 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Anti-Regularized Ensembles provide reliable out-of-distribution uncertainty quantification
Apr 08, 2023



We consider the problem of uncertainty quantification in high dimensional regression and classification for which deep ensemble have proven to be promising methods. Recent observations have shown that deep ensemble often return overconfident estimates outside the training domain, which is a major limitation because shifted distributions are often encountered in real-life scenarios. The principal challenge for this problem is to solve the trade-off between increasing the diversity of the ensemble outputs and making accurate in-distribution predictions. In this work, we show that an ensemble of networks with large weights fitting the training data are likely to meet these two objectives. We derive a simple and practical approach to produce such ensembles, based on an original anti-regularization term penalizing small weights and a control process of the weight increase which maintains the in-distribution loss under an acceptable threshold. The developed approach does not require any out-of-distribution training data neither any trade-off hyper-parameter calibration. We derive a theoretical framework for this approach and show that the proposed optimization can be seen as a "water-filling" problem. Several experiments in both regression and classification settings highlight that Deep Anti-Regularized Ensembles (DARE) significantly improve uncertainty quantification outside the training domain in comparison to recent deep ensembles and out-of-distribution detection methods. All the conducted experiments are reproducible and the source code is available at \url{https://github.com/antoinedemathelin/DARE}.
Fast and Accurate Importance Weighting for Correcting Sample Bias
Sep 09, 2022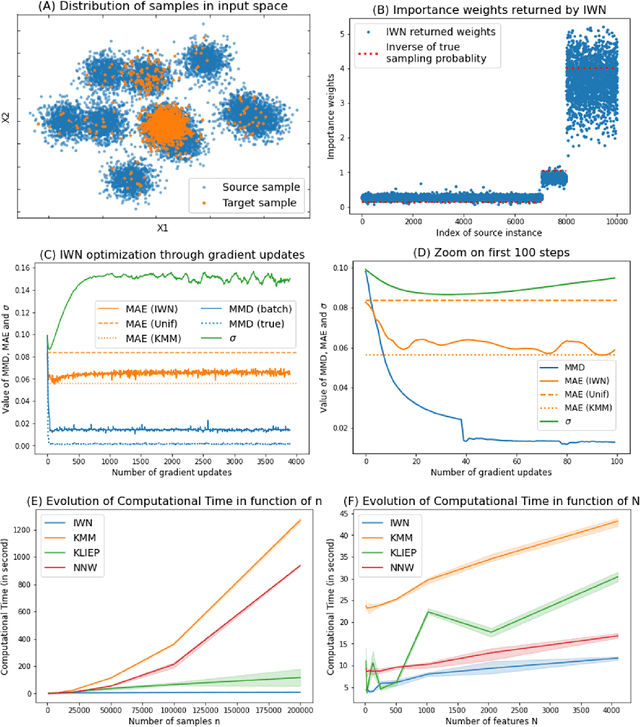
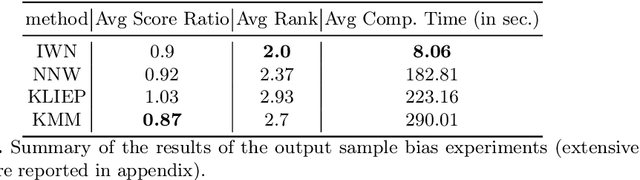
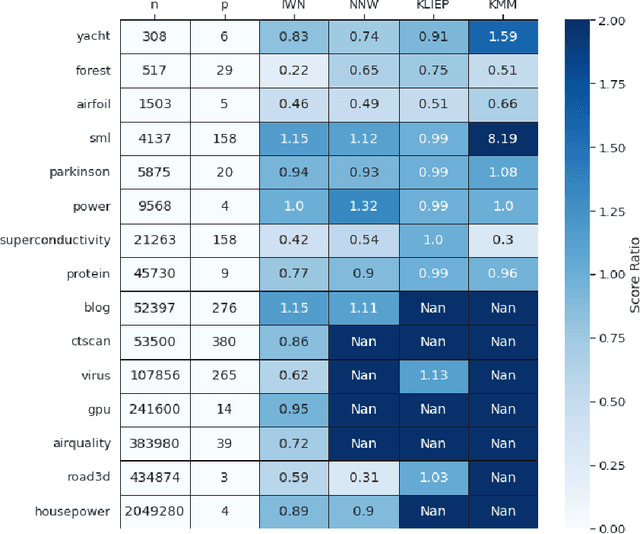
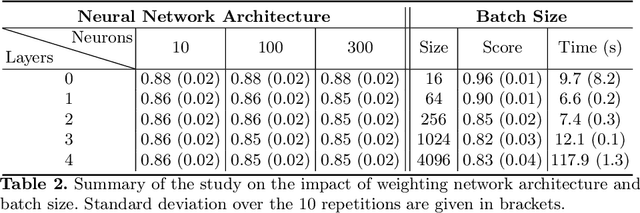
Bias in datasets can be very detrimental for appropriate statistical estimation. In response to this problem, importance weighting methods have been developed to match any biased distribution to its corresponding target unbiased distribution. The seminal Kernel Mean Matching (KMM) method is, nowadays, still considered as state of the art in this research field. However, one of the main drawbacks of this method is the computational burden for large datasets. Building on previous works by Huang et al. (2007) and de Mathelin et al. (2021), we derive a novel importance weighting algorithm which scales to large datasets by using a neural network to predict the instance weights. We show, on multiple public datasets, under various sample biases, that our proposed approach drastically reduces the computational time on large dataset while maintaining similar sample bias correction performance compared to other importance weighting methods. The proposed approach appears to be the only one able to give relevant reweighting in a reasonable time for large dataset with up to two million data.