 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Engineering Should Track the Epistemic Status and Temporal Validity of Architectural Decisions
Jan 28, 2026This position paper argues that AI-assisted software engineering requires explicit mechanisms for tracking the epistemic status and temporal validity of architectural decisions. LLM coding assistants generate decisions faster than teams can validate them, yet no widely-adopted framework distinguishes conjecture from verified knowledge, prevents trust inflation through conservative aggregation, or detects when evidence expires. We propose three requirements for responsible AI-assisted engineering: (1) epistemic layers that separate unverified hypotheses from empirically validated claims, (2) conservative assurance aggregation grounded in the Gödel t-norm that prevents weak evidence from inflating confidence, and (3) automated evidence decay tracking that surfaces stale assumptions before they cause failures. We formalize these requirements as the First Principles Framework (FPF), ground its aggregation semantics in fuzzy logic, and define a quintet of invariants that any valid aggregation operator must satisfy. Our retrospective audit applying FPF criteria to two internal projects found that 20-25% of architectural decisions had stale evidence within two months, validating the need for temporal accountability. We outline research directions including learnable aggregation operators, federated evidence sharing, and SMT-based claim validation.
Robust Calibration For Improved Weather Prediction Under Distributional Shift
Jan 08, 2024In this paper, we present results on improving out-of-domain weather prediction and uncertainty estimation as part of the \texttt{Shifts Challenge on Robustness and Uncertainty under Real-World Distributional Shift} challenge. We find that by leveraging a mixture of experts in conjunction with an advanced data augmentation technique borrowed from the computer vision domain, in conjunction with robust \textit{post-hoc} calibration of predictive uncertainties, we can potentially achieve more accurate and better-calibrated results with deep neural networks than with boosted tree models for tabular data. We quantify our predictions using several metrics and propose several future lines of inquiry and experimentation to boost performance.
Beyond mirkwood: Enhancing SED Modeling with Conformal Predictions
Dec 21, 2023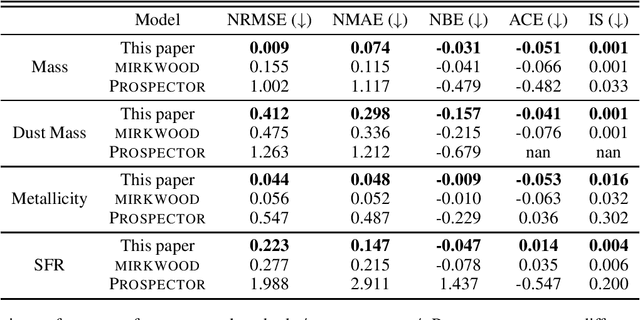
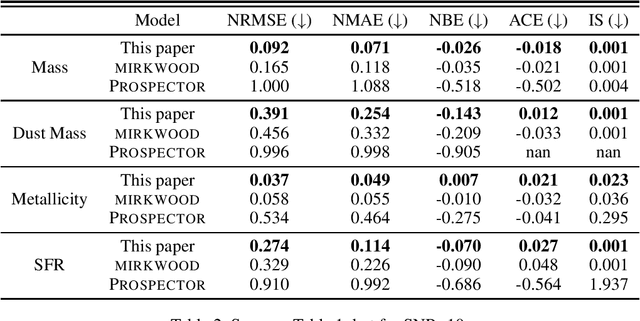
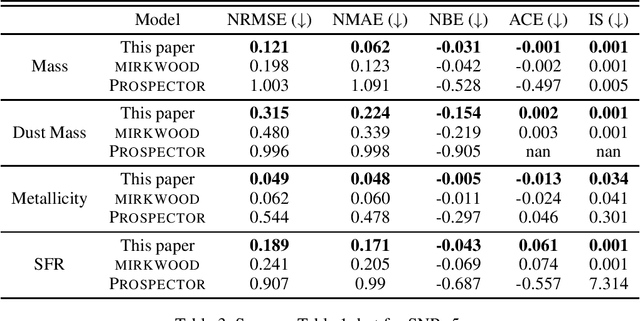
Traditional spectral energy distribution (SED) fitting techniques face uncertainties due to assumptions in star formation histories and dust attenuation curves. We propose an advanced machine learning-based approach that enhances flexibility and uncertainty quantification in SED fitting. Unlike the fixed NGBoost model used in mirkwood, our approach allows for any sklearn-compatible model, including deterministic models. We incorporate conformalized quantile regression to convert point predictions into error bars, enhancing interpretability and reliability. Using CatBoost as the base predictor, we compare results with and without conformal prediction, demonstrating improved performance using metrics such as coverage and interval width. Our method offers a more versatile and accurate tool for deriving galaxy physical properties from observational data.
