 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost In Translation: Generating Adversarial Examples Robust to Round-Trip Translation
Paper and Code
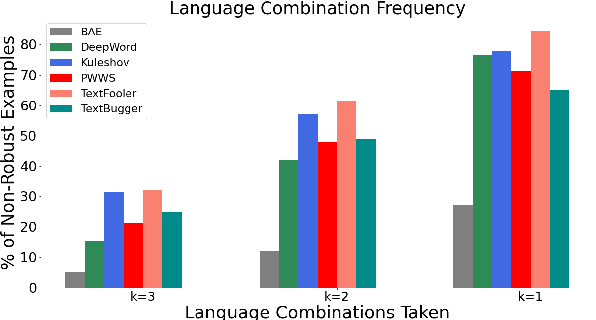

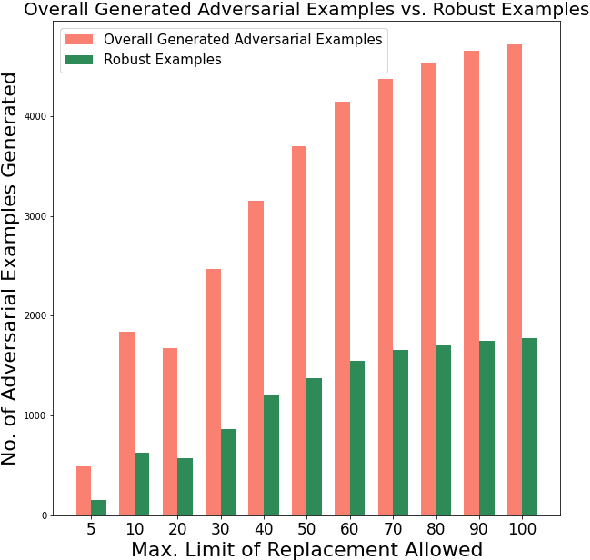
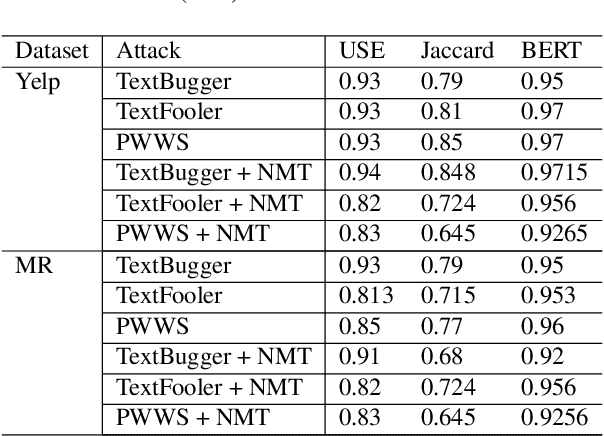
Language Models today provide a high accuracy across a large number of downstream tasks. However, they remain susceptible to adversarial attacks, particularly against those where the adversarial examples maintain considerable similarity to the original text. Given the multilingual nature of text, the effectiveness of adversarial examples across translations and how machine translations can improve the robustness of adversarial examples remain largely unexplored. In this paper, we present a comprehensive study on the robustness of current text adversarial attacks to round-trip translation. We demonstrate that 6 state-of-the-art text-based adversarial attacks do not maintain their efficacy after round-trip translation. Furthermore, we introduce an intervention-based solution to this problem, by integrating Machine Translation into the process of adversarial example generation and demonstrating increased robustness to round-trip translation. Our results indicate that finding adversarial examples robust to translation can help identify the insufficiency of language models that is common across languages, and motivate further research into multilingual adversarial attacks.