 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Prompts with English Tools: A Benchmark
Jan 08, 2026Large Language Models (LLMs) are now integral to numerous industries, increasingly serving as the core reasoning engine for autonomous agents that perform complex tasks through tool-use. While the development of Arabic-native LLMs is accelerating, the benchmarks for evaluating their capabilities lag behind, with most existing frameworks focusing on English. A critical and overlooked area is tool-calling, where the performance of models prompted in non-English languages like Arabic is poorly understood, especially since these models are often pretrained on predominantly English data. This paper addresses this critical gap by introducing the first dedicated benchmark for evaluating the tool-calling and agentic capabilities of LLMs in the Arabic language. Our work provides a standardized framework to measure the functional accuracy and robustness of models in Arabic agentic workflows. Our findings reveal a huge performance gap: when users interact in Arabic, tool-calling accuracy drops by an average of 5-10\%, regardless of whether the tool descriptions themselves are in Arabic or English. By shedding light on these critical challenges, this benchmark aims to foster the development of more reliable and linguistically equitable AI agents for Arabic-speaking users.
Deep Unsupervised Domain Adaptation for Time Series Classification: a Benchmark
Dec 18, 2023



Unsupervised Domain Adaptation (UDA) aims to harness labeled source data to train models for unlabeled target data. Despite extensive research in domains like computer vision and natural language processing, UDA remains underexplored for time series data, which has widespread real-world applications ranging from medicine and manufacturing to earth observation and human activity recognition. Our paper addresses this gap by introducing a comprehensive benchmark for evaluating UDA techniques for time series classification, with a focus on deep learning methods. We provide seven new benchmark datasets covering various domain shifts and temporal dynamics, facilitating fair and standardized UDA method assessments with state of the art neural network backbones (e.g. Inception) for time series data. This benchmark offers insights into the strengths and limitations of the evaluated approaches while preserving the unsupervised nature of domain adaptation, making it directly applicable to practical problems. Our paper serves as a vital resource for researchers and practitioners, advancing domain adaptation solutions for time series data and fostering innovation in this critical field. The implementation code of this benchmark is available at https://github.com/EricssonResearch/UDA-4-TSC.
ShapeDBA: Generating Effective Time Series Prototypes using ShapeDTW Barycenter Averaging
Sep 28, 2023



Time series data can be found in almost every domain, ranging from the medical field to manufacturing and wireless communication. Generating realistic and useful exemplars and prototypes is a fundamental data analysis task. In this paper, we investigate a novel approach to generating realistic and useful exemplars and prototypes for time series data. Our approach uses a new form of time series average, the ShapeDTW Barycentric Average. We therefore turn our attention to accurately generating time series prototypes with a novel approach. The existing time series prototyping approaches rely on the Dynamic Time Warping (DTW) similarity measure such as DTW Barycentering Average (DBA) and SoftDBA. These last approaches suffer from a common problem of generating out-of-distribution artifacts in their prototypes. This is mostly caused by the DTW variant used and its incapability of detecting neighborhood similarities, instead it detects absolute similarities. Our proposed method, ShapeDBA, uses the ShapeDTW variant of DTW, that overcomes this issue. We chose time series clustering, a popular form of time series analysis to evaluate the outcome of ShapeDBA compared to the other prototyping approaches. Coupled with the k-means clustering algorithm, and evaluated on a total of 123 datasets from the UCR archive, our proposed averaging approach is able to achieve new state-of-the-art results in terms of Adjusted Rand Index.
Deep learning for time series classification
Oct 01, 2020



Time series analysis is a field of data science which is interested in analyzing sequences of numerical values ordered in time. Time series are particularly interesting because they allow us to visualize and understand the evolution of a process over time. Their analysis can reveal trends, relationships and similarities across the data. There exists numerous fields containing data in the form of time series: health care (electrocardiogram, blood sugar, etc.), activity recognition, remote sensing, finance (stock market price), industry (sensors), etc. Time series classification consists of constructing algorithms dedicated to automatically label time series data. The sequential aspect of time series data requires the development of algorithms that are able to harness this temporal property, thus making the existing off-the-shelf machine learning models for traditional tabular data suboptimal for solving the underlying task. In this context, deep learning has emerged in recent years as one of the most effective methods for tackling the supervised classification task, particularly in the field of computer vision. The main objective of this thesis was to study and develop deep neural networks specifically constructed for the classification of time series data. We thus carried out the first large scale experimental study allowing us to compare the existing deep methods and to position them compared other non-deep learning based state-of-the-art methods. Subsequently, we made numerous contributions in this area, notably in the context of transfer learning, data augmentation, ensembling and adversarial attacks. Finally, we have also proposed a novel architecture, based on the famous Inception network (Google), which ranks among the most efficient to date.
