 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Learning for Improvements in Image Quality of the Canada-France-Hawaii Telescope
Jun 30, 2021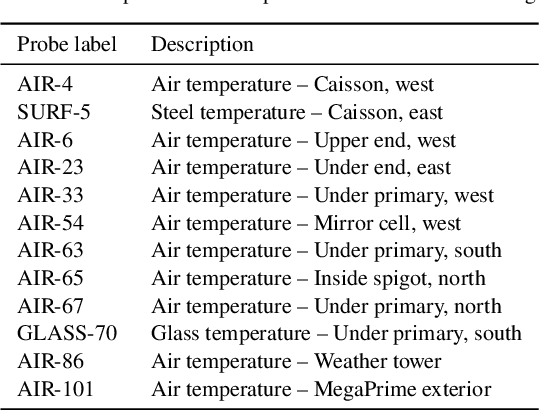
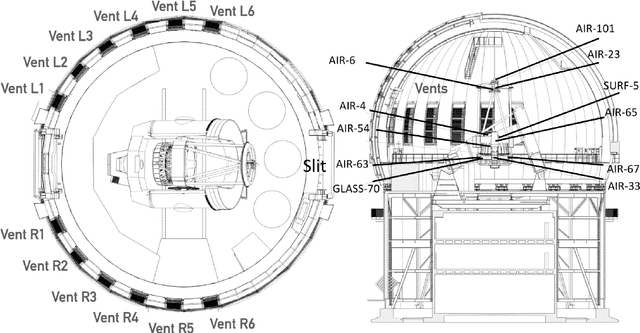


We leverage state-of-the-art machine learning methods and a decade's worth of archival data from the Canada-France-Hawaii Telescope (CFHT) to predict observatory image quality (IQ) from environmental conditions and observatory operating parameters. Specifically, we develop accurate and interpretable models of the complex dependence between data features and observed IQ for CFHT's wide field camera, MegaCam. Our contributions are several-fold. First, we collect, collate and reprocess several disparate data sets gathered by CFHT scientists. Second, we predict probability distribution functions (PDFs) of IQ, and achieve a mean absolute error of $\sim0.07''$ for the predicted medians. Third, we explore data-driven actuation of the 12 dome ``vents'', installed in 2013-14 to accelerate the flushing of hot air from the dome. We leverage epistemic and aleatoric uncertainties in conjunction with probabilistic generative modeling to identify candidate vent adjustments that are in-distribution (ID) and, for the optimal configuration for each ID sample, we predict the reduction in required observing time to achieve a fixed SNR. On average, the reduction is $\sim15\%$. Finally, we rank sensor data features by Shapley values to identify the most predictive variables for each observation. Our long-term goal is to construct reliable and real-time models that can forecast optimal observatory operating parameters for optimization of IQ. Such forecasts can then be fed into scheduling protocols and predictive maintenance routines. We anticipate that such approaches will become standard in automating observatory operations and maintenance by the time CFHT's successor, the Maunakea Spectroscopic Explorer (MSE), is installed in the next decade.
Comparison of Multi-Class and Binary Classification Machine Learning Models in Identifying Strong Gravitational Lenses
Feb 27, 2020
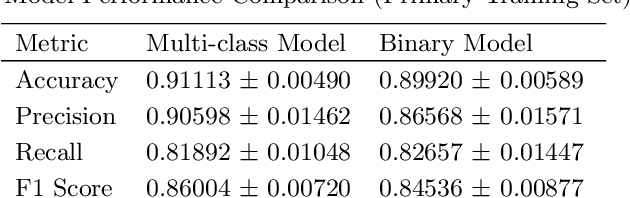
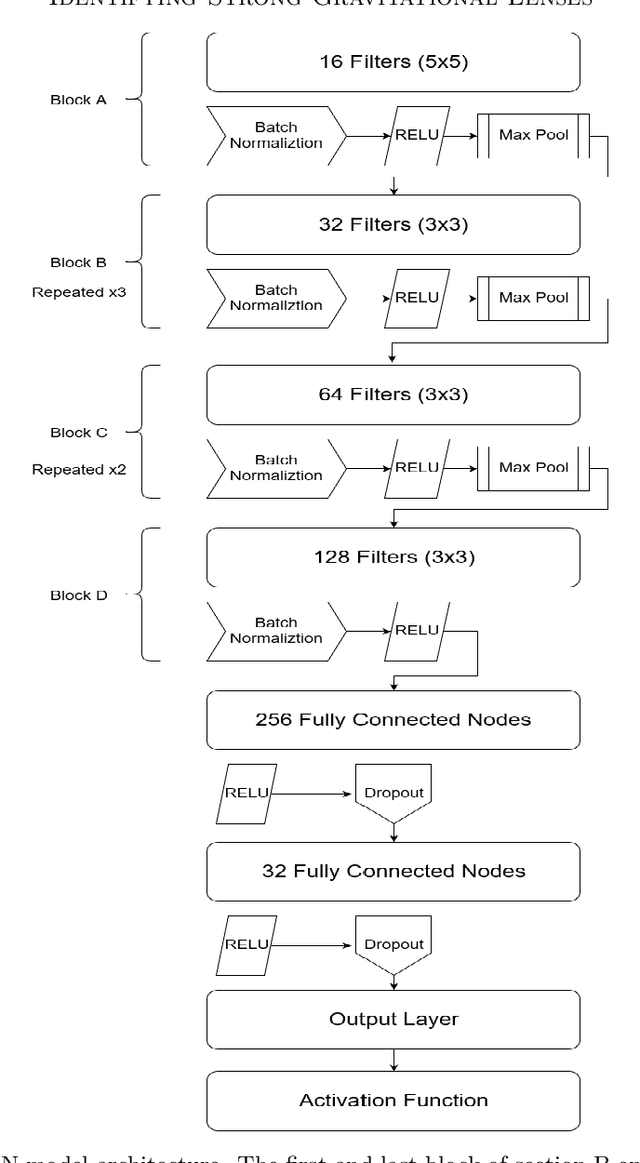
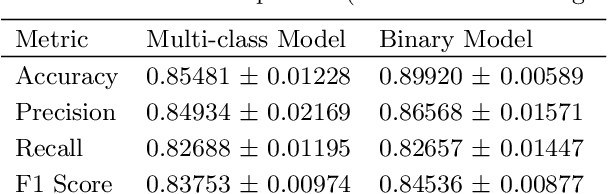
Typically, binary classification lens-finding schemes are used to discriminate between lens candidates and non-lenses. However, these models often suffer from substantial false-positive classifications. Such false positives frequently occur due to images containing objects such as crowded sources, galaxies with arms, and also images with a central source and smaller surrounding sources. Therefore, a model might confuse the stated circumstances with an Einstein ring. It has been proposed that by allowing such commonly misclassified image types to constitute their own classes, machine learning models will more easily be able to learn the difference between images that contain real lenses, and images that contain lens imposters. Using Hubble Space Telescope (HST) images, in the F814W filter, we compare the usage of binary and multi-class classification models applied to the lens finding task. From our findings, we conclude there is not a significant benefit to using the multi-class model over a binary model. We will also present the results of a simple lens search using a multi-class machine learning model, and potential new lens candidates.