 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Skeleton Based Human Motion Rehabilitation Assessment: A Benchmark
Jul 28, 2025Automated assessment of human motion plays a vital role in rehabilitation, enabling objective evaluation of patient performance and progress. Unlike general human activity recognition, rehabilitation motion assessment focuses on analyzing the quality of movement within the same action class, requiring the detection of subtle deviations from ideal motion. Recent advances in deep learning and video-based skeleton extraction have opened new possibilities for accessible, scalable motion assessment using affordable devices such as smartphones or webcams. However, the field lacks standardized benchmarks, consistent evaluation protocols, and reproducible methodologies, limiting progress and comparability across studies. In this work, we address these gaps by (i) aggregating existing rehabilitation datasets into a unified archive called Rehab-Pile, (ii) proposing a general benchmarking framework for evaluating deep learning methods in this domain, and (iii) conducting extensive benchmarking of multiple architectures across classification and regression tasks. All datasets and implementations are released to the community to support transparency and reproducibility. This paper aims to establish a solid foundation for future research in automated rehabilitation assessment and foster the development of reliable, accessible, and personalized rehabilitation solutions. The datasets, source-code and results of this article are all publicly available.
Look Into the LITE in Deep Learning for Time Series Classification
Sep 04, 2024



Deep learning models have been shown to be a powerful solution for Time Series Classification (TSC). State-of-the-art architectures, while producing promising results on the UCR and the UEA archives , present a high number of trainable parameters. This can lead to long training with high CO2 emission, power consumption and possible increase in the number of FLoating-point Operation Per Second (FLOPS). In this paper, we present a new architecture for TSC, the Light Inception with boosTing tEchnique (LITE) with only 2.34% of the number of parameters of the state-of-the-art InceptionTime model, while preserving performance. This architecture, with only 9, 814 trainable parameters due to the usage of DepthWise Separable Convolutions (DWSC), is boosted by three techniques: multiplexing, custom filters, and dilated convolution. The LITE architecture, trained on the UCR, is 2.78 times faster than InceptionTime and consumes 2.79 times less CO2 and power. To evaluate the performance of the proposed architecture on multivariate time series data, we adapt LITE to handle multivariate time series, we call this version LITEMV. To bring theory into application, we also conducted experiments using LITEMV on multivariate time series representing human rehabilitation movements, showing that LITEMV not only is the most efficient model but also the best performing for this application on the Kimore dataset, a skeleton based human rehabilitation exercises dataset. Moreover, to address the interpretability of LITEMV, we present a study using Class Activation Maps to understand the classification decision taken by the model during evaluation.
A Medical Low-Back Pain Physical Rehabilitation Dataset for Human Body Movement Analysis
Jun 29, 2024



While automatic monitoring and coaching of exercises are showing encouraging results in non-medical applications, they still have limitations such as errors and limited use contexts. To allow the development and assessment of physical rehabilitation by an intelligent tutoring system, we identify in this article four challenges to address and propose a medical dataset of clinical patients carrying out low back-pain rehabilitation exercises. The dataset includes 3D Kinect skeleton positions and orientations, RGB videos, 2D skeleton data, and medical annotations to assess the correctness, and error classification and localisation of body part and timespan. Along this dataset, we perform a complete research path, from data collection to processing, and finally a small benchmark. We evaluated on the dataset two baseline movement recognition algorithms, pertaining to two different approaches: the probabilistic approach with a Gaussian Mixture Model (GMM), and the deep learning approach with a Long-Short Term Memory (LSTM). This dataset is valuable because it includes rehabilitation relevant motions in a clinical setting with patients in their rehabilitation program, using a cost-effective, portable, and convenient sensor, and because it shows the potential for improvement on these challenges.
Establishing a Unified Evaluation Framework for Human Motion Generation: A Comparative Analysis of Metrics
May 13, 2024



The development of generative artificial intelligence for human motion generation has expanded rapidly, necessitating a unified evaluation framework. This paper presents a detailed review of eight evaluation metrics for human motion generation, highlighting their unique features and shortcomings. We propose standardized practices through a unified evaluation setup to facilitate consistent model comparisons. Additionally, we introduce a novel metric that assesses diversity in temporal distortion by analyzing warping diversity, thereby enhancing the evaluation of temporal data. We also conduct experimental analyses of three generative models using a publicly available dataset, offering insights into the interpretation of each metric in specific case scenarios. Our goal is to offer a clear, user-friendly evaluation framework for newcomers, complemented by publicly accessible code.
Finding Foundation Models for Time Series Classification with a PreText Task
Nov 24, 2023