InceptionTime: Finding AlexNet for Time Series Classification
Sep 13, 2019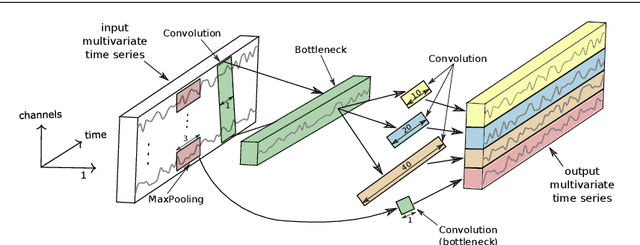
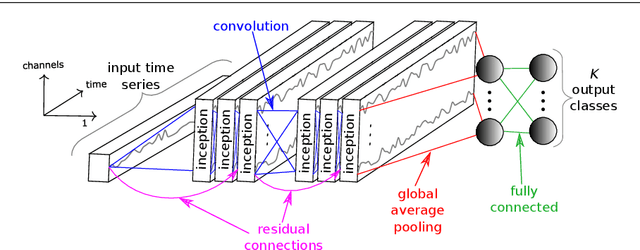
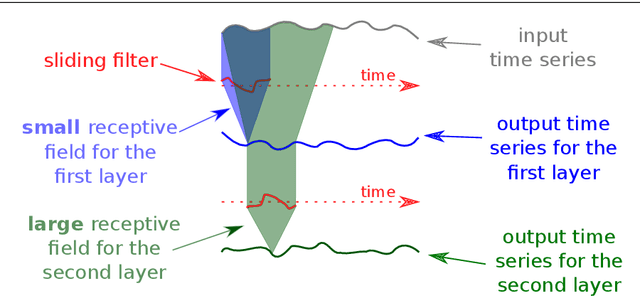
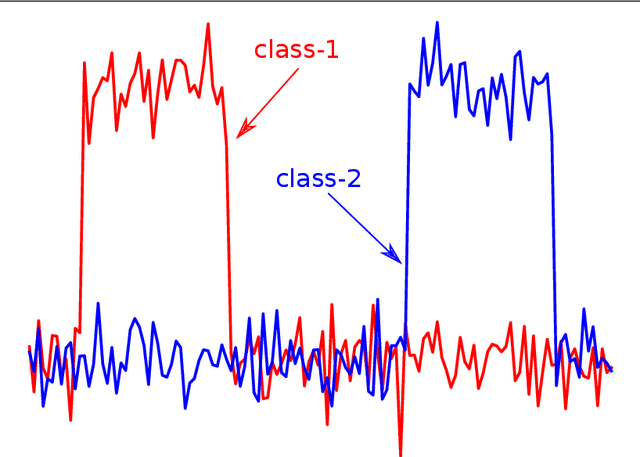
Time series classification (TSC) is the area of machine learning interested in learning how to assign labels to time series. The last few decades of work in this area have led to significant progress in the accuracy of classifiers, with the state of the art now represented by the HIVE-COTE algorithm. While extremely accurate, HIVE-COTE is infeasible to use in many applications because of its very high training time complexity in O(N^2*T^4) for a dataset with N time series of length T. For example, it takes HIVE-COTE more than 72,000s to learn from a small dataset with N=700 time series of short length T=46. Deep learning, on the other hand, has now received enormous attention because of its high scalability and state-of-the-art accuracy in computer vision and natural language processing tasks. Deep learning for TSC has only very recently started to be explored, with the first few architectures developed over the last 3 years only. The accuracy of deep learning for TSC has been raised to a competitive level, but has not quite reached the level of HIVE-COTE. This is what this paper achieves: outperforming HIVE-COTE's accuracy together with scalability. We take an important step towards finding the AlexNet network for TSC by presenting InceptionTime---an ensemble of deep Convolutional Neural Network (CNN) models, inspired by the Inception-v4 architecture. Our experiments show that InceptionTime slightly outperforms HIVE-COTE with a win/draw/loss on the UCR archive of 40/6/39. Not only is InceptionTime more accurate, but it is much faster: InceptionTime learns from that same dataset with 700 time series in 2,300s but can also learn from a dataset with 8M time series in 13 hours, a quantity of data that is fully out of reach of HIVE-COTE.
