 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFE: a SAR Feature Extractor based on self-supervised learning and masked Siamese ViTs
Jun 30, 2024



Due to its all-weather and day-and-night capabilities, Synthetic Aperture Radar imagery is essential for various applications such as disaster management, earth monitoring, change detection and target recognition. However, the scarcity of labeled SAR data limits the performance of most deep learning algorithms. To address this issue, we propose a novel self-supervised learning framework based on masked Siamese Vision Transformers to create a General SAR Feature Extractor coined SAFE. Our method leverages contrastive learning principles to train a model on unlabeled SAR data, extracting robust and generalizable features. SAFE is applicable across multiple SAR acquisition modes and resolutions. We introduce tailored data augmentation techniques specific to SAR imagery, such as sub-aperture decomposition and despeckling. Comprehensive evaluations on various downstream tasks, including few-shot classification, segmentation, visualization, and pattern detection, demonstrate the effectiveness and versatility of the proposed approach. Our network competes with or surpasses other state-of-the-art methods in few-shot classification and segmentation tasks, even without being trained on the sensors used for the evaluation.
Deep learning-based deconvolution for interferometric radio transient reconstruction
Jun 24, 2023



Radio astronomy is currently thriving with new large ground-based radio telescopes coming online in preparation for the upcoming Square Kilometre Array (SKA). Facilities like LOFAR, MeerKAT/SKA, ASKAP/SKA, and the future SKA-LOW bring tremendous sensitivity in time and frequency, improved angular resolution, and also high-rate data streams that need to be processed. They enable advanced studies of radio transients, volatile by nature, that can be detected or missed in the data. These transients are markers of high-energy accelerations of electrons and manifest in a wide range of temporal scales. Usually studied with dynamic spectroscopy of time series analysis, there is a motivation to search for such sources in large interferometric datasets. This requires efficient and robust signal reconstruction algorithms. To correctly account for the temporal dependency of the data, we improve the classical image deconvolution inverse problem by adding the temporal dependency in the reconstruction problem. Then, we introduce two novel neural network architectures that can do both spatial and temporal modeling of the data and the instrumental response. Then, we simulate representative time-dependent image cubes of point source distributions and realistic telescope pointings of MeerKAT to generate toy models to build the training, validation, and test datasets. Finally, based on the test data, we evaluate the source profile reconstruction performance of the proposed methods and classical image deconvolution algorithm CLEAN applied frame-by-frame. In the presence of increasing noise level in data frame, the proposed methods display a high level of robustness compared to frame-by-frame imaging with CLEAN. The deconvolved image cubes bring a factor of 3 improvement in fidelity of the recovered temporal profiles and a factor of 2 improvement in background denoising.
Stable Long-Term Recurrent Video Super-Resolution
Dec 16, 2021
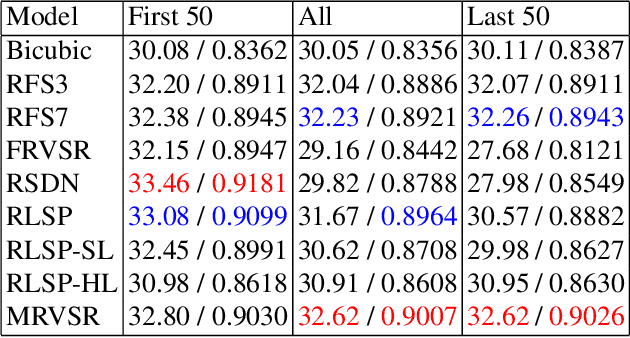
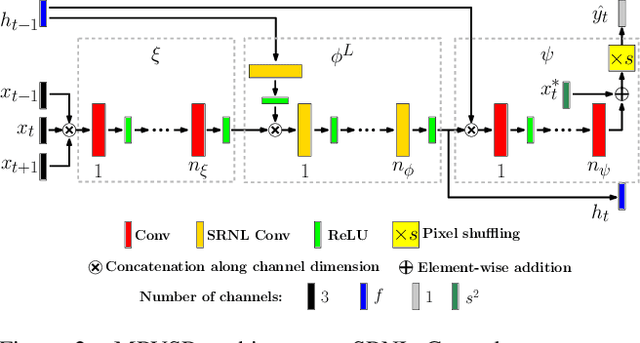

Recurrent models have gained popularity in deep learning (DL) based video super-resolution (VSR), due to their increased computational efficiency, temporal receptive field and temporal consistency compared to sliding-window based models. However, when inferring on long video sequences presenting low motion (i.e. in which some parts of the scene barely move), recurrent models diverge through recurrent processing, generating high frequency artifacts. To the best of our knowledge, no study about VSR pointed out this instability problem, which can be critical for some real-world applications. Video surveillance is a typical example where such artifacts would occur, as both the camera and the scene stay static for a long time. In this work, we expose instabilities of existing recurrent VSR networks on long sequences with low motion. We demonstrate it on a new long sequence dataset Quasi-Static Video Set, that we have created. Finally, we introduce a new framework of recurrent VSR networks that is both stable and competitive, based on Lipschitz stability theory. We propose a new recurrent VSR network, coined Middle Recurrent Video Super-Resolution (MRVSR), based on this framework. We empirically show its competitive performance on long sequences with low motion.
Deep Unrolled Network for Video Super-Resolution
Feb 23, 2021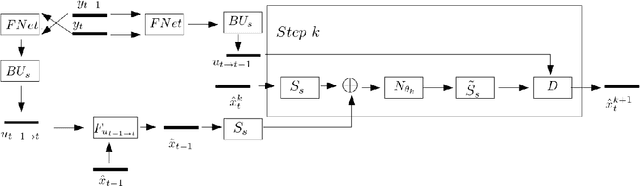


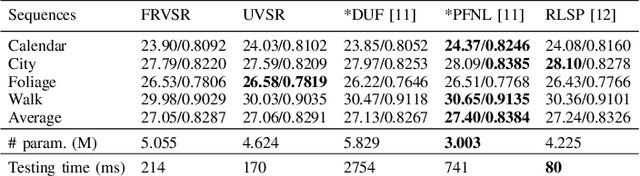
Video super-resolution (VSR) aims to reconstruct a sequence of high-resolution (HR) images from their corresponding low-resolution (LR) versions. Traditionally, solving a VSR problem has been based on iterative algorithms that can exploit prior knowledge on image formation and assumptions on the motion. However, these classical methods struggle at incorporating complex statistics from natural images. Furthermore, VSR has recently benefited from the improvement brought by deep learning (DL) algorithms. These techniques can efficiently learn spatial patterns from large collections of images. Yet, they fail to incorporate some knowledge about the image formation model, which limits their flexibility. Unrolled optimization algorithms, developed for inverse problems resolution, allow to include prior information into deep learning architectures. They have been used mainly for single image restoration tasks. Adapting an unrolled neural network structure can bring the following benefits. First, this may increase performance of the super-resolution task. Then, this gives neural networks better interpretability. Finally, this allows flexibility in learning a single model to nonblindly deal with multiple degradations. In this paper, we propose a new VSR neural network based on unrolled optimization techniques and discuss its performance.