Over the past decade, Time Series Classification (TSC) has gained an increasing attention. While various methods were explored, deep learning - particularly through Convolutional Neural Networks (CNNs)-stands out as an effective approach. However, due to the limited availability of training data, defining a foundation model for TSC that overcomes the overfitting problem is still a challenging task. The UCR archive, encompassing a wide spectrum of datasets ranging from motion recognition to ECG-based heart disease detection, serves as a prime example for exploring this issue in diverse TSC scenarios. In this paper, we address the overfitting challenge by introducing pre-trained domain foundation models. A key aspect of our methodology is a novel pretext task that spans multiple datasets. This task is designed to identify the originating dataset of each time series sample, with the goal of creating flexible convolution filters that can be applied across different datasets. The research process consists of two phases: a pre-training phase where the model acquires general features through the pretext task, and a subsequent fine-tuning phase for specific dataset classifications. Our extensive experiments on the UCR archive demonstrate that this pre-training strategy significantly outperforms the conventional training approach without pre-training. This strategy effectively reduces overfitting in small datasets and provides an efficient route for adapting these models to new datasets, thus advancing the capabilities of deep learning in TSC.
ShapeDBA: Generating Effective Time Series Prototypes using ShapeDTW Barycenter Averaging
Sep 28, 2023



Time series data can be found in almost every domain, ranging from the medical field to manufacturing and wireless communication. Generating realistic and useful exemplars and prototypes is a fundamental data analysis task. In this paper, we investigate a novel approach to generating realistic and useful exemplars and prototypes for time series data. Our approach uses a new form of time series average, the ShapeDTW Barycentric Average. We therefore turn our attention to accurately generating time series prototypes with a novel approach. The existing time series prototyping approaches rely on the Dynamic Time Warping (DTW) similarity measure such as DTW Barycentering Average (DBA) and SoftDBA. These last approaches suffer from a common problem of generating out-of-distribution artifacts in their prototypes. This is mostly caused by the DTW variant used and its incapability of detecting neighborhood similarities, instead it detects absolute similarities. Our proposed method, ShapeDBA, uses the ShapeDTW variant of DTW, that overcomes this issue. We chose time series clustering, a popular form of time series analysis to evaluate the outcome of ShapeDBA compared to the other prototyping approaches. Coupled with the k-means clustering algorithm, and evaluated on a total of 123 datasets from the UCR archive, our proposed averaging approach is able to achieve new state-of-the-art results in terms of Adjusted Rand Index.
An Approach to Multiple Comparison Benchmark Evaluations that is Stable Under Manipulation of the Comparate Set
May 19, 2023
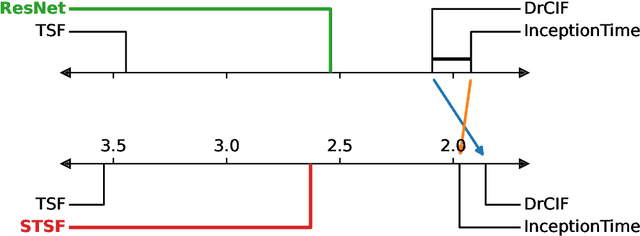
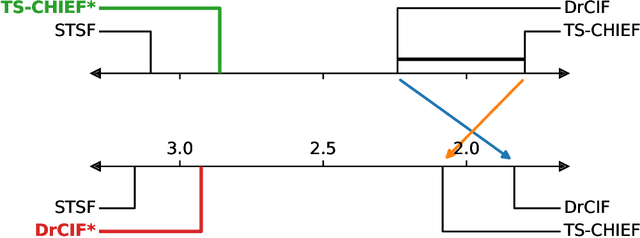