Accurate and interpretable evaluation of surgical skills from kinematic data using fully convolutional neural networks
Aug 20, 2019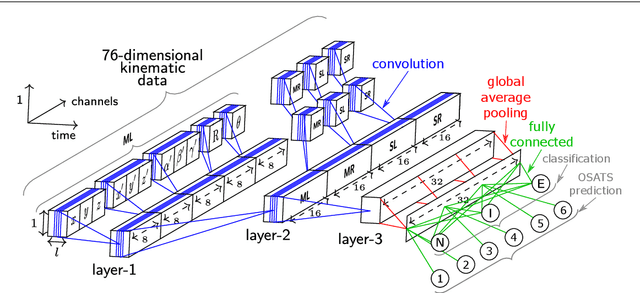
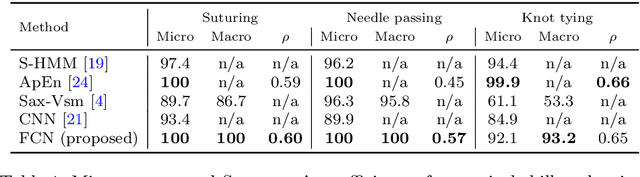
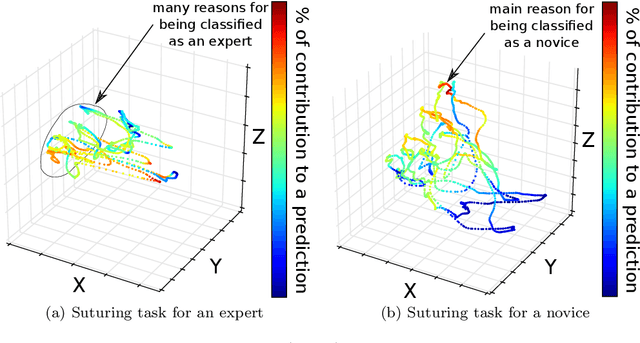

Purpose: Manual feedback from senior surgeons observing less experienced trainees is a laborious task that is very expensive, time-consuming and prone to subjectivity. With the number of surgical procedures increasing annually, there is an unprecedented need to provide an accurate, objective and automatic evaluation of trainees' surgical skills in order to improve surgical practice. Methods: In this paper, we designed a convolutional neural network (CNN) to classify surgical skills by extracting latent patterns in the trainees' motions performed during robotic surgery. The method is validated on the JIGSAWS dataset for two surgical skills evaluation tasks: classification and regression. Results: Our results show that deep neural networks constitute robust machine learning models that are able to reach new competitive state-of-the-art performance on the JIGSAWS dataset. While we leveraged from CNNs' efficiency, we were able to minimize its black-box effect using the class activation map technique. Conclusions: This characteristic allowed our method to automatically pinpoint which parts of the surgery influenced the skill evaluation the most, thus allowing us to explain a surgical skill classification and provide surgeons with a novel personalized feedback technique. We believe this type of interpretable machine learning model could integrate within "Operation Room 2.0" and support novice surgeons in improving their skills to eventually become experts.
Automatic alignment of surgical videos using kinematic data
Apr 26, 2019



Over the past one hundred years, the classic teaching methodology of "see one, do one, teach one" has governed the surgical education systems worldwide. With the advent of Operation Room 2.0, recording video, kinematic and many other types of data during the surgery became an easy task, thus allowing artificial intelligence systems to be deployed and used in surgical and medical practice. Recently, surgical videos has been shown to provide a structure for peer coaching enabling novice trainees to learn from experienced surgeons by replaying those videos. However, the high inter-operator variability in surgical gesture duration and execution renders learning from comparing novice to expert surgical videos a very difficult task. In this paper, we propose a novel technique to align multiple videos based on the alignment of their corresponding kinematic multivariate time series data. By leveraging the Dynamic Time Warping measure, our algorithm synchronizes a set of videos in order to show the same gesture being performed at different speed. We believe that the proposed approach is a valuable addition to the existing learning tools for surgery.
