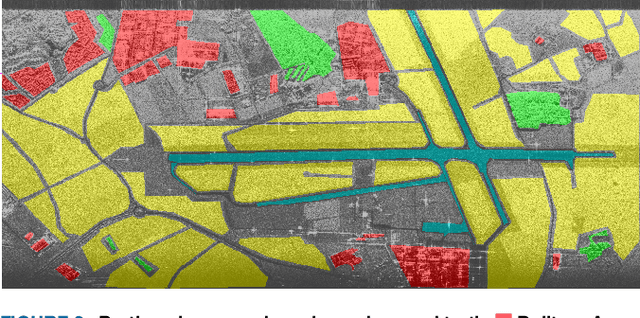
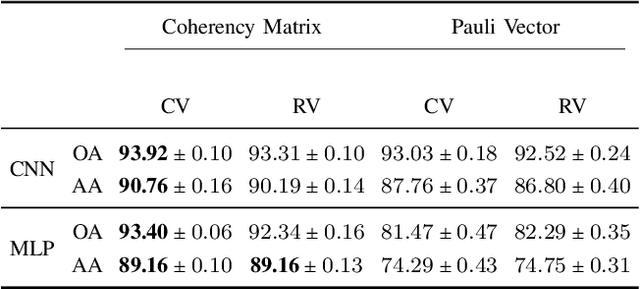
In this paper, we investigated the semantic segmentation of Polarimetric Synthetic Aperture Radar (PolSAR) using Complex-Valued Neural Network (CVNN). Although the coherency matrix is more widely used as the input of CVNN, the Pauli vector has recently been shown to be a valid alternative. We exhaustively compare both methods for six model architectures, three complex-valued, and their respective real-equivalent models. We are comparing, therefore, not only the input representation impact but also the complex- against the real-valued models. We then argue that the dataset splitting produces a high correlation between training and validation sets, saturating the task and thus achieving very high performance. We, therefore, use a different data pre-processing technique designed to reduce this effect and reproduce the results with the same configurations as before (input representation and model architectures). After seeing that the performance per class is highly different according to class occurrences, we propose two methods for reducing this gap and performing the results for all input representations, models, and dataset pre-processing.
Riemannian optimization for non-centered mixture of scaled Gaussian distributions
Sep 07, 2022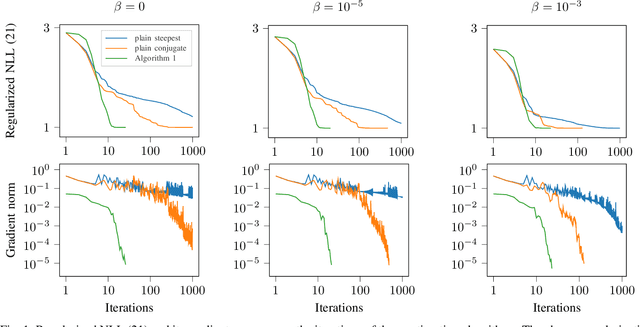
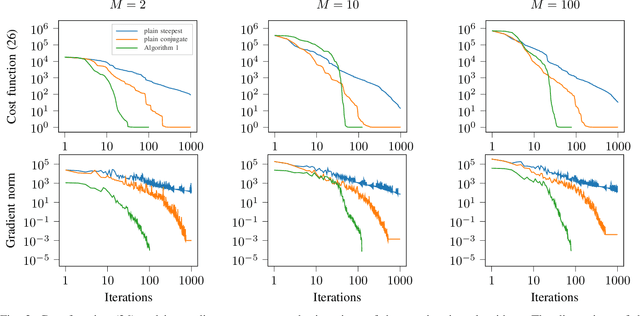

This paper studies the statistical model of the non-centered mixture of scaled Gaussian distributions (NC-MSG). Using the Fisher-Rao information geometry associated to this distribution, we derive a Riemannian gradient descent algorithm. This algorithm is leveraged for two minimization problems. The first one is the minimization of a regularized negative log- likelihood (NLL). The latter makes the trade-off between a white Gaussian distribution and the NC-MSG. Conditions on the regularization are given so that the existence of a minimum to this problem is guaranteed without assumptions on the samples. Then, the Kullback-Leibler (KL) divergence between two NC-MSG is derived. This divergence enables us to define a minimization problem to compute centers of mass of several NC-MSGs. The proposed Riemannian gradient descent algorithm is leveraged to solve this second minimization problem. Numerical experiments show the good performance and the speed of the Riemannian gradient descent on the two problems. Finally, a Nearest centroid classifier is implemented leveraging the KL divergence and its associated center of mass. Applied on the large scale dataset Breizhcrops, this classifier shows good accuracies as well as robustness to rigid transformations of the test set.
Robust Geometric Metric Learning
Feb 23, 2022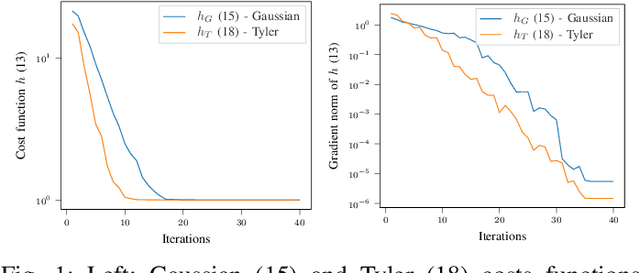
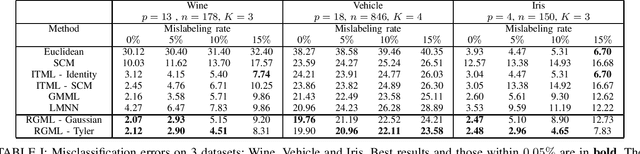
This paper proposes new algorithms for the metric learning problem. We start by noticing that several classical metric learning formulations from the literature can be viewed as modified covariance matrix estimation problems. Leveraging this point of view, a general approach, called Robust Geometric Metric Learning (RGML), is then studied. This method aims at simultaneously estimating the covariance matrix of each class while shrinking them towards their (unknown) barycenter. We focus on two specific costs functions: one associated with the Gaussian likelihood (RGML Gaussian), and one with Tyler's M -estimator (RGML Tyler). In both, the barycenter is defined with the Riemannian distance, which enjoys nice properties of geodesic convexity and affine invariance. The optimization is performed using the Riemannian geometry of symmetric positive definite matrices and its submanifold of unit determinant. Finally, the performance of RGML is asserted on real datasets. Strong performance is exhibited while being robust to mislabeled data.