 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Accurate Importance Weighting for Correcting Sample Bias
Paper and Code
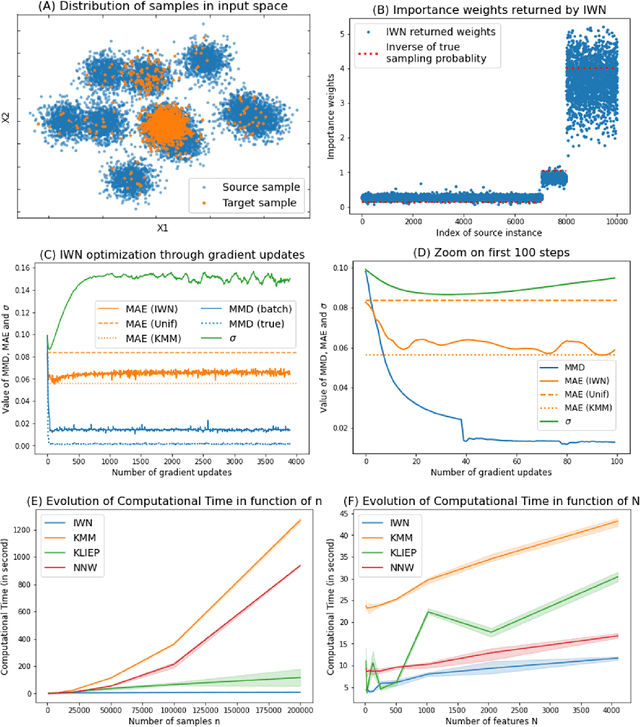
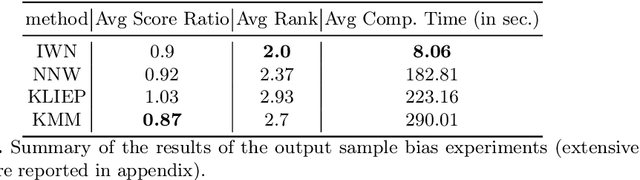
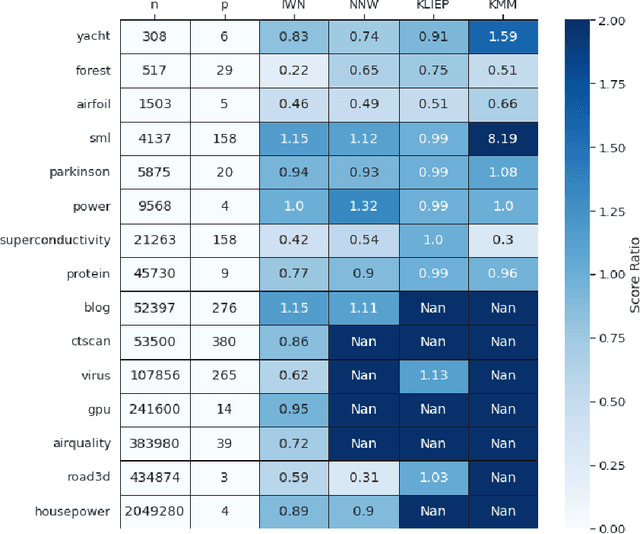
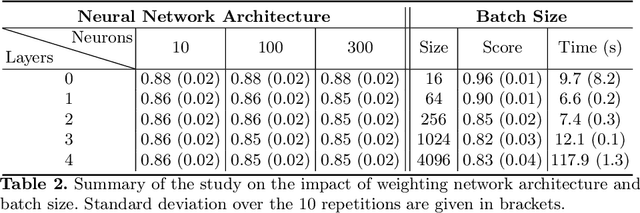
Bias in datasets can be very detrimental for appropriate statistical estimation. In response to this problem, importance weighting methods have been developed to match any biased distribution to its corresponding target unbiased distribution. The seminal Kernel Mean Matching (KMM) method is, nowadays, still considered as state of the art in this research field. However, one of the main drawbacks of this method is the computational burden for large datasets. Building on previous works by Huang et al. (2007) and de Mathelin et al. (2021), we derive a novel importance weighting algorithm which scales to large datasets by using a neural network to predict the instance weights. We show, on multiple public datasets, under various sample biases, that our proposed approach drastically reduces the computational time on large dataset while maintaining similar sample bias correction performance compared to other importance weighting methods. The proposed approach appears to be the only one able to give relevant reweighting in a reasonable time for large dataset with up to two million data.