 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Unsupervised Domain Adaptation for Time Series Classification: a Benchmark
Dec 18, 2023



Unsupervised Domain Adaptation (UDA) aims to harness labeled source data to train models for unlabeled target data. Despite extensive research in domains like computer vision and natural language processing, UDA remains underexplored for time series data, which has widespread real-world applications ranging from medicine and manufacturing to earth observation and human activity recognition. Our paper addresses this gap by introducing a comprehensive benchmark for evaluating UDA techniques for time series classification, with a focus on deep learning methods. We provide seven new benchmark datasets covering various domain shifts and temporal dynamics, facilitating fair and standardized UDA method assessments with state of the art neural network backbones (e.g. Inception) for time series data. This benchmark offers insights into the strengths and limitations of the evaluated approaches while preserving the unsupervised nature of domain adaptation, making it directly applicable to practical problems. Our paper serves as a vital resource for researchers and practitioners, advancing domain adaptation solutions for time series data and fostering innovation in this critical field. The implementation code of this benchmark is available at https://github.com/EricssonResearch/UDA-4-TSC.
Knothe-Rosenblatt transport for Unsupervised Domain Adaptation
Oct 06, 2021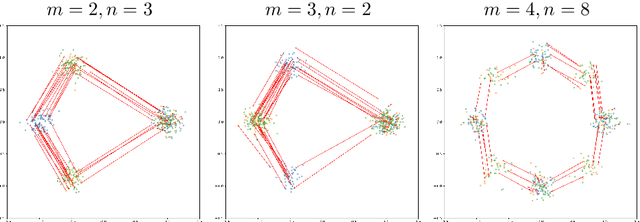
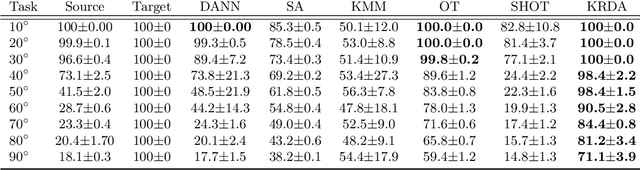
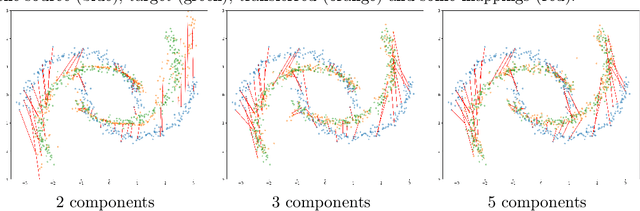
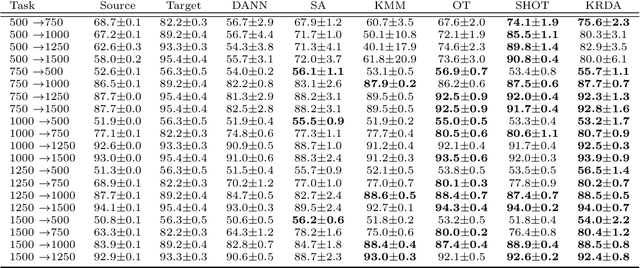
Unsupervised domain adaptation (UDA) aims at exploiting related but different data sources to tackle a common task in a target domain. UDA remains a central yet challenging problem in machine learning. In this paper, we present an approach tailored to moderate-dimensional tabular problems which are hugely important in industrial applications and less well-served by the plethora of methods designed for image and language data. Knothe-Rosenblatt Domain Adaptation (KRDA) is based on the Knothe-Rosenblatt transport: we exploit autoregressive density estimation algorithms to accurately model the different sources by an autoregressive model using a mixture of Gaussians. KRDA then takes advantage of the triangularity of the autoregressive models to build an explicit mapping of the source samples into the target domain. We show that the transfer map built by KRDA preserves each component quantiles of the observations, hence aligning the representations of the different data sets in the same target domain. Finally, we show that KRDA has state-of-the-art performance on both synthetic and real world UDA problems.