 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection for Better Spectral Characterization or: How I Learned to Start Worrying and Love Ensembles
Paper and Code
Feb 22, 2019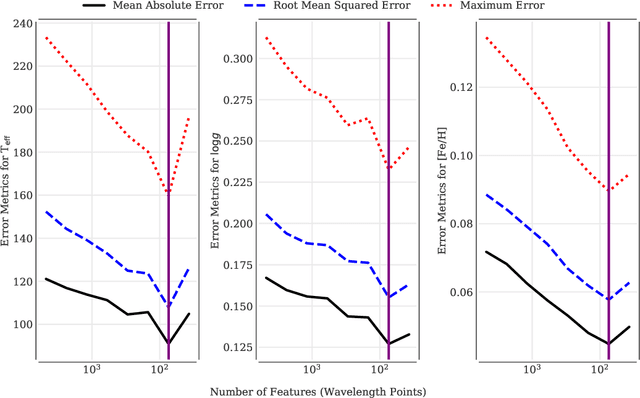
An ever-looming threat to astronomical applications of machine learning is the danger of over-fitting data, also known as the `curse of dimensionality.' This occurs when there are fewer samples than the number of independent variables. In this work, we focus on the problem of stellar parameterization from low-mid resolution spectra, with blended absorption lines. We address this problem using an iterative algorithm to sequentially prune redundant features from synthetic PHOENIX spectra, and arrive at an optimal set of wavelengths with the strongest correlation with each of the output variables -- T$_{\rm eff}$, $\log g$, and [Fe/H]. We find that at any given resolution, most features (i.e., absorption lines) are not only redundant, but actually act as noise and decrease the accuracy of parameter retrieval.