 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirically Calibrated Conditional Independence Tests
Feb 24, 2026Conditional independence tests (CIT) are widely used for causal discovery and feature selection. Even with false discovery rate (FDR) control procedures, they often fail to provide frequentist guarantees in practice. We highlight two common failure modes: (i) in small samples, asymptotic guarantees for many CITs can be inaccurate and even correctly specified models fail to estimate the noise levels and control the error, and (ii) when sample sizes are large but models are misspecified, unaccounted dependencies skew the test's behavior and fail to return uniform p-values under the null. We propose Empirically Calibrated Conditional Independence Tests (ECCIT), a method that measures and corrects for miscalibration. For a chosen base CIT (e.g., GCM, HRT), ECCIT optimizes an adversary that selects features and response functions to maximize a miscalibration metric. ECCIT then fits a monotone calibration map that adjusts the base-test p-values in proportion to the observed miscalibration. Across empirical benchmarks on synthetic and real data, ECCIT achieves valid FDR with higher power than existing calibration strategies while remaining test agnostic.
Addressing the Cold-Start Problem for Personalized Combination Drug Screening
Sep 09, 2025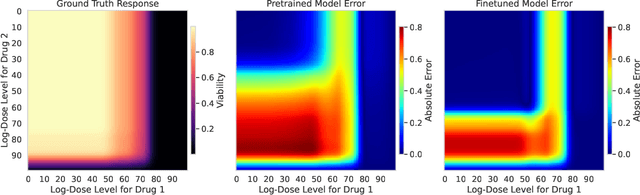
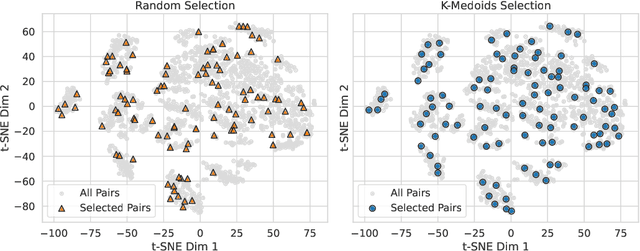
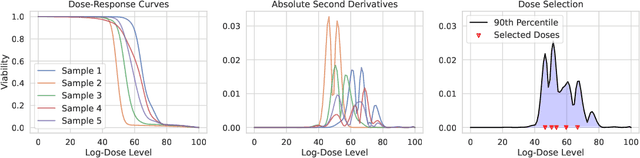
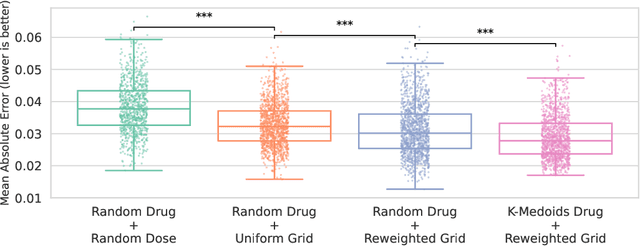
Personalizing combination therapies in oncology requires navigating an immense space of possible drug and dose combinations, a task that remains largely infeasible through exhaustive experimentation. Recent developments in patient-derived models have enabled high-throughput ex vivo screening, but the number of feasible experiments is limited. Further, a tight therapeutic window makes gathering molecular profiling information (e.g. RNA-seq) impractical as a means of guiding drug response prediction. This leads to a challenging cold-start problem: how do we select the most informative combinations to test early, when no prior information about the patient is available? We propose a strategy that leverages a pretrained deep learning model built on historical drug response data. The model provides both embeddings for drug combinations and dose-level importance scores, enabling a principled selection of initial experiments. We combine clustering of drug embeddings to ensure functional diversity with a dose-weighting mechanism that prioritizes doses based on their historical informativeness. Retrospective simulations on large-scale drug combination datasets show that our method substantially improves initial screening efficiency compared to baselines, offering a viable path for more effective early-phase decision-making in personalized combination drug screens.
