 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut of Style: RAG's Fragility to Linguistic Variation
Apr 11, 2025

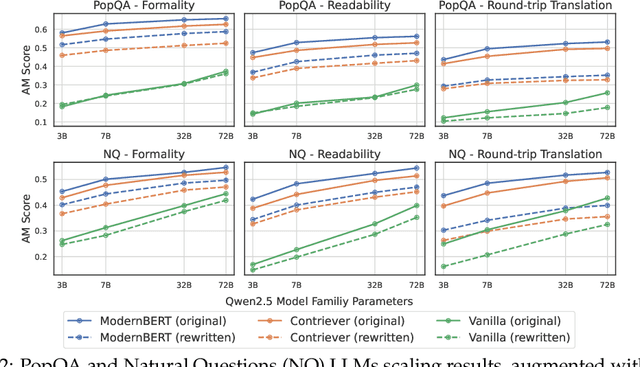
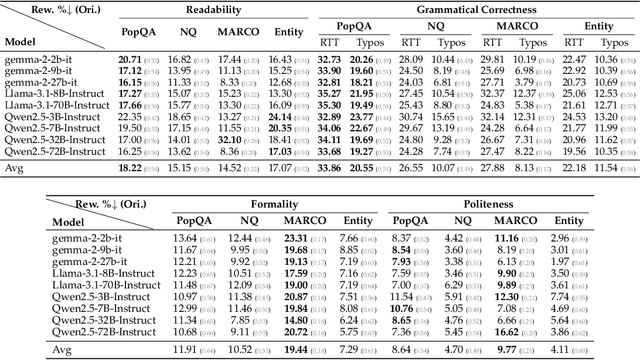
Despite the impressive performance of Retrieval-augmented Generation (RAG) systems across various NLP benchmarks, their robustness in handling real-world user-LLM interaction queries remains largely underexplored. This presents a critical gap for practical deployment, where user queries exhibit greater linguistic variations and can trigger cascading errors across interdependent RAG components. In this work, we systematically analyze how varying four linguistic dimensions (formality, readability, politeness, and grammatical correctness) impact RAG performance. We evaluate two retrieval models and nine LLMs, ranging from 3 to 72 billion parameters, across four information-seeking Question Answering (QA) datasets. Our results reveal that linguistic reformulations significantly impact both retrieval and generation stages, leading to a relative performance drop of up to 40.41% in Recall@5 scores for less formal queries and 38.86% in answer match scores for queries containing grammatical errors. Notably, RAG systems exhibit greater sensitivity to such variations compared to LLM-only generations, highlighting their vulnerability to error propagation due to linguistic shifts. These findings highlight the need for improved robustness techniques to enhance reliability in diverse user interactions.
Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model
Feb 12, 2024
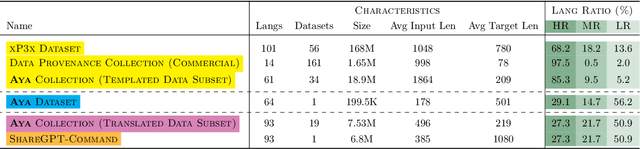
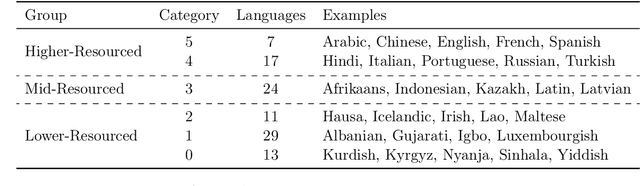