deep-REMAP: Parameterization of Stellar Spectra Using Regularized Multi-Task Learning
Nov 07, 2023Traditional spectral analysis methods are increasingly challenged by the exploding volumes of data produced by contemporary astronomical surveys. In response, we develop deep-Regularized Ensemble-based Multi-task Learning with Asymmetric Loss for Probabilistic Inference ($\rm{deep-REMAP}$), a novel framework that utilizes the rich synthetic spectra from the PHOENIX library and observational data from the MARVELS survey to accurately predict stellar atmospheric parameters. By harnessing advanced machine learning techniques, including multi-task learning and an innovative asymmetric loss function, $\rm{deep-REMAP}$ demonstrates superior predictive capabilities in determining effective temperature, surface gravity, and metallicity from observed spectra. Our results reveal the framework's effectiveness in extending to other stellar libraries and properties, paving the way for more sophisticated and automated techniques in stellar characterization.
Unsupervised Domain Adaptation for Constraining Star Formation Histories
Dec 28, 2021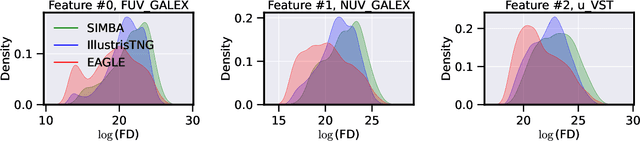
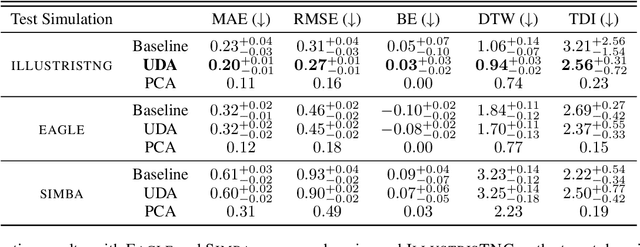
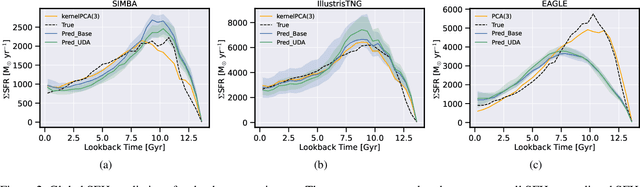
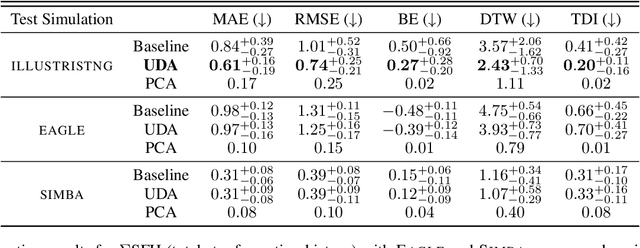
The prevalent paradigm of machine learning today is to use past observations to predict future ones. What if, however, we are interested in knowing the past given the present? This situation is indeed one that astronomers must contend with often. To understand the formation of our universe, we must derive the time evolution of the visible mass content of galaxies. However, to observe a complete star life, one would need to wait for one billion years! To overcome this difficulty, astrophysicists leverage supercomputers and evolve simulated models of galaxies till the current age of the universe, thus establishing a mapping between observed radiation and star formation histories (SFHs). Such ground-truth SFHs are lacking for actual galaxy observations, where they are usually inferred -- with often poor confidence -- from spectral energy distributions (SEDs) using Bayesian fitting methods. In this investigation, we discuss the ability of unsupervised domain adaptation to derive accurate SFHs for galaxies with simulated data as a necessary first step in developing a technique that can ultimately be applied to observational data.