OneBatchPAM: A Fast and Frugal K-Medoids Algorithm
Jan 31, 2025



This paper proposes a novel k-medoids approximation algorithm to handle large-scale datasets with reasonable computational time and memory complexity. We develop a local-search algorithm that iteratively improves the medoid selection based on the estimation of the k-medoids objective. A single batch of size m << n provides the estimation, which reduces the required memory size and the number of pairwise dissimilarities computations to O(mn), instead of O(n^2) compared to most k-medoids baselines. We obtain theoretical results highlighting that a batch of size m = O(log(n)) is sufficient to guarantee, with strong probability, the same performance as the original local-search algorithm. Multiple experiments conducted on real datasets of various sizes and dimensions show that our algorithm provides similar performances as state-of-the-art methods such as FasterPAM and BanditPAM++ with a drastically reduced running time.
SKADA-Bench: Benchmarking Unsupervised Domain Adaptation Methods with Realistic Validation
Jul 16, 2024



Unsupervised Domain Adaptation (DA) consists of adapting a model trained on a labeled source domain to perform well on an unlabeled target domain with some data distribution shift. While many methods have been proposed in the literature, fair and realistic evaluation remains an open question, particularly due to methodological difficulties in selecting hyperparameters in the unsupervised setting. With SKADA-Bench, we propose a framework to evaluate DA methods and present a fair evaluation of existing shallow algorithms, including reweighting, mapping, and subspace alignment. Realistic hyperparameter selection is performed with nested cross-validation and various unsupervised model selection scores, on both simulated datasets with controlled shifts and real-world datasets across diverse modalities, such as images, text, biomedical, and tabular data with specific feature extraction. Our benchmark highlights the importance of realistic validation and provides practical guidance for real-life applications, with key insights into the choice and impact of model selection approaches. SKADA-Bench is open-source, reproducible, and can be easily extended with novel DA methods, datasets, and model selection criteria without requiring re-evaluating competitors. SKADA-Bench is available on GitHub at https://github.com/scikit-adaptation/skada-bench.
Maximum Weight Entropy
Sep 27, 2023This paper deals with uncertainty quantification and out-of-distribution detection in deep learning using Bayesian and ensemble methods. It proposes a practical solution to the lack of prediction diversity observed recently for standard approaches when used out-of-distribution (Ovadia et al., 2019; Liu et al., 2021). Considering that this issue is mainly related to a lack of weight diversity, we claim that standard methods sample in "over-restricted" regions of the weight space due to the use of "over-regularization" processes, such as weight decay and zero-mean centered Gaussian priors. We propose to solve the problem by adopting the maximum entropy principle for the weight distribution, with the underlying idea to maximize the weight diversity. Under this paradigm, the epistemic uncertainty is described by the weight distribution of maximal entropy that produces neural networks "consistent" with the training observations. Considering stochastic neural networks, a practical optimization is derived to build such a distribution, defined as a trade-off between the average empirical risk and the weight distribution entropy. We develop a novel weight parameterization for the stochastic model, based on the singular value decomposition of the neural network's hidden representations, which enables a large increase of the weight entropy for a small empirical risk penalization. We provide both theoretical and numerical results to assess the efficiency of the approach. In particular, the proposed algorithm appears in the top three best methods in all configurations of an extensive out-of-distribution detection benchmark including more than thirty competitors.
Deep Anti-Regularized Ensembles provide reliable out-of-distribution uncertainty quantification
Apr 08, 2023



We consider the problem of uncertainty quantification in high dimensional regression and classification for which deep ensemble have proven to be promising methods. Recent observations have shown that deep ensemble often return overconfident estimates outside the training domain, which is a major limitation because shifted distributions are often encountered in real-life scenarios. The principal challenge for this problem is to solve the trade-off between increasing the diversity of the ensemble outputs and making accurate in-distribution predictions. In this work, we show that an ensemble of networks with large weights fitting the training data are likely to meet these two objectives. We derive a simple and practical approach to produce such ensembles, based on an original anti-regularization term penalizing small weights and a control process of the weight increase which maintains the in-distribution loss under an acceptable threshold. The developed approach does not require any out-of-distribution training data neither any trade-off hyper-parameter calibration. We derive a theoretical framework for this approach and show that the proposed optimization can be seen as a "water-filling" problem. Several experiments in both regression and classification settings highlight that Deep Anti-Regularized Ensembles (DARE) significantly improve uncertainty quantification outside the training domain in comparison to recent deep ensembles and out-of-distribution detection methods. All the conducted experiments are reproducible and the source code is available at \url{https://github.com/antoinedemathelin/DARE}.
