 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs as In-Context Meta-Learners for Model and Hyperparameter Selection
Oct 30, 2025



Model and hyperparameter selection are critical but challenging in machine learning, typically requiring expert intuition or expensive automated search. We investigate whether large language models (LLMs) can act as in-context meta-learners for this task. By converting each dataset into interpretable metadata, we prompt an LLM to recommend both model families and hyperparameters. We study two prompting strategies: (1) a zero-shot mode relying solely on pretrained knowledge, and (2) a meta-informed mode augmented with examples of models and their performance on past tasks. Across synthetic and real-world benchmarks, we show that LLMs can exploit dataset metadata to recommend competitive models and hyperparameters without search, and that improvements from meta-informed prompting demonstrate their capacity for in-context meta-learning. These results highlight a promising new role for LLMs as lightweight, general-purpose assistants for model selection and hyperparameter optimization.
TAG: A Decentralized Framework for Multi-Agent Hierarchical Reinforcement Learning
Feb 21, 2025



Hierarchical organization is fundamental to biological systems and human societies, yet artificial intelligence systems often rely on monolithic architectures that limit adaptability and scalability. Current hierarchical reinforcement learning (HRL) approaches typically restrict hierarchies to two levels or require centralized training, which limits their practical applicability. We introduce TAME Agent Framework (TAG), a framework for constructing fully decentralized hierarchical multi-agent systems.TAG enables hierarchies of arbitrary depth through a novel LevelEnv concept, which abstracts each hierarchy level as the environment for the agents above it. This approach standardizes information flow between levels while preserving loose coupling, allowing for seamless integration of diverse agent types. We demonstrate the effectiveness of TAG by implementing hierarchical architectures that combine different RL agents across multiple levels, achieving improved performance over classical multi-agent RL baselines on standard benchmarks. Our results show that decentralized hierarchical organization enhances both learning speed and final performance, positioning TAG as a promising direction for scalable multi-agent systems.
Zero-shot Model-based Reinforcement Learning using Large Language Models
Oct 15, 2024



The emerging zero-shot capabilities of Large Language Models (LLMs) have led to their applications in areas extending well beyond natural language processing tasks. In reinforcement learning, while LLMs have been extensively used in text-based environments, their integration with continuous state spaces remains understudied. In this paper, we investigate how pre-trained LLMs can be leveraged to predict in context the dynamics of continuous Markov decision processes. We identify handling multivariate data and incorporating the control signal as key challenges that limit the potential of LLMs' deployment in this setup and propose Disentangled In-Context Learning (DICL) to address them. We present proof-of-concept applications in two reinforcement learning settings: model-based policy evaluation and data-augmented off-policy reinforcement learning, supported by theoretical analysis of the proposed methods. Our experiments further demonstrate that our approach produces well-calibrated uncertainty estimates. We release the code at https://github.com/abenechehab/dicl.
A call for embodied AI
Feb 06, 2024We propose Embodied AI as the next fundamental step in the pursuit of Artificial General Intelligence, juxtaposing it against current AI advancements, particularly Large Language Models. We traverse the evolution of the embodiment concept across diverse fields - philosophy, psychology, neuroscience, and robotics - to highlight how EAI distinguishes itself from the classical paradigm of static learning. By broadening the scope of Embodied AI, we introduce a theoretical framework based on cognitive architectures, emphasizing perception, action, memory, and learning as essential components of an embodied agent. This framework is aligned with Friston's active inference principle, offering a comprehensive approach to EAI development. Despite the progress made in the field of AI, substantial challenges, such as the formulation of a novel AI learning theory and the innovation of advanced hardware, persist. Our discussion lays down a foundational guideline for future Embodied AI research. Highlighting the importance of creating Embodied AI agents capable of seamless communication, collaboration, and coexistence with humans and other intelligent entities within real-world environments, we aim to steer the AI community towards addressing the multifaceted challenges and seizing the opportunities that lie ahead in the quest for AGI.
Deep autoregressive density nets vs neural ensembles for model-based offline reinforcement learning
Feb 05, 2024

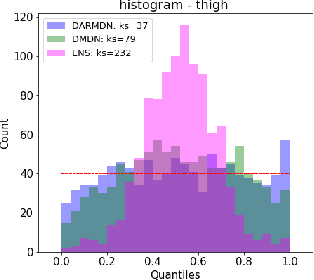

We consider the problem of offline reinforcement learning where only a set of system transitions is made available for policy optimization. Following recent advances in the field, we consider a model-based reinforcement learning algorithm that infers the system dynamics from the available data and performs policy optimization on imaginary model rollouts. This approach is vulnerable to exploiting model errors which can lead to catastrophic failures on the real system. The standard solution is to rely on ensembles for uncertainty heuristics and to avoid exploiting the model where it is too uncertain. We challenge the popular belief that we must resort to ensembles by showing that better performance can be obtained with a single well-calibrated autoregressive model on the D4RL benchmark. We also analyze static metrics of model-learning and conclude on the important model properties for the final performance of the agent.
A Multi-step Loss Function for Robust Learning of the Dynamics in Model-based Reinforcement Learning
Feb 05, 2024In model-based reinforcement learning, most algorithms rely on simulating trajectories from one-step models of the dynamics learned on data. A critical challenge of this approach is the compounding of one-step prediction errors as the length of the trajectory grows. In this paper we tackle this issue by using a multi-step objective to train one-step models. Our objective is a weighted sum of the mean squared error (MSE) loss at various future horizons. We find that this new loss is particularly useful when the data is noisy (additive Gaussian noise in the observations), which is often the case in real-life environments. To support the multi-step loss, first we study its properties in two tractable cases: i) uni-dimensional linear system, and ii) two-parameter non-linear system. Second, we show in a variety of tasks (environments or datasets) that the models learned with this loss achieve a significant improvement in terms of the averaged R2-score on future prediction horizons. Finally, in the pure batch reinforcement learning setting, we demonstrate that one-step models serve as strong baselines when dynamics are deterministic, while multi-step models would be more advantageous in the presence of noise, highlighting the potential of our approach in real-world applications.
Multi-timestep models for Model-based Reinforcement Learning
Oct 11, 2023In model-based reinforcement learning (MBRL), most algorithms rely on simulating trajectories from one-step dynamics models learned on data. A critical challenge of this approach is the compounding of one-step prediction errors as length of the trajectory grows. In this paper we tackle this issue by using a multi-timestep objective to train one-step models. Our objective is a weighted sum of a loss function (e.g., negative log-likelihood) at various future horizons. We explore and test a range of weights profiles. We find that exponentially decaying weights lead to models that significantly improve the long-horizon R2 score. This improvement is particularly noticeable when the models were evaluated on noisy data. Finally, using a soft actor-critic (SAC) agent in pure batch reinforcement learning (RL) and iterated batch RL scenarios, we found that our multi-timestep models outperform or match standard one-step models. This was especially evident in a noisy variant of the considered environment, highlighting the potential of our approach in real-world applications.
Guided Safe Shooting: model based reinforcement learning with safety constraints
Jun 20, 2022
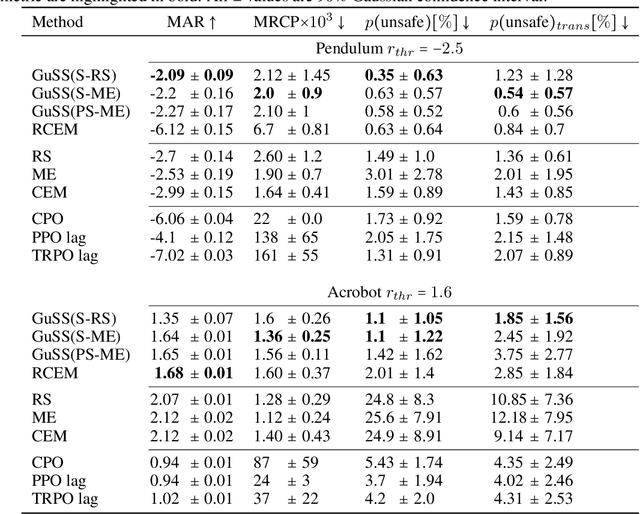

