 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneBatchPAM: A Fast and Frugal K-Medoids Algorithm
Jan 31, 2025



This paper proposes a novel k-medoids approximation algorithm to handle large-scale datasets with reasonable computational time and memory complexity. We develop a local-search algorithm that iteratively improves the medoid selection based on the estimation of the k-medoids objective. A single batch of size m << n provides the estimation, which reduces the required memory size and the number of pairwise dissimilarities computations to O(mn), instead of O(n^2) compared to most k-medoids baselines. We obtain theoretical results highlighting that a batch of size m = O(log(n)) is sufficient to guarantee, with strong probability, the same performance as the original local-search algorithm. Multiple experiments conducted on real datasets of various sizes and dimensions show that our algorithm provides similar performances as state-of-the-art methods such as FasterPAM and BanditPAM++ with a drastically reduced running time.
Maximum Weight Entropy
Sep 27, 2023This paper deals with uncertainty quantification and out-of-distribution detection in deep learning using Bayesian and ensemble methods. It proposes a practical solution to the lack of prediction diversity observed recently for standard approaches when used out-of-distribution (Ovadia et al., 2019; Liu et al., 2021). Considering that this issue is mainly related to a lack of weight diversity, we claim that standard methods sample in "over-restricted" regions of the weight space due to the use of "over-regularization" processes, such as weight decay and zero-mean centered Gaussian priors. We propose to solve the problem by adopting the maximum entropy principle for the weight distribution, with the underlying idea to maximize the weight diversity. Under this paradigm, the epistemic uncertainty is described by the weight distribution of maximal entropy that produces neural networks "consistent" with the training observations. Considering stochastic neural networks, a practical optimization is derived to build such a distribution, defined as a trade-off between the average empirical risk and the weight distribution entropy. We develop a novel weight parameterization for the stochastic model, based on the singular value decomposition of the neural network's hidden representations, which enables a large increase of the weight entropy for a small empirical risk penalization. We provide both theoretical and numerical results to assess the efficiency of the approach. In particular, the proposed algorithm appears in the top three best methods in all configurations of an extensive out-of-distribution detection benchmark including more than thirty competitors.
ADAPT : Awesome Domain Adaptation Python Toolbox
Jul 07, 2021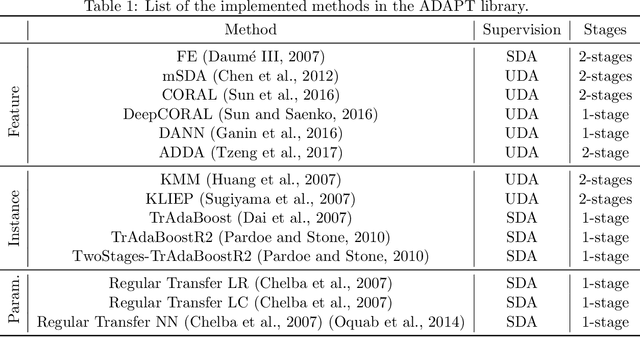
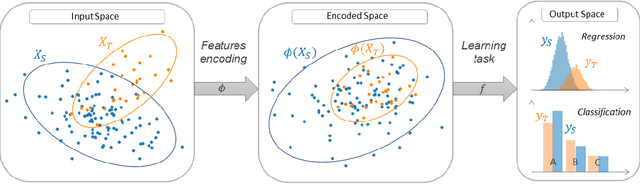
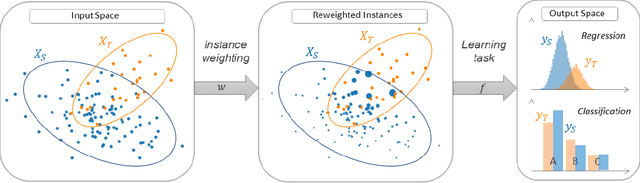
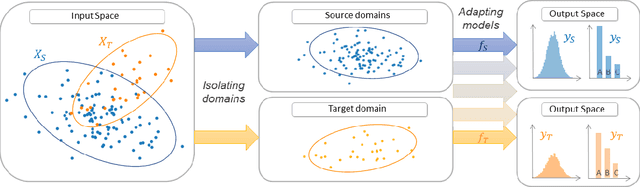
ADAPT is an open-source python library providing the implementation of several domain adaptation methods. The library is suited for scikit-learn estimator object (object which implement fit and predict methods) and tensorflow models. Most of the implemented methods are developed in an estimator agnostic fashion, offering various possibilities adapted to multiple usage. The library offers three modules corresponding to the three principal strategies of domain adaptation: (i) feature-based containing methods performing feature transformation; (ii) instance-based with the implementation of reweighting techniques and (iii) parameter-based proposing methods to adapt pre-trained models to novel observations. A full documentation is proposed online https://adapt-python.github.io/adapt/ with gallery of examples. Besides, the library presents an high test coverage.