 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer by layer, module by module: Choose both for optimal OOD probing of ViT
Mar 05, 2026Recent studies have observed that intermediate layers of foundation models often yield more discriminative representations than the final layer. While initially attributed to autoregressive pretraining, this phenomenon has also been identified in models trained via supervised and discriminative self-supervised objectives. In this paper, we conduct a comprehensive study to analyze the behavior of intermediate layers in pretrained vision transformers. Through extensive linear probing experiments across a diverse set of image classification benchmarks, we find that distribution shift between pretraining and downstream data is the primary cause of performance degradation in deeper layers. Furthermore, we perform a fine-grained analysis at the module level. Our findings reveal that standard probing of transformer block outputs is suboptimal; instead, probing the activation within the feedforward network yields the best performance under significant distribution shift, whereas the normalized output of the multi-head self-attention module is optimal when the shift is weak.
Vision Transformer Finetuning Benefits from Non-Smooth Components
Feb 09, 2026The smoothness of the transformer architecture has been extensively studied in the context of generalization, training stability, and adversarial robustness. However, its role in transfer learning remains poorly understood. In this paper, we analyze the ability of vision transformer components to adapt their outputs to changes in inputs, or, in other words, their plasticity. Defined as an average rate of change, it captures the sensitivity to input perturbation; in particular, a high plasticity implies low smoothness. We demonstrate through theoretical analysis and comprehensive experiments that this perspective provides principled guidance in choosing the components to prioritize during adaptation. A key takeaway for practitioners is that the high plasticity of the attention modules and feedforward layers consistently leads to better finetuning performance. Our findings depart from the prevailing assumption that smoothness is desirable, offering a novel perspective on the functional properties of transformers. The code is available at https://github.com/ambroiseodt/vit-plasticity.
Optimal Self-Consistency for Efficient Reasoning with Large Language Models
Nov 15, 2025



Self-consistency (SC) is a widely used test-time inference technique for improving performance in chain-of-thought reasoning. It involves generating multiple responses, or samples from a large language model (LLM) and selecting the most frequent answer. This procedure can naturally be viewed as a majority vote or empirical mode estimation. Despite its effectiveness, SC is prohibitively expensive at scale when naively applied to datasets, and it lacks a unified theoretical treatment of sample efficiency and scaling behavior. In this paper, we provide the first comprehensive analysis of SC's scaling behavior and its variants, drawing on mode estimation and voting theory. We derive and empirically validate power law scaling for self-consistency across datasets, and analyze the sample efficiency for fixed-allocation and dynamic-allocation sampling schemes. From these insights, we introduce Blend-ASC, a novel variant of self-consistency that dynamically allocates samples to questions during inference, achieving state-of-the-art sample efficiency. Our approach uses 6.8x fewer samples than vanilla SC on average, outperforming both fixed- and dynamic-allocation SC baselines, thereby demonstrating the superiority of our approach in terms of efficiency. In contrast to existing variants, Blend-ASC is hyperparameter-free and can fit an arbitrary sample budget, ensuring it can be easily applied to any self-consistency application.
Provable Benefits of In-Tool Learning for Large Language Models
Aug 28, 2025