Transfer learning for time series classification
Nov 05, 2018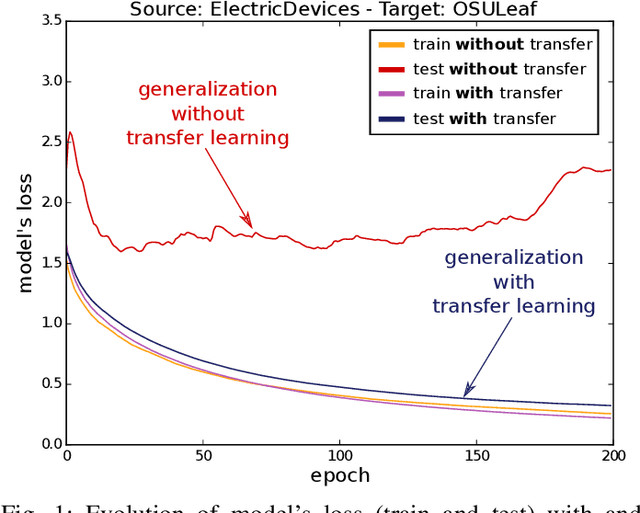

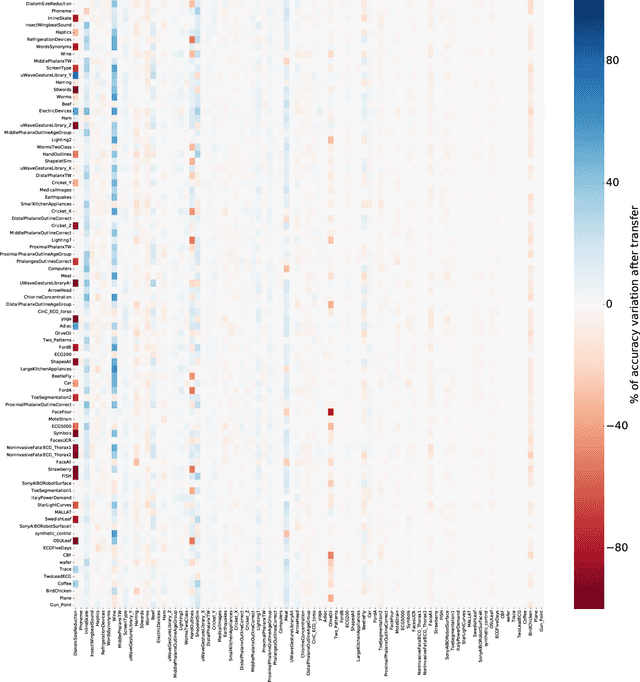
Transfer learning for deep neural networks is the process of first training a base network on a source dataset, and then transferring the learned features (the network's weights) to a second network to be trained on a target dataset. This idea has been shown to improve deep neural network's generalization capabilities in many computer vision tasks such as image recognition and object localization. Apart from these applications, deep Convolutional Neural Networks (CNNs) have also recently gained popularity in the Time Series Classification (TSC) community. However, unlike for image recognition problems, transfer learning techniques have not yet been investigated thoroughly for the TSC task. This is surprising as the accuracy of deep learning models for TSC could potentially be improved if the model is fine-tuned from a pre-trained neural network instead of training it from scratch. In this paper, we fill this gap by investigating how to transfer deep CNNs for the TSC task. To evaluate the potential of transfer learning, we performed extensive experiments using the UCR archive which is the largest publicly available TSC benchmark containing 85 datasets. For each dataset in the archive, we pre-trained a model and then fine-tuned it on the other datasets resulting in 7140 different deep neural networks. These experiments revealed that transfer learning can improve or degrade the model's predictions depending on the dataset used for transfer. Therefore, in an effort to predict the best source dataset for a given target dataset, we propose a new method relying on Dynamic Time Warping to measure inter-datasets similarities. We describe how our method can guide the transfer to choose the best source dataset leading to an improvement in accuracy on 71 out of 85 datasets.
