 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Extensions and Efficiency Trade-Offs for Sustainable Time Series Classification
Apr 09, 2026Time series classification (TSC) enables important use cases, however lacks a unified understanding of performance trade-offs across models, datasets, and hardware. While resource awareness has grown in the field, TSC methods have not yet been rigorously evaluated for energy efficiency. This paper introduces a holistic evaluation framework that explicitly explores the balance of predictive performance and resource consumption in TSC. To boost efficiency, we apply a theoretically bounded pruning strategy to leading hybrid classifiers - Hydra and Quant - and present Hydrant, a novel, prunable combination of both. With over 4000 experimental configurations across 20 MONSTER datasets, 13 methods, and three compute setups, we systematically analyze how model design, hyperparameters, and hardware choices affect practical TSC performance. Our results showcase that pruning can significantly reduce energy consumption by up to 80% while maintaining competitive predictive quality, usually costing the model less than 5% of accuracy. The proposed methodology, experimental results, and accompanying software advance TSC toward sustainable and reproducible practice.
The Multiverse of Time Series Machine Learning: an Archive for Multivariate Time Series Classification
Mar 20, 2026Time series machine learning (TSML) is a growing research field that spans a wide range of tasks. The popularity of established tasks such as classification, clustering, and extrinsic regression has, in part, been driven by the availability of benchmark datasets. An archive of 30 multivariate time series classification datasets, introduced in 2018 and commonly known as the UEA archive, has since become an essential resource cited in hundreds of publications. We present a substantial expansion of this archive that more than quadruples its size, from 30 to 133 classification problems. We also release preprocessed versions of datasets containing missing values or unequal length series, bringing the total number of datasets to 147. Reflecting the growth of the archive and the broader community, we rebrand it as the Multiverse archive to capture its diversity of domains. The Multiverse archive includes datasets from multiple sources, consolidating other collections and standalone datasets into a single, unified repository. Recognising that running experiments across the full archive is computationally demanding, we recommend a subset of the full archive called Multiverse-core (MV-core) for initial exploration. To support researchers in using the new archive, we provide detailed guidance and a baseline evaluation of established and recent classification algorithms, establishing performance benchmarks for future research. We have created a dedicated repository for the Multiverse archive that provides a common aeon and scikit-learn compatible framework for reproducibility, an extensive record of published results, and an interactive interface to explore the results.
MONSTER: Monash Scalable Time Series Evaluation Repository
Feb 21, 2025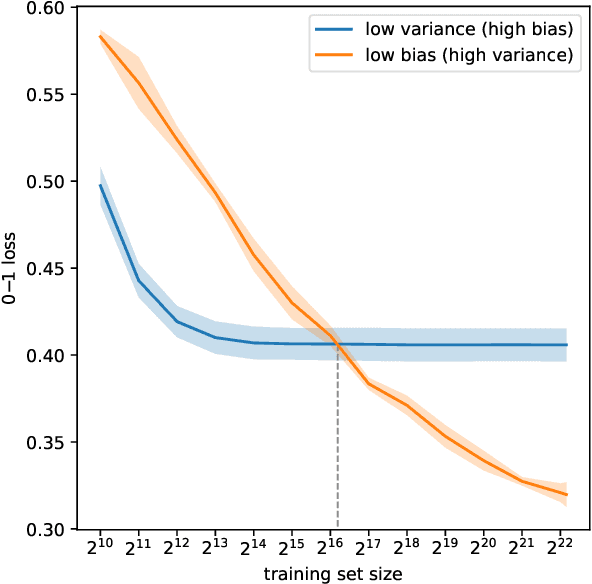
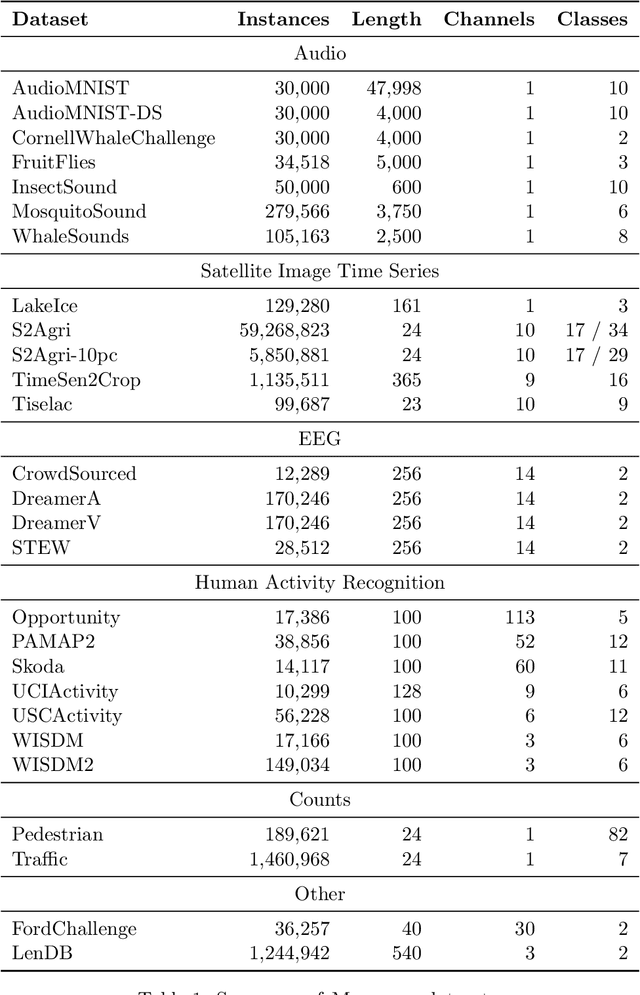
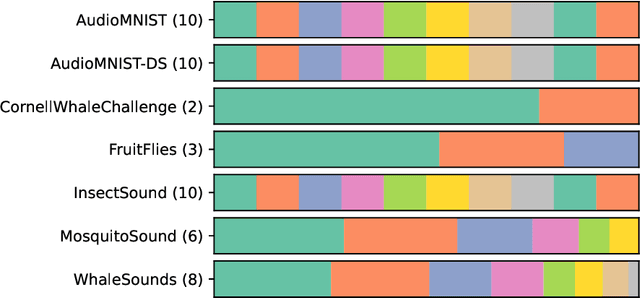
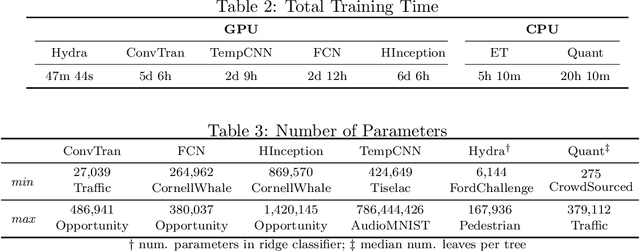
We introduce MONSTER-the MONash Scalable Time Series Evaluation Repository-a collection of large datasets for time series classification. The field of time series classification has benefitted from common benchmarks set by the UCR and UEA time series classification repositories. However, the datasets in these benchmarks are small, with median sizes of 217 and 255 examples, respectively. In consequence they favour a narrow subspace of models that are optimised to achieve low classification error on a wide variety of smaller datasets, that is, models that minimise variance, and give little weight to computational issues such as scalability. Our hope is to diversify the field by introducing benchmarks using larger datasets. We believe that there is enormous potential for new progress in the field by engaging with the theoretical and practical challenges of learning effectively from larger quantities of data.
Prevalidated ridge regression is a highly-efficient drop-in replacement for logistic regression for high-dimensional data
Jan 28, 2024



Logistic regression is a ubiquitous method for probabilistic classification. However, the effectiveness of logistic regression depends upon careful and relatively computationally expensive tuning, especially for the regularisation hyperparameter, and especially in the context of high-dimensional data. We present a prevalidated ridge regression model that closely matches logistic regression in terms of classification error and log-loss, particularly for high-dimensional data, while being significantly more computationally efficient and having effectively no hyperparameters beyond regularisation. We scale the coefficients of the model so as to minimise log-loss for a set of prevalidated predictions derived from the estimated leave-one-out cross-validation error. This exploits quantities already computed in the course of fitting the ridge regression model in order to find the scaling parameter with nominal additional computational expense.
QUANT: A Minimalist Interval Method for Time Series Classification
Aug 02, 2023



We show that it is possible to achieve the same accuracy, on average, as the most accurate existing interval methods for time series classification on a standard set of benchmark datasets using a single type of feature (quantiles), fixed intervals, and an 'off the shelf' classifier. This distillation of interval-based approaches represents a fast and accurate method for time series classification, achieving state-of-the-art accuracy on the expanded set of 142 datasets in the UCR archive with a total compute time (training and inference) of less than 15 minutes using a single CPU core.
An Approach to Multiple Comparison Benchmark Evaluations that is Stable Under Manipulation of the Comparate Set
May 19, 2023
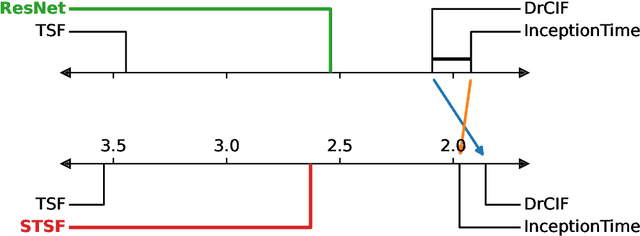
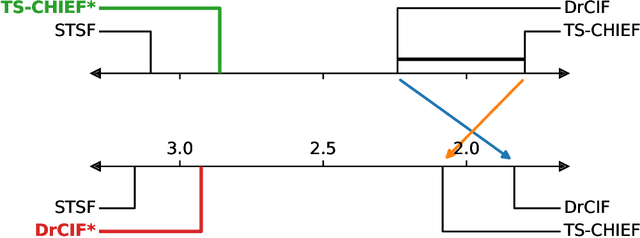
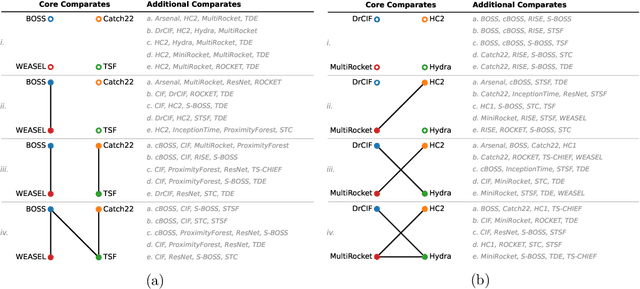
The measurement of progress using benchmarks evaluations is ubiquitous in computer science and machine learning. However, common approaches to analyzing and presