 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbeWebAgent: Embedding Web Agents into Any Customized UI
Feb 16, 2026Most web agents operate at the human interface level, observing screenshots or raw DOM trees without application-level access, which limits robustness and action expressiveness. In enterprise settings, however, explicit control of both the frontend and backend is available. We present EmbeWebAgent, a framework for embedding agents directly into existing UIs using lightweight frontend hooks (curated ARIA and URL-based observations, and a per-page function registry exposed via a WebSocket) and a reusable backend workflow that performs reasoning and takes actions. EmbeWebAgent is stack-agnostic (e.g., React or Angular), supports mixed-granularity actions ranging from GUI primitives to higher-level composites, and orchestrates navigation, manipulation, and domain-specific analytics via MCP tools. Our demo shows minimal retrofitting effort and robust multi-step behaviors grounded in a live UI setting. Live Demo: https://youtu.be/Cy06Ljee1JQ
SANPO: A Scene Understanding, Accessibility, Navigation, Pathfinding, Obstacle Avoidance Dataset
Sep 21, 2023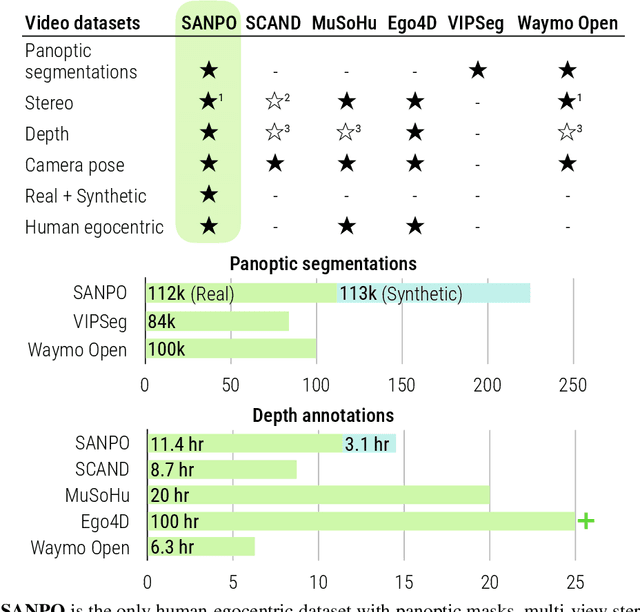
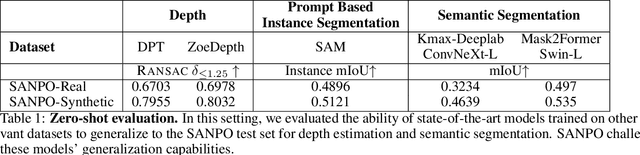
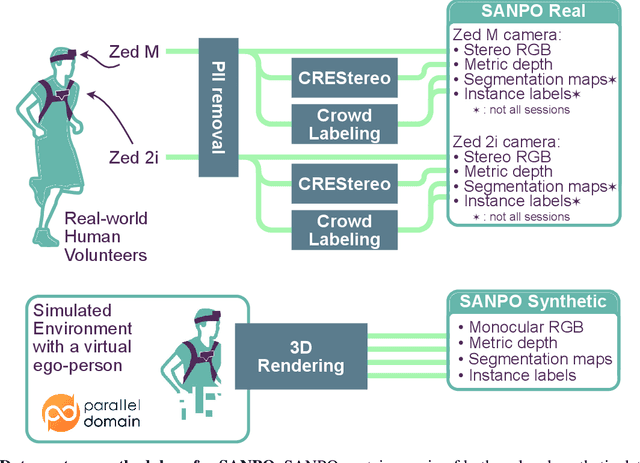
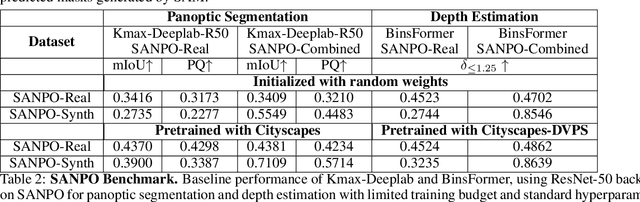
We introduce SANPO, a large-scale egocentric video dataset focused on dense prediction in outdoor environments. It contains stereo video sessions collected across diverse outdoor environments, as well as rendered synthetic video sessions. (Synthetic data was provided by Parallel Domain.) All sessions have (dense) depth and odometry labels. All synthetic sessions and a subset of real sessions have temporally consistent dense panoptic segmentation labels. To our knowledge, this is the first human egocentric video dataset with both large scale dense panoptic segmentation and depth annotations. In addition to the dataset we also provide zero-shot baselines and SANPO benchmarks for future research. We hope that the challenging nature of SANPO will help advance the state-of-the-art in video segmentation, depth estimation, multi-task visual modeling, and synthetic-to-real domain adaptation, while enabling human navigation systems. SANPO is available here: https://google-research-datasets.github.io/sanpo_dataset/
Learning to Get Up
Apr 30, 2022
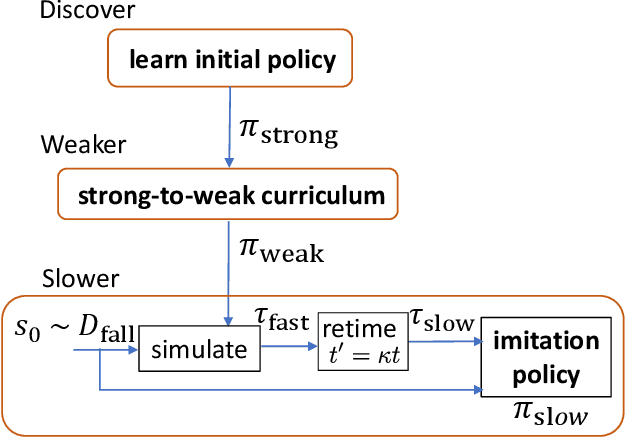
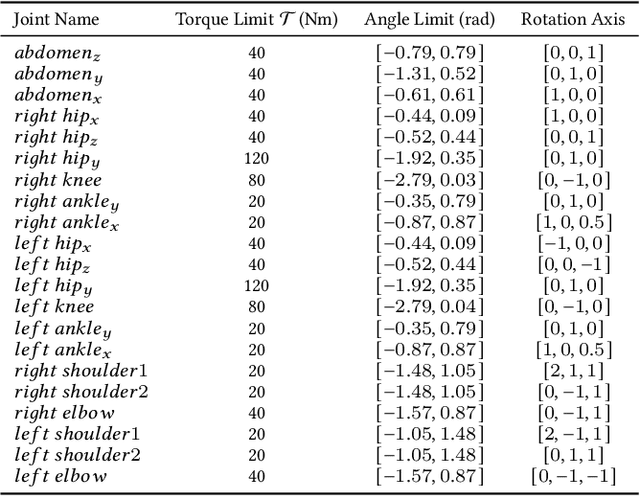
Getting up from an arbitrary fallen state is a basic human skill. Existing methods for learning this skill often generate highly dynamic and erratic get-up motions, which do not resemble human get-up strategies, or are based on tracking recorded human get-up motions. In this paper, we present a staged approach using reinforcement learning, without recourse to motion capture data. The method first takes advantage of a strong character model, which facilitates the discovery of solution modes. A second stage then learns to adapt the control policy to work with progressively weaker versions of the character. Finally, a third stage learns control policies that can reproduce the weaker get-up motions at much slower speeds. We show that across multiple runs, the method can discover a diverse variety of get-up strategies, and execute them at a variety of speeds. The results usually produce policies that use a final stand-up strategy that is common to the recovery motions seen from all initial states. However, we also find policies for which different strategies are seen for prone and supine initial fallen states. The learned get-up control strategies often have significant static stability, i.e., they can be paused at a variety of points during the get-up motion. We further test our method on novel constrained scenarios, such as having a leg and an arm in a cast.
Uncertainty-Aware Learning for Improvements in Image Quality of the Canada-France-Hawaii Telescope
Jun 30, 2021
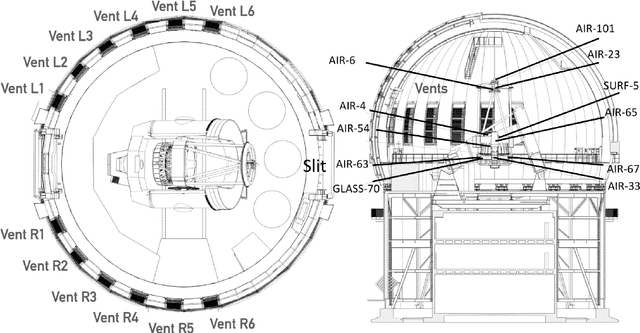


We leverage state-of-the-art machine learning methods and a decade's worth of archival data from the Canada-France-Hawaii Telescope (CFHT) to predict observatory image quality (IQ) from environmental conditions and observatory operating parameters. Specifically, we develop accurate and interpretable models of the complex dependence between data features and observed IQ for CFHT's wide field camera, MegaCam. Our contributions are several-fold. First, we collect, collate and reprocess several disparate data sets gathered by CFHT scientists. Second, we predict probability distribution functions (PDFs) of IQ, and achieve a mean absolute error of $\sim0.07''$ for the predicted medians. Third, we explore data-driven actuation of the 12 dome ``vents'', installed in 2013-14 to accelerate the flushing of hot air from the dome. We leverage epistemic and aleatoric uncertainties in conjunction with probabilistic generative modeling to identify candidate vent adjustments that are in-distribution (ID) and, for the optimal configuration for each ID sample, we predict the reduction in required observing time to achieve a fixed SNR. On average, the reduction is $\sim15\%$. Finally, we rank sensor data features by Shapley values to identify the most predictive variables for each observation. Our long-term goal is to construct reliable and real-time models that can forecast optimal observatory operating parameters for optimization of IQ. Such forecasts can then be fed into scheduling protocols and predictive maintenance routines. We anticipate that such approaches will become standard in automating observatory operations and maintenance by the time CFHT's successor, the Maunakea Spectroscopic Explorer (MSE), is installed in the next decade.
The Safari of Update Structures: Visiting the Lens and Quantum Enclosures
May 12, 2020We build upon our recently introduced concept of an update structure to show that they are a generalisation of very-well-behaved lenses, that is, there is a bijection between a strict subset of update structures and vwb lenses in cartesian categories. We then begin to investigate the zoo of possible update structures. We show that update structures survive decoherence and are sufficiently general to capture quantum observables, pinpointing the additional assumptions required to make the two coincide. In doing so, we shift the focus from dagger-special commutative Frobenius algebras to interacting (co)magma (co)module pairs, showing that the algebraic properties of the (co)multiplication arise from the module-comodule interaction, rather than direct assumptions about the magma comagma pair. Thus this work is of foundational interest as update structures form a strictly more general class of algebraic objects, the taming of which promises to illuminate novel relationships between separately studied mathematical structures.
Categories of Semantic Concepts
Apr 22, 2020Modelling concept representation is a foundational problem in the study of cognition and linguistics. This work builds on the confluence of conceptual tools from Gardenfors semantic spaces, categorical compositional linguistics, and applied category theory to present a domain-independent and categorial formalism of 'concept'.
Learning to Manipulate Object Collections Using Grounded State Representations
Sep 17, 2019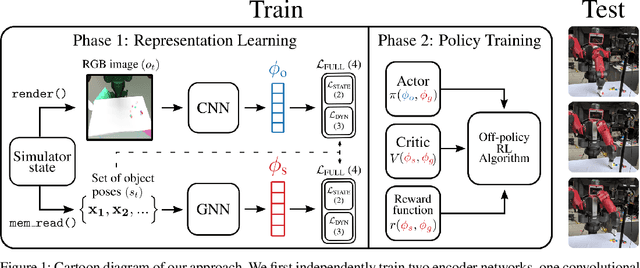
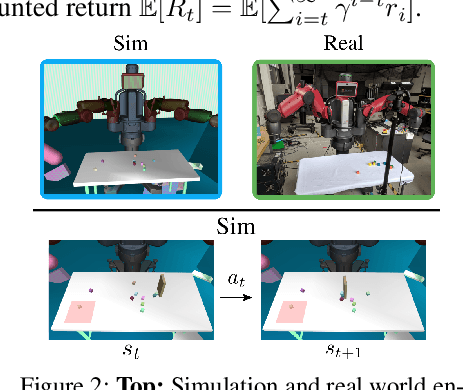

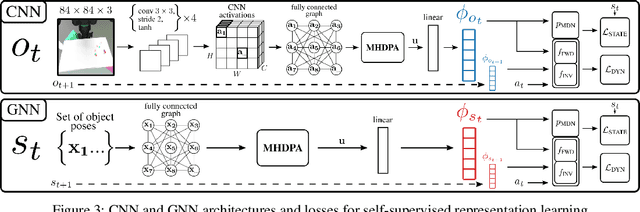
We propose a method for sim-to-real robot learning which exploits simulator state information in a way that scales to many objects. First, we train a pair of encoders on raw object pose targets to learn representations that accurately capture the state information of a multi-object environment. Second, we use these encoders in a reinforcement learning algorithm to train image-based policies capable of manipulating many objects. Our pair of encoders consists of one which consumes RGB images and is used in our policy network, and one which directly consumes a set of raw object poses and is used for reward calculation and value estimation. We evaluate our method on the task of pushing a collection of objects to desired tabletop regions. Compared to methods which rely only on images or use fixed-length state encodings, our method achieves higher success rates, performs well in the real world without fine tuning, and generalizes to different numbers and types of objects not seen during training.