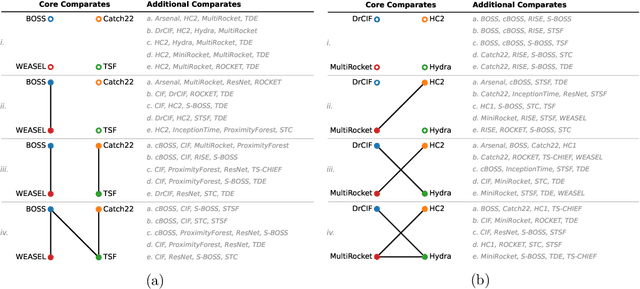
The measurement of progress using benchmarks evaluations is ubiquitous in computer science and machine learning. However, common approaches to analyzing and presenting the results of benchmark comparisons of multiple algorithms over multiple datasets, such as the critical difference diagram introduced by Dem\v{s}ar (2006), have important shortcomings and, we show, are open to both inadvertent and intentional manipulation. To address these issues, we propose a new approach to presenting the results of benchmark comparisons, the Multiple Comparison Matrix (MCM), that prioritizes pairwise comparisons and precludes the means of manipulating experimental results in existing approaches. MCM can be used to show the results of an all-pairs comparison, or to show the results of a comparison between one or more selected algorithms and the state of the art. MCM is implemented in Python and is publicly available.
A co-design approach for a rehabilitation robot coach for physical rehabilitation based on the error classification of motion errors
Nov 18, 2021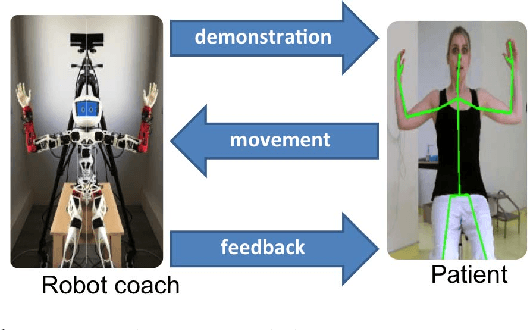
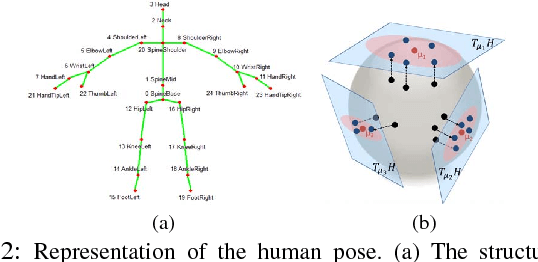
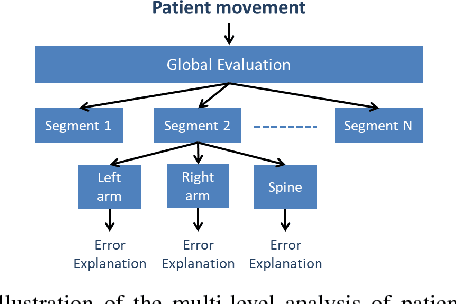
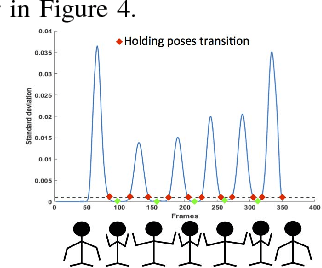
The rising number of the elderly incurs growing concern about healthcare, and in particular rehabilitation healthcare. Assistive technology and assistive robotics in particular may help to improve this process. We develop a robot coach capable of demonstrating rehabilitation exercises to patients, watch a patient carry out the exercises and give him feedback so as to improve his performance and encourage him. The HRI of the system is based on our study with a team of rehabilitation therapists and with the target population.The system relies on human motion analysis. We develop a method for learning a probabilistic representation of ideal movements from expert demonstrations. A Gaussian Mixture Model is employed from position and orientation features captured using a Microsoft Kinect v2. For assessing patients' movements, we propose a real-time multi-level analysis to both temporally and spatially identify and explain body part errors. This analysis combined with a classification algorithm allows the robot to provide coaching advice to make the patient improve his movements. The evaluation on three rehabilitation exercises shows the potential of the proposed approach for learning and assessing kinaesthetic movements.
Generating Shared Latent Variables for Robots to Imitate Human Movements and Understand their Physical Limitations
Feb 14, 2019



Assistive robotics and particularly robot coaches may be very helpful for rehabilitation healthcare. In this context, we propose a method based on Gaussian Process Latent Variable Model (GP-LVM) to transfer knowledge between a physiotherapist, a robot coach and a patient. Our model is able to map visual human body features to robot data in order to facilitate the robot learning and imitation. In addition , we propose to extend the model to adapt robots' understanding to patient's physical limitations during the assessment of rehabilitation exercises. Experimental evaluation demonstrates promising results for both robot imitation and model adaptation according to the patients' limitations.