Tool-augmented language models, equipped with retrieval, memory, or external APIs, are reshaping AI, yet their theoretical advantages remain underexplored. In this paper, we address this question by demonstrating the benefits of in-tool learning (external retrieval) over in-weight learning (memorization) for factual recall. We show that the number of facts a model can memorize solely in its weights is fundamentally limited by its parameter count. In contrast, we prove that tool-use enables unbounded factual recall via a simple and efficient circuit construction. These results are validated in controlled experiments, where tool-using models consistently outperform memorizing ones. We further show that for pretrained large language models, teaching tool-use and general rules is more effective than finetuning facts into memory. Our work provides both a theoretical and empirical foundation, establishing why tool-augmented workflows are not just practical, but provably more scalable.
Easing Optimization Paths: a Circuit Perspective
Jan 04, 2025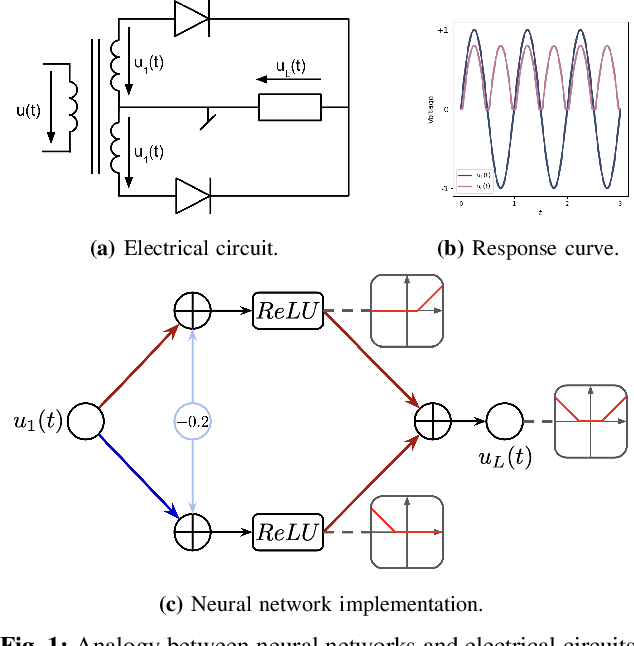
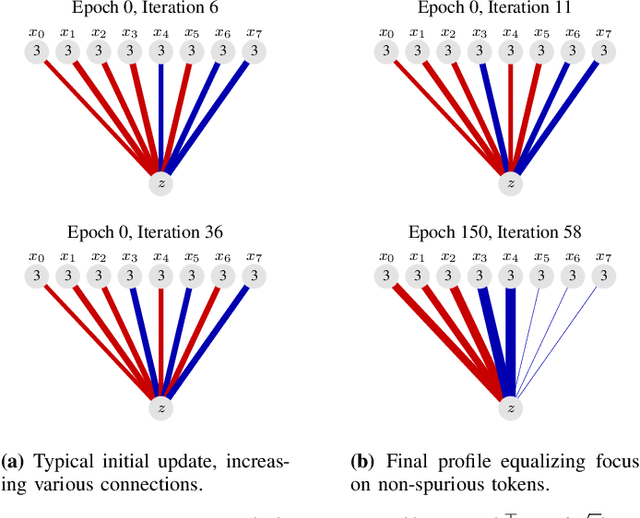
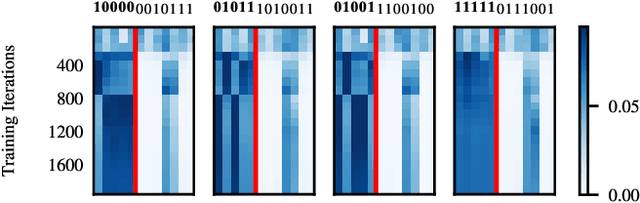
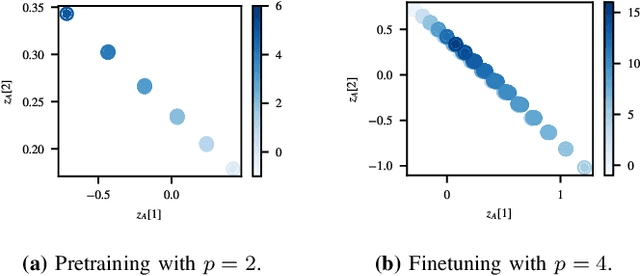
Gradient descent is the method of choice for training large artificial intelligence systems. As these systems become larger, a better understanding of the mechanisms behind gradient training would allow us to alleviate compute costs and help steer these systems away from harmful behaviors. To that end, we suggest utilizing the circuit perspective brought forward by mechanistic interpretability. After laying out our intuition, we illustrate how it enables us to design a curriculum for efficient learning in a controlled setting. The code is available at \url{https://github.com/facebookresearch/pal}.
A Visual Case Study of the Training Dynamics in Neural Networks
Oct 31, 2024



This paper introduces a visual sandbox designed to explore the training dynamics of a small-scale transformer model, with the embedding dimension constrained to $d=2$. This restriction allows for a comprehensive two-dimensional visualization of each layer's dynamics. Through this approach, we gain insights into training dynamics, circuit transferability, and the causes of loss spikes, including those induced by the high curvature of normalization layers. We propose strategies to mitigate these spikes, demonstrating how good visualization facilitates the design of innovative ideas of practical interest. Additionally, we believe our sandbox could assist theoreticians in assessing essential training dynamics mechanisms and integrating them into future theories. The code is available at https://github.com/facebookresearch/pal.
Zero-shot Model-based Reinforcement Learning using Large Language Models
Oct 15, 2024



The emerging zero-shot capabilities of Large Language Models (LLMs) have led to their applications in areas extending well beyond natural language processing tasks. In reinforcement learning, while LLMs have been extensively used in text-based environments, their integration with continuous state spaces remains understudied. In this paper, we investigate how pre-trained LLMs can be leveraged to predict in context the dynamics of continuous Markov decision processes. We identify handling multivariate data and incorporating the control signal as key challenges that limit the potential of LLMs' deployment in this setup and propose Disentangled In-Context Learning (DICL) to address them. We present proof-of-concept applications in two reinforcement learning settings: model-based policy evaluation and data-augmented off-policy reinforcement learning, supported by theoretical analysis of the proposed methods. Our experiments further demonstrate that our approach produces well-calibrated uncertainty estimates. We release the code at https://github.com/abenechehab/dicl.
Large Language Models as Markov Chains
Oct 03, 2024



