 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Unrolled Network for Video Super-Resolution
Paper and Code
Feb 23, 2021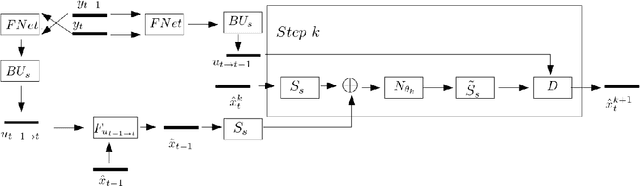


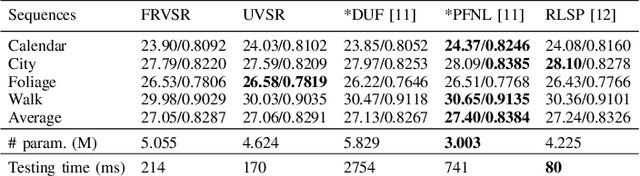
Video super-resolution (VSR) aims to reconstruct a sequence of high-resolution (HR) images from their corresponding low-resolution (LR) versions. Traditionally, solving a VSR problem has been based on iterative algorithms that can exploit prior knowledge on image formation and assumptions on the motion. However, these classical methods struggle at incorporating complex statistics from natural images. Furthermore, VSR has recently benefited from the improvement brought by deep learning (DL) algorithms. These techniques can efficiently learn spatial patterns from large collections of images. Yet, they fail to incorporate some knowledge about the image formation model, which limits their flexibility. Unrolled optimization algorithms, developed for inverse problems resolution, allow to include prior information into deep learning architectures. They have been used mainly for single image restoration tasks. Adapting an unrolled neural network structure can bring the following benefits. First, this may increase performance of the super-resolution task. Then, this gives neural networks better interpretability. Finally, this allows flexibility in learning a single model to nonblindly deal with multiple degradations. In this paper, we propose a new VSR neural network based on unrolled optimization techniques and discuss its performance.