Fast and Accurate Importance Weighting for Correcting Sample Bias
Sep 09, 2022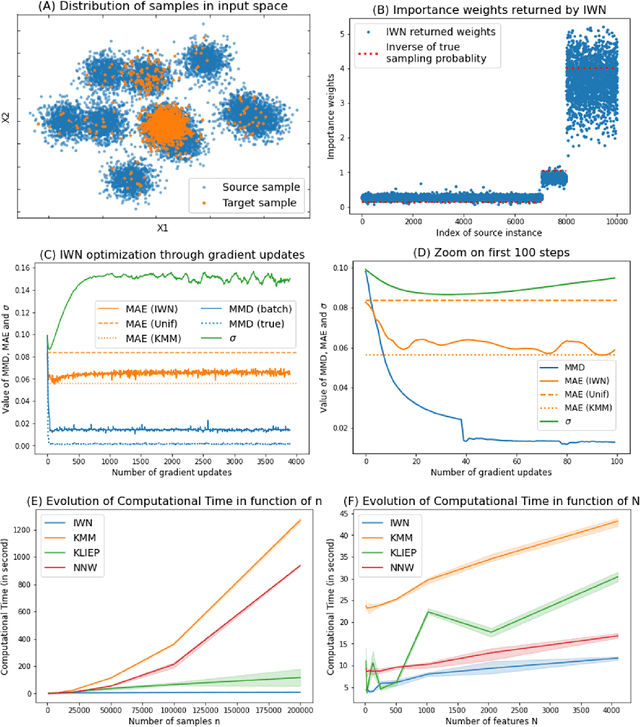
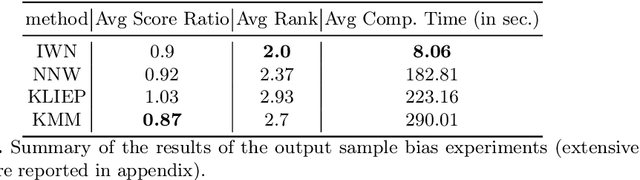
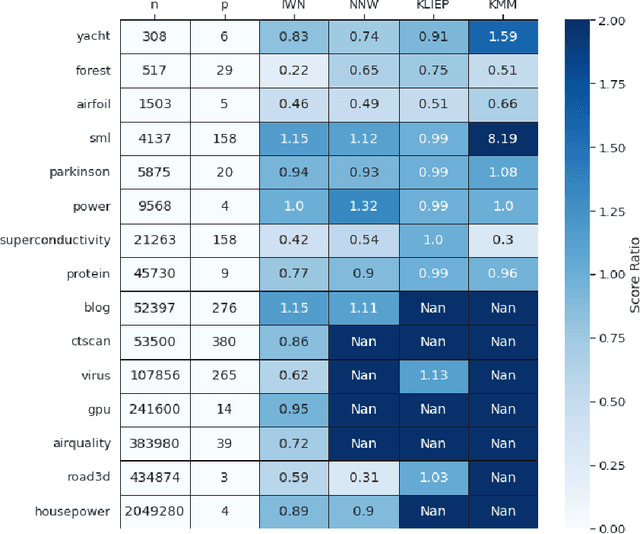
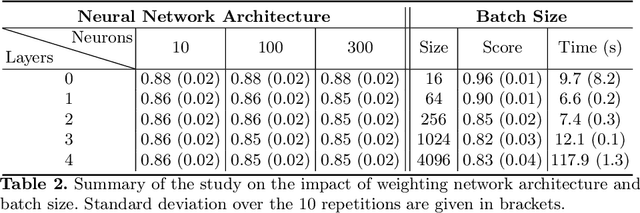
Bias in datasets can be very detrimental for appropriate statistical estimation. In response to this problem, importance weighting methods have been developed to match any biased distribution to its corresponding target unbiased distribution. The seminal Kernel Mean Matching (KMM) method is, nowadays, still considered as state of the art in this research field. However, one of the main drawbacks of this method is the computational burden for large datasets. Building on previous works by Huang et al. (2007) and de Mathelin et al. (2021), we derive a novel importance weighting algorithm which scales to large datasets by using a neural network to predict the instance weights. We show, on multiple public datasets, under various sample biases, that our proposed approach drastically reduces the computational time on large dataset while maintaining similar sample bias correction performance compared to other importance weighting methods. The proposed approach appears to be the only one able to give relevant reweighting in a reasonable time for large dataset with up to two million data.