Large language models (LLMs) have proven to be remarkably efficient, both across a wide range of natural language processing tasks and well beyond them. However, a comprehensive theoretical analysis of the origins of their impressive performance remains elusive. In this paper, we approach this challenging task by drawing an equivalence between generic autoregressive language models with vocabulary of size $T$ and context window of size $K$ and Markov chains defined on a finite state space of size $\mathcal{O}(T^K)$. We derive several surprising findings related to the existence of a stationary distribution of Markov chains that capture the inference power of LLMs, their speed of convergence to it, and the influence of the temperature on the latter. We then prove pre-training and in-context generalization bounds and show how the drawn equivalence allows us to enrich their interpretation. Finally, we illustrate our theoretical guarantees with experiments on several recent LLMs to highlight how they capture the behavior observed in practice.
SKADA-Bench: Benchmarking Unsupervised Domain Adaptation Methods with Realistic Validation
Jul 16, 2024



Unsupervised Domain Adaptation (DA) consists of adapting a model trained on a labeled source domain to perform well on an unlabeled target domain with some data distribution shift. While many methods have been proposed in the literature, fair and realistic evaluation remains an open question, particularly due to methodological difficulties in selecting hyperparameters in the unsupervised setting. With SKADA-Bench, we propose a framework to evaluate DA methods and present a fair evaluation of existing shallow algorithms, including reweighting, mapping, and subspace alignment. Realistic hyperparameter selection is performed with nested cross-validation and various unsupervised model selection scores, on both simulated datasets with controlled shifts and real-world datasets across diverse modalities, such as images, text, biomedical, and tabular data with specific feature extraction. Our benchmark highlights the importance of realistic validation and provides practical guidance for real-life applications, with key insights into the choice and impact of model selection approaches. SKADA-Bench is open-source, reproducible, and can be easily extended with novel DA methods, datasets, and model selection criteria without requiring re-evaluating competitors. SKADA-Bench is available on GitHub at https://github.com/scikit-adaptation/skada-bench.
Analysing Multi-Task Regression via Random Matrix Theory with Application to Time Series Forecasting
Jun 14, 2024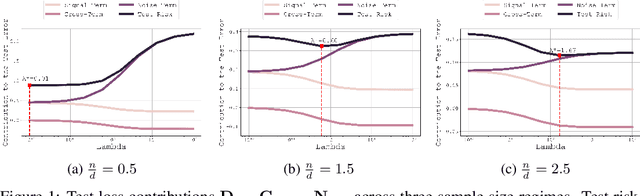
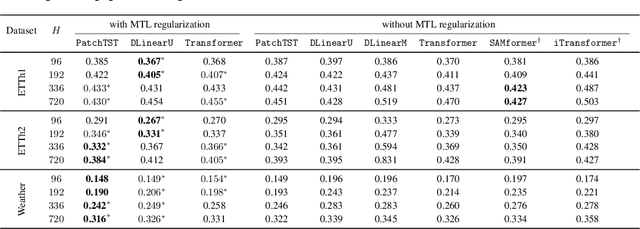
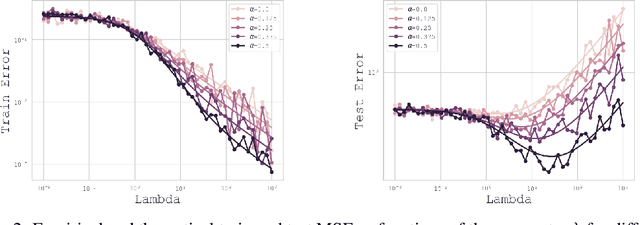
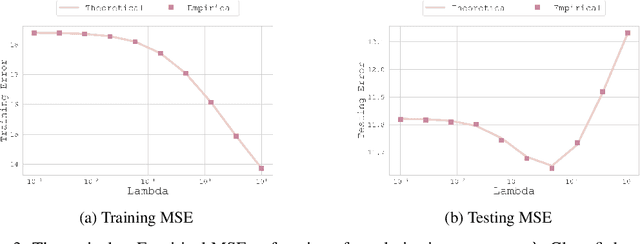
In this paper, we introduce a novel theoretical framework for multi-task regression, applying random matrix theory to provide precise performance estimations, under high-dimensional, non-Gaussian data distributions. We formulate a multi-task optimization problem as a regularization technique to enable single-task models to leverage multi-task learning information. We derive a closed-form solution for multi-task optimization in the context of linear models. Our analysis provides valuable insights by linking the multi-task learning performance to various model statistics such as raw data covariances, signal-generating hyperplanes, noise levels, as well as the size and number of datasets. We finally propose a consistent estimation of training and testing errors, thereby offering a robust foundation for hyperparameter optimization in multi-task regression scenarios. Experimental validations on both synthetic and real-world datasets in regression and multivariate time series forecasting demonstrate improvements on univariate models, incorporating our method into the training loss and thus leveraging multivariate information.