Recent breakthroughs in large language models (LLMs) have centered around a handful of data-rich languages. What does it take to broaden access to breakthroughs beyond first-class citizen languages? Our work introduces Aya, a massively multilingual generative language model that follows instructions in 101 languages of which over 50% are considered as lower-resourced. Aya outperforms mT0 and BLOOMZ on the majority of tasks while covering double the number of languages. We introduce extensive new evaluation suites that broaden the state-of-art for multilingual eval across 99 languages -- including discriminative and generative tasks, human evaluation, and simulated win rates that cover both held-out tasks and in-distribution performance. Furthermore, we conduct detailed investigations on the optimal finetuning mixture composition, data pruning, as well as the toxicity, bias, and safety of our models. We open-source our instruction datasets and our model at https://hf.co/CohereForAI/aya-101
Robust Calibration For Improved Weather Prediction Under Distributional Shift
Jan 08, 2024In this paper, we present results on improving out-of-domain weather prediction and uncertainty estimation as part of the \texttt{Shifts Challenge on Robustness and Uncertainty under Real-World Distributional Shift} challenge. We find that by leveraging a mixture of experts in conjunction with an advanced data augmentation technique borrowed from the computer vision domain, in conjunction with robust \textit{post-hoc} calibration of predictive uncertainties, we can potentially achieve more accurate and better-calibrated results with deep neural networks than with boosted tree models for tabular data. We quantify our predictions using several metrics and propose several future lines of inquiry and experimentation to boost performance.
Lost In Translation: Generating Adversarial Examples Robust to Round-Trip Translation
Jul 24, 2023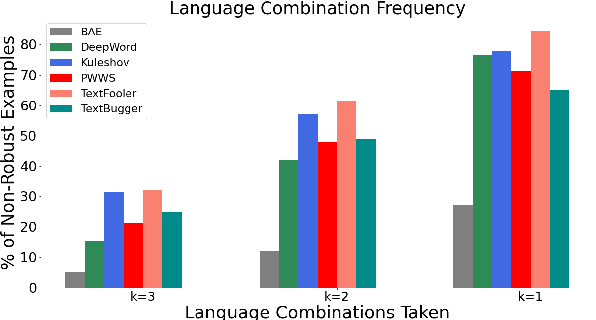

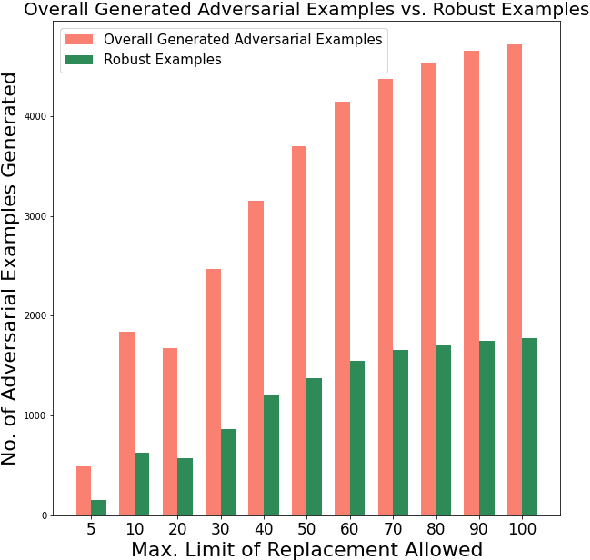
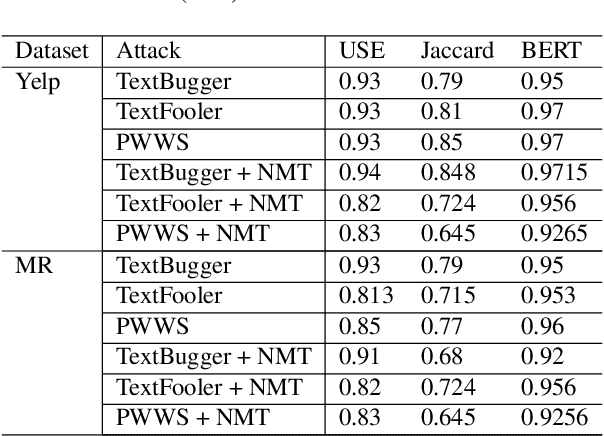
Language Models today provide a high accuracy across a large number of downstream tasks. However, they remain susceptible to adversarial attacks, particularly against those where the adversarial examples maintain considerable similarity to the original text. Given the multilingual nature of text, the effectiveness of adversarial examples across translations and how machine translations can improve the robustness of adversarial examples remain largely unexplored. In this paper, we present a comprehensive study on the robustness of current text adversarial attacks to round-trip translation. We demonstrate that 6 state-of-the-art text-based adversarial attacks do not maintain their efficacy after round-trip translation. Furthermore, we introduce an intervention-based solution to this problem, by integrating Machine Translation into the process of adversarial example generation and demonstrating increased robustness to round-trip translation. Our results indicate that finding adversarial examples robust to translation can help identify the insufficiency of language models that is common across languages, and motivate further research into multilingual adversarial attacks.