Unsupervised Domain Adaptation for Constraining Star Formation Histories
Dec 28, 2021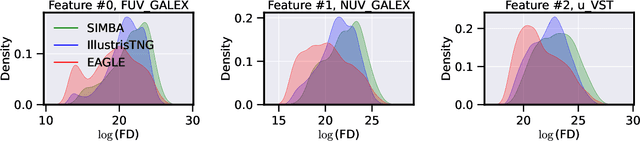
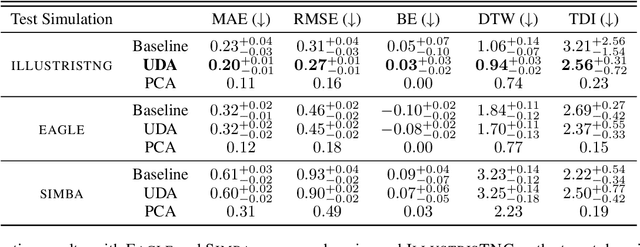
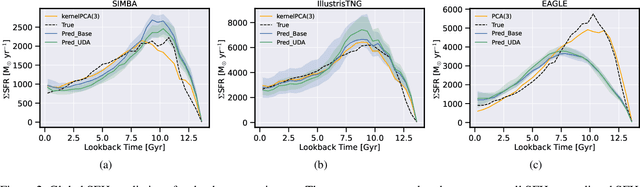
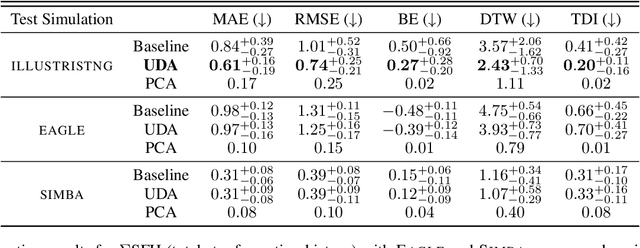
The prevalent paradigm of machine learning today is to use past observations to predict future ones. What if, however, we are interested in knowing the past given the present? This situation is indeed one that astronomers must contend with often. To understand the formation of our universe, we must derive the time evolution of the visible mass content of galaxies. However, to observe a complete star life, one would need to wait for one billion years! To overcome this difficulty, astrophysicists leverage supercomputers and evolve simulated models of galaxies till the current age of the universe, thus establishing a mapping between observed radiation and star formation histories (SFHs). Such ground-truth SFHs are lacking for actual galaxy observations, where they are usually inferred -- with often poor confidence -- from spectral energy distributions (SEDs) using Bayesian fitting methods. In this investigation, we discuss the ability of unsupervised domain adaptation to derive accurate SFHs for galaxies with simulated data as a necessary first step in developing a technique that can ultimately be applied to observational data.
A Binded VAE for Inorganic Material Generation
Dec 17, 2021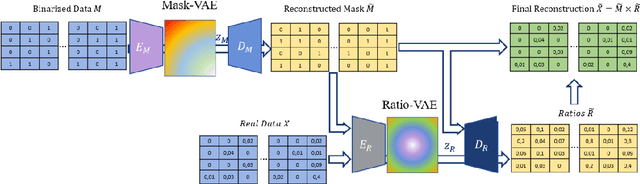

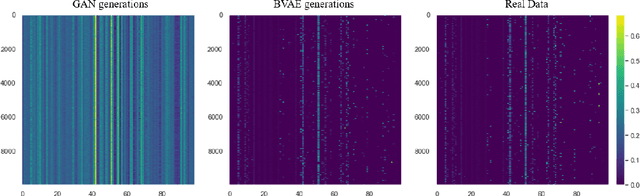

Designing new industrial materials with desired properties can be very expensive and time consuming. The main difficulty is to generate compounds that correspond to realistic materials. Indeed, the description of compounds as vectors of components' proportions is characterized by discrete features and a severe sparsity. Furthermore, traditional generative model validation processes as visual verification, FID and Inception scores are tailored for images and cannot then be used as such in this context. To tackle these issues, we develop an original Binded-VAE model dedicated to the generation of discrete datasets with high sparsity. We validate the model with novel metrics adapted to the problem of compounds generation. We show on a real issue of rubber compound design that the proposed approach outperforms the standard generative models which opens new perspectives for material design optimization.
ADAPT : Awesome Domain Adaptation Python Toolbox
Jul 07, 2021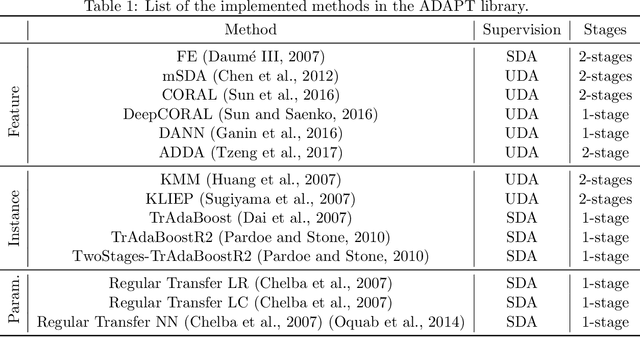
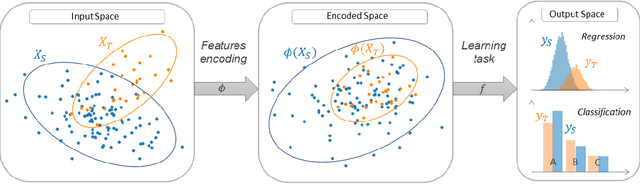
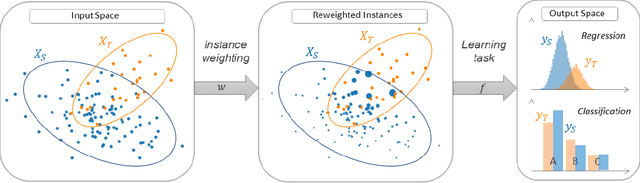
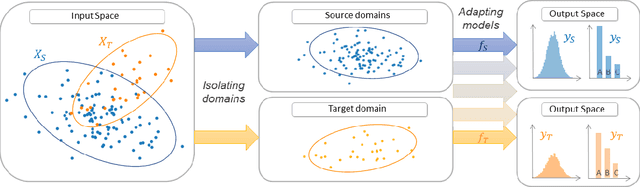
ADAPT is an open-source python library providing the implementation of several domain adaptation methods. The library is suited for scikit-learn estimator object (object which implement fit and predict methods) and tensorflow models. Most of the implemented methods are developed in an estimator agnostic fashion, offering various possibilities adapted to multiple usage. The library offers three modules corresponding to the three principal strategies of domain adaptation: (i) feature-based containing methods performing feature transformation; (ii) instance-based with the implementation of reweighting techniques and (iii) parameter-based proposing methods to adapt pre-trained models to novel observations. A full documentation is proposed online https://adapt-python.github.io/adapt/ with gallery of examples. Besides, the library presents an high test coverage.