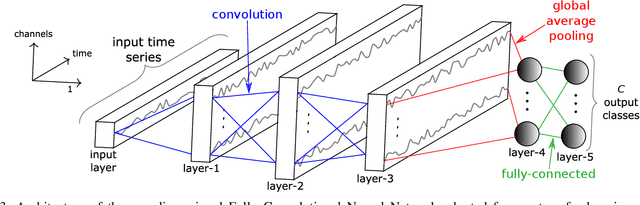
Deep learning for time series classification: a review
Sep 12, 2018


Time Series Classification (TSC) is an important and challenging problem in data mining. With the increase of time series data availability, hundreds of TSC algorithms have been proposed. Among these methods, only a few have considered Deep Neural Networks (DNNs) to perform this task. This is surprising as deep learning has seen very successful applications in the last years. DNNs have indeed revolutionized the field of computer vision especially with the advent of novel deeper architectures such as Residual and Convolutional Neural Networks. Apart from images, sequential data such as text and audio can also be processed with DNNs to reach state of the art performance for document classification and speech recognition. In this article, we study the current state of the art performance of deep learning algorithms for TSC by presenting an empirical study of the most recent DNN architectures for TSC. We give an overview of the most successful deep learning applications in various time series domains under a unified taxonomy of DNNs for TSC. We also provide an open source deep learning framework to the TSC community where we implemented each of the compared approaches and evaluated them on a univariate TSC benchmark (the UCR archive) and 12 multivariate time series datasets. By training 8,730 deep learning models on 97 time series datasets, we propose the most exhaustive study of DNNs for TSC to date.
Data augmentation using synthetic data for time series classification with deep residual networks
Aug 07, 2018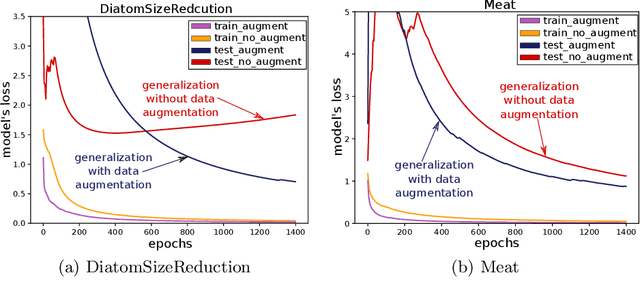

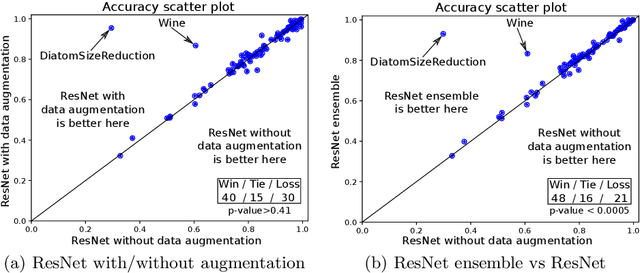
Data augmentation in deep neural networks is the process of generating artificial data in order to reduce the variance of the classifier with the goal to reduce the number of errors. This idea has been shown to improve deep neural network's generalization capabilities in many computer vision tasks such as image recognition and object localization. Apart from these applications, deep Convolutional Neural Networks (CNNs) have also recently gained popularity in the Time Series Classification (TSC) community. However, unlike in image recognition problems, data augmentation techniques have not yet been investigated thoroughly for the TSC task. This is surprising as the accuracy of deep learning models for TSC could potentially be improved, especially for small datasets that exhibit overfitting, when a data augmentation method is adopted. In this paper, we fill this gap by investigating the application of a recently proposed data augmentation technique based on the Dynamic Time Warping distance, for a deep learning model for TSC. To evaluate the potential of augmenting the training set, we performed extensive experiments using the UCR TSC benchmark. Our preliminary experiments reveal that data augmentation can drastically increase deep CNN's accuracy on some datasets and significantly improve the deep model's accuracy when the method is used in an ensemble approach.