 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Unsupervised Domain Adaptation for Time Series Classification: a Benchmark
Dec 18, 2023



Unsupervised Domain Adaptation (UDA) aims to harness labeled source data to train models for unlabeled target data. Despite extensive research in domains like computer vision and natural language processing, UDA remains underexplored for time series data, which has widespread real-world applications ranging from medicine and manufacturing to earth observation and human activity recognition. Our paper addresses this gap by introducing a comprehensive benchmark for evaluating UDA techniques for time series classification, with a focus on deep learning methods. We provide seven new benchmark datasets covering various domain shifts and temporal dynamics, facilitating fair and standardized UDA method assessments with state of the art neural network backbones (e.g. Inception) for time series data. This benchmark offers insights into the strengths and limitations of the evaluated approaches while preserving the unsupervised nature of domain adaptation, making it directly applicable to practical problems. Our paper serves as a vital resource for researchers and practitioners, advancing domain adaptation solutions for time series data and fostering innovation in this critical field. The implementation code of this benchmark is available at https://github.com/EricssonResearch/UDA-4-TSC.
Leveraging Adversarial Examples to Quantify Membership Information Leakage
Mar 23, 2022
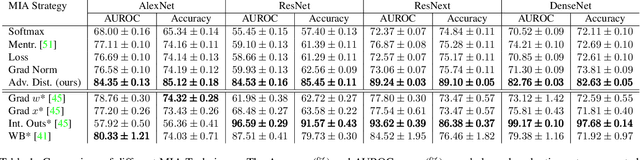


The use of personal data for training machine learning systems comes with a privacy threat and measuring the level of privacy of a model is one of the major challenges in machine learning today. Identifying training data based on a trained model is a standard way of measuring the privacy risks induced by the model. We develop a novel approach to address the problem of membership inference in pattern recognition models, relying on information provided by adversarial examples. The strategy we propose consists of measuring the magnitude of a perturbation necessary to build an adversarial example. Indeed, we argue that this quantity reflects the likelihood of belonging to the training data. Extensive numerical experiments on multivariate data and an array of state-of-the-art target models show that our method performs comparable or even outperforms state-of-the-art strategies, but without requiring any additional training samples.
Bounding Information Leakage in Machine Learning
May 09, 2021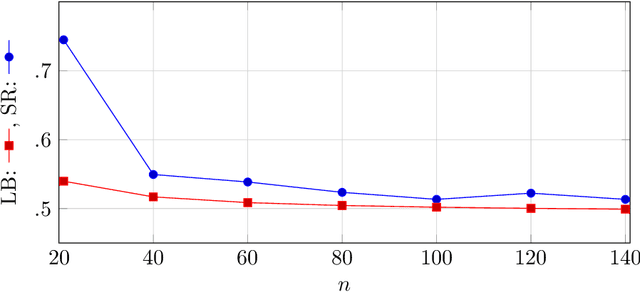
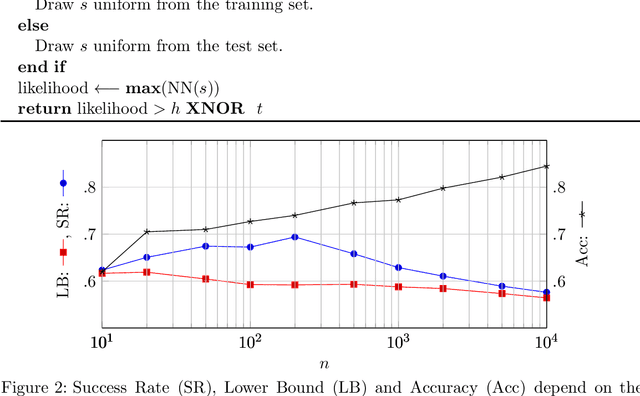
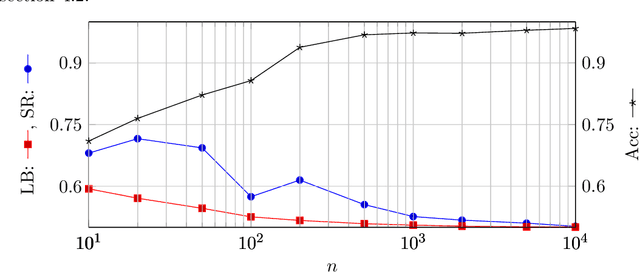
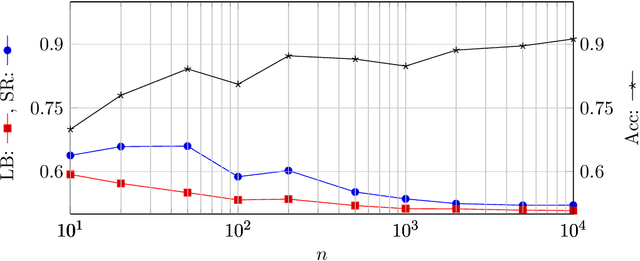
Machine Learning services are being deployed in a large range of applications that make it easy for an adversary, using the algorithm and/or the model, to gain access to sensitive data. This paper investigates fundamental bounds on information leakage. First, we identify and bound the success rate of the worst-case membership inference attack, connecting it to the generalization error of the target model. Second, we study the question of how much sensitive information is stored by the algorithm about the training set and we derive bounds on the mutual information between the sensitive attributes and model parameters. Although our contributions are mostly of theoretical nature, the bounds and involved concepts are of practical relevance. Inspired by our theoretical analysis, we study linear regression and DNN models to illustrate how these bounds can be used to assess the privacy guarantees of ML models.
Privacy-Preserving Synthetic Smart Meters Data
Dec 06, 2020
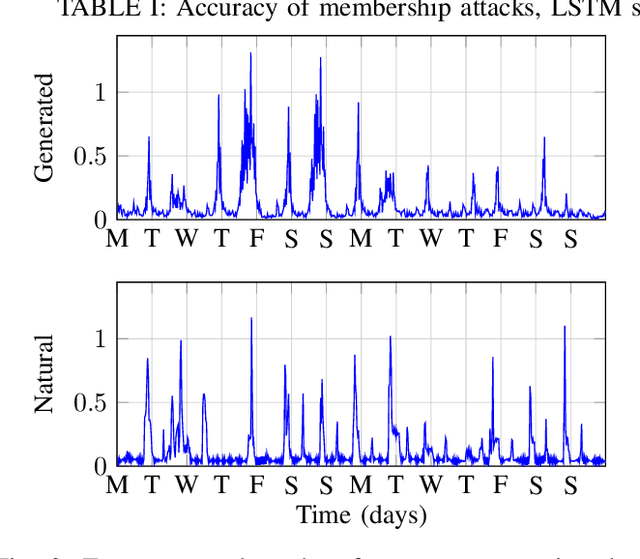
Power consumption data is very useful as it allows to optimize power grids, detect anomalies and prevent failures, on top of being useful for diverse research purposes. However, the use of power consumption data raises significant privacy concerns, as this data usually belongs to clients of a power company. As a solution, we propose a method to generate synthetic power consumption samples that faithfully imitate the originals, but are detached from the clients and their identities. Our method is based on Generative Adversarial Networks (GANs). Our contribution is twofold. First, we focus on the quality of the generated data, which is not a trivial task as no standard evaluation methods are available. Then, we study the privacy guarantees provided to members of the training set of our neural network. As a minimum requirement for privacy, we demand our neural network to be robust to membership inference attacks, as these provide a gateway for further attacks in addition to presenting a privacy threat on their own. We find that there is a compromise to be made between the privacy and the performance provided by the algorithm.