In the last decade, reinforcement learning successfully solved complex control tasks and decision-making problems, like the Go board game. Yet, there are few success stories when it comes to deploying those algorithms to real-world scenarios. One of the reasons is the lack of guarantees when dealing with and avoiding unsafe states, a fundamental requirement in critical control engineering systems. In this paper, we introduce Guided Safe Shooting (GuSS), a model-based RL approach that can learn to control systems with minimal violations of the safety constraints. The model is learned on the data collected during the operation of the system in an iterated batch fashion, and is then used to plan for the best action to perform at each time step. We propose three different safe planners, one based on a simple random shooting strategy and two based on MAP-Elites, a more advanced divergent-search algorithm. Experiments show that these planners help the learning agent avoid unsafe situations while maximally exploring the state space, a necessary aspect when learning an accurate model of the system. Furthermore, compared to model-free approaches, learning a model allows GuSS reducing the number of interactions with the real-system while still reaching high rewards, a fundamental requirement when handling engineering systems.
Knothe-Rosenblatt transport for Unsupervised Domain Adaptation
Oct 06, 2021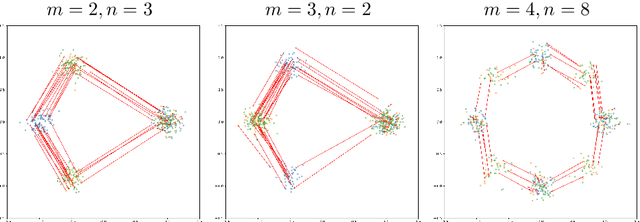
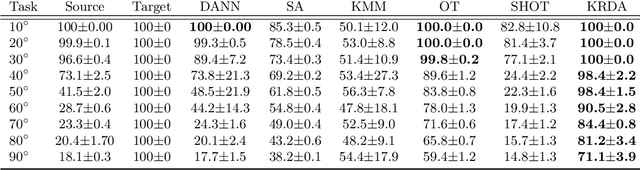
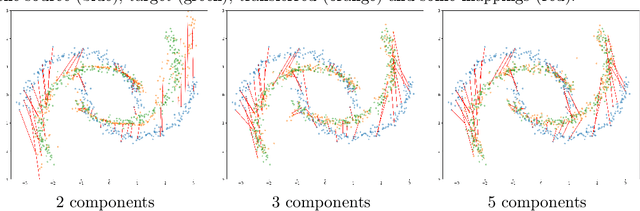
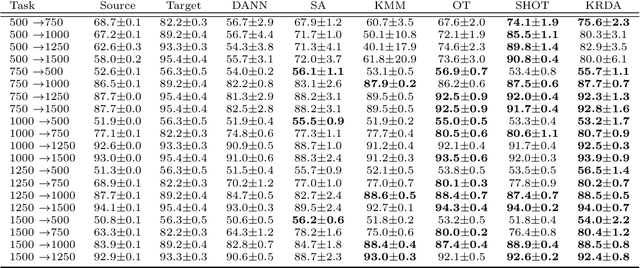
Unsupervised domain adaptation (UDA) aims at exploiting related but different data sources to tackle a common task in a target domain. UDA remains a central yet challenging problem in machine learning. In this paper, we present an approach tailored to moderate-dimensional tabular problems which are hugely important in industrial applications and less well-served by the plethora of methods designed for image and language data. Knothe-Rosenblatt Domain Adaptation (KRDA) is based on the Knothe-Rosenblatt transport: we exploit autoregressive density estimation algorithms to accurately model the different sources by an autoregressive model using a mixture of Gaussians. KRDA then takes advantage of the triangularity of the autoregressive models to build an explicit mapping of the source samples into the target domain. We show that the transfer map built by KRDA preserves each component quantiles of the observations, hence aligning the representations of the different data sets in the same target domain. Finally, we show that KRDA has state-of-the-art performance on both synthetic and real world UDA problems.
Model-based micro-data reinforcement learning: what are the crucial model properties and which model to choose?
Jul 24, 2021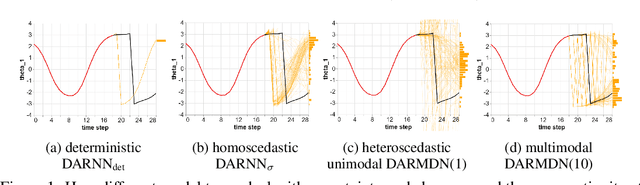
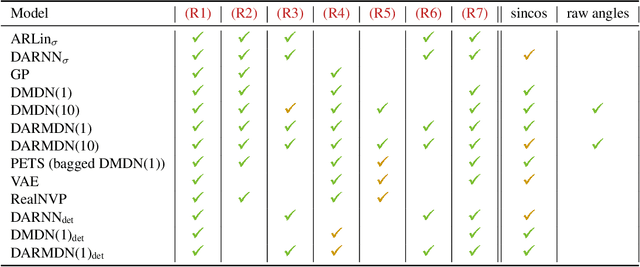

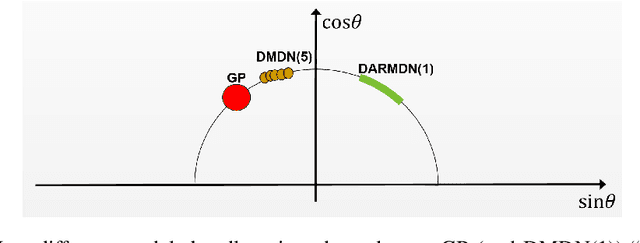
We contribute to micro-data model-based reinforcement learning (MBRL) by rigorously comparing popular generative models using a fixed (random shooting) control agent. We find that on an environment that requires multimodal posterior predictives, mixture density nets outperform all other models by a large margin. When multimodality is not required, our surprising finding is that we do not need probabilistic posterior predictives: deterministic models are on par, in fact they consistently (although non-significantly) outperform their probabilistic counterparts. We also found that heteroscedasticity at training time, perhaps acting as a regularizer, improves predictions at longer horizons. At the methodological side, we design metrics and an experimental protocol which can be used to evaluate the various models, predicting their asymptotic performance when using them on the control problem. Using this framework, we improve the state-of-the-art sample complexity of MBRL on Acrobot by two to four folds, using an aggressive training schedule which is outside of the hyperparameter interval usually considered