Uncertainty-Aware Learning for Improvements in Image Quality of the Canada-France-Hawaii Telescope
Jun 30, 2021
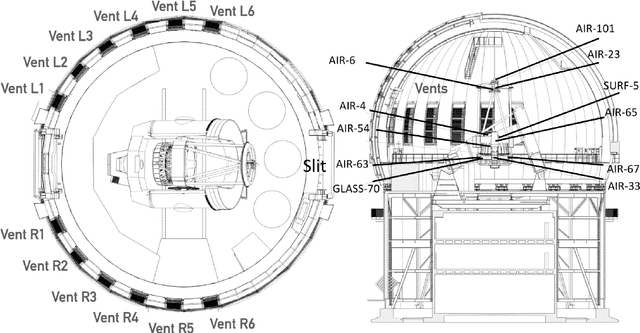


We leverage state-of-the-art machine learning methods and a decade's worth of archival data from the Canada-France-Hawaii Telescope (CFHT) to predict observatory image quality (IQ) from environmental conditions and observatory operating parameters. Specifically, we develop accurate and interpretable models of the complex dependence between data features and observed IQ for CFHT's wide field camera, MegaCam. Our contributions are several-fold. First, we collect, collate and reprocess several disparate data sets gathered by CFHT scientists. Second, we predict probability distribution functions (PDFs) of IQ, and achieve a mean absolute error of $\sim0.07''$ for the predicted medians. Third, we explore data-driven actuation of the 12 dome ``vents'', installed in 2013-14 to accelerate the flushing of hot air from the dome. We leverage epistemic and aleatoric uncertainties in conjunction with probabilistic generative modeling to identify candidate vent adjustments that are in-distribution (ID) and, for the optimal configuration for each ID sample, we predict the reduction in required observing time to achieve a fixed SNR. On average, the reduction is $\sim15\%$. Finally, we rank sensor data features by Shapley values to identify the most predictive variables for each observation. Our long-term goal is to construct reliable and real-time models that can forecast optimal observatory operating parameters for optimization of IQ. Such forecasts can then be fed into scheduling protocols and predictive maintenance routines. We anticipate that such approaches will become standard in automating observatory operations and maintenance by the time CFHT's successor, the Maunakea Spectroscopic Explorer (MSE), is installed in the next decade.
Feature Selection for Better Spectral Characterization or: How I Learned to Start Worrying and Love Ensembles
Feb 22, 2019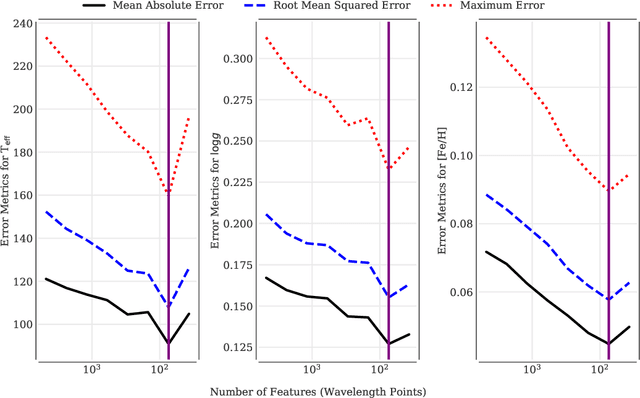
An ever-looming threat to astronomical applications of machine learning is the danger of over-fitting data, also known as the `curse of dimensionality.' This occurs when there are fewer samples than the number of independent variables. In this work, we focus on the problem of stellar parameterization from low-mid resolution spectra, with blended absorption lines. We address this problem using an iterative algorithm to sequentially prune redundant features from synthetic PHOENIX spectra, and arrive at an optimal set of wavelengths with the strongest correlation with each of the output variables -- T$_{\rm eff}$, $\log g$, and [Fe/H]. We find that at any given resolution, most features (i.e., absorption lines) are not only redundant, but actually act as noise and decrease the accuracy of parameter retrieval.