 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Pruner: Self-Adaptive Context Pruning for Coding Agents
Jan 23, 2026LLM agents have demonstrated remarkable capabilities in software development, but their performance is hampered by long interaction contexts, which incur high API costs and latency. While various context compression approaches such as LongLLMLingua have emerged to tackle this challenge, they typically rely on fixed metrics such as PPL, ignoring the task-specific nature of code understanding. As a result, they frequently disrupt syntactic and logical structure and fail to retain critical implementation details. In this paper, we propose SWE-Pruner, a self-adaptive context pruning framework tailored for coding agents. Drawing inspiration from how human programmers "selectively skim" source code during development and debugging, SWE-Pruner performs task-aware adaptive pruning for long contexts. Given the current task, the agent formulates an explicit goal (e.g., "focus on error handling") as a hint to guide the pruning targets. A lightweight neural skimmer (0.6B parameters) is trained to dynamically select relevant lines from the surrounding context given the goal. Evaluations across four benchmarks and multiple models validate SWE-Pruner's effectiveness in various scenarios, achieving 23-54% token reduction on agent tasks like SWE-Bench Verified and up to 14.84x compression on single-turn tasks like LongCodeQA with minimal performance impact.
Reasoning in Trees: Improving Retrieval-Augmented Generation for Multi-Hop Question Answering
Jan 16, 2026Retrieval-Augmented Generation (RAG) has demonstrated significant effectiveness in enhancing large language models (LLMs) for complex multi-hop question answering (QA). For multi-hop QA tasks, current iterative approaches predominantly rely on LLMs to self-guide and plan multi-step exploration paths during retrieval, leading to substantial challenges in maintaining reasoning coherence across steps from inaccurate query decomposition and error propagation. To address these issues, we introduce Reasoning Tree Guided RAG (RT-RAG), a novel hierarchical framework for complex multi-hop QA. RT-RAG systematically decomposes multi-hop questions into explicit reasoning trees, minimizing inaccurate decomposition through structured entity analysis and consensus-based tree selection that clearly separates core queries, known entities, and unknown entities. Subsequently, a bottom-up traversal strategy employs iterative query rewriting and refinement to collect high-quality evidence, thereby mitigating error propagation. Comprehensive experiments show that RT-RAG substantially outperforms state-of-the-art methods by 7.0% F1 and 6.0% EM, demonstrating the effectiveness of RT-RAG in complex multi-hop QA.
Tropical Cyclone Track Forecasting using Fused Deep Learning from Aligned Reanalysis Data
Oct 23, 2019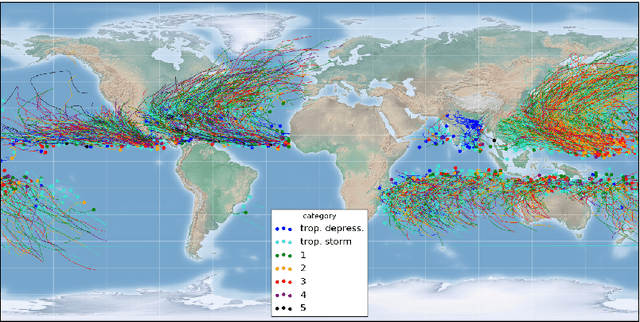
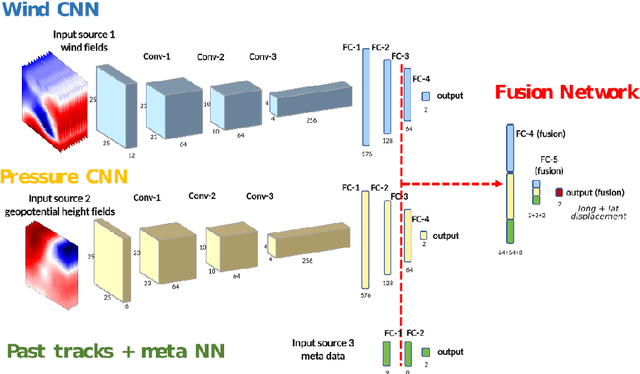

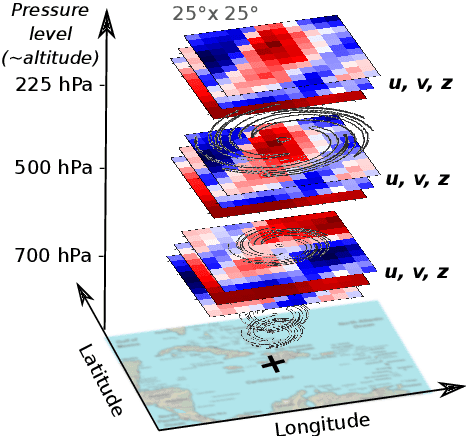
The forecast of tropical cyclone trajectories is crucial for the protection of people and property. Although forecast dynamical models can provide high-precision short-term forecasts, they are computationally demanding, and current statistical forecasting models have much room for improvement given that the database of past hurricanes is constantly growing. Machine learning methods, that can capture non-linearities and complex relations, have only been scarcely tested for this application. We propose a neural network model fusing past trajectory data and reanalysis atmospheric images (wind and pressure 3D fields). We use a moving frame of reference that follows the storm center for the 24h tracking forecast. The network is trained to estimate the longitude and latitude displacement of tropical cyclones and depressions from a large database from both hemispheres (more than 3000 storms since 1979, sampled at a 6 hour frequency). The advantage of the fused network is demonstrated and a comparison with current forecast models shows that deep learning methods could provide a valuable and complementary prediction. Moreover, our method can give a forecast for a new storm in a few seconds, which is an important asset for real-time forecasts compared to traditional forecasts.