 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Manipulate Object Collections Using Grounded State Representations
Paper and Code
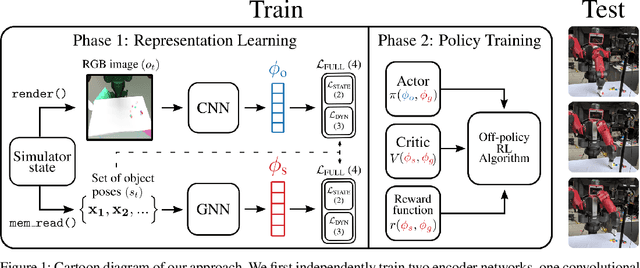
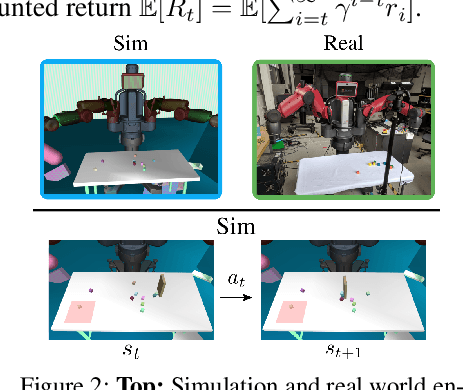

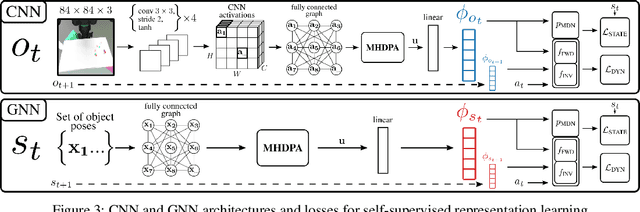
We propose a method for sim-to-real robot learning which exploits simulator state information in a way that scales to many objects. First, we train a pair of encoders on raw object pose targets to learn representations that accurately capture the state information of a multi-object environment. Second, we use these encoders in a reinforcement learning algorithm to train image-based policies capable of manipulating many objects. Our pair of encoders consists of one which consumes RGB images and is used in our policy network, and one which directly consumes a set of raw object poses and is used for reward calculation and value estimation. We evaluate our method on the task of pushing a collection of objects to desired tabletop regions. Compared to methods which rely only on images or use fixed-length state encodings, our method achieves higher success rates, performs well in the real world without fine tuning, and generalizes to different numbers and types of objects not seen during training.