 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut of Style: RAG's Fragility to Linguistic Variation
Paper and Code


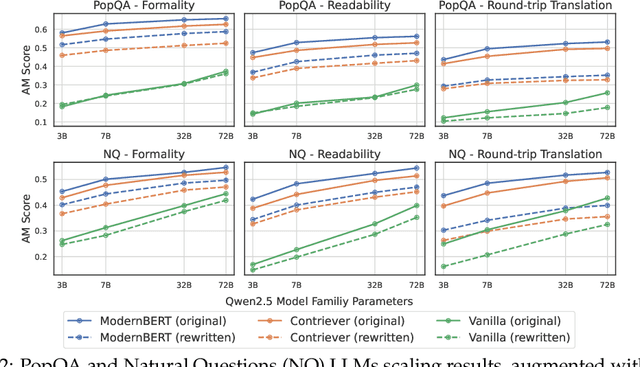
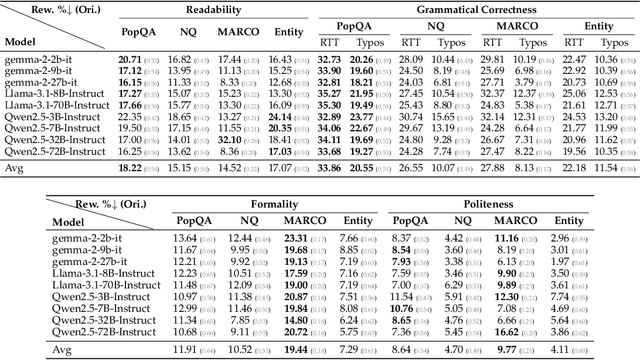
Despite the impressive performance of Retrieval-augmented Generation (RAG) systems across various NLP benchmarks, their robustness in handling real-world user-LLM interaction queries remains largely underexplored. This presents a critical gap for practical deployment, where user queries exhibit greater linguistic variations and can trigger cascading errors across interdependent RAG components. In this work, we systematically analyze how varying four linguistic dimensions (formality, readability, politeness, and grammatical correctness) impact RAG performance. We evaluate two retrieval models and nine LLMs, ranging from 3 to 72 billion parameters, across four information-seeking Question Answering (QA) datasets. Our results reveal that linguistic reformulations significantly impact both retrieval and generation stages, leading to a relative performance drop of up to 40.41% in Recall@5 scores for less formal queries and 38.86% in answer match scores for queries containing grammatical errors. Notably, RAG systems exhibit greater sensitivity to such variations compared to LLM-only generations, highlighting their vulnerability to error propagation due to linguistic shifts. These findings highlight the need for improved robustness techniques to enhance reliability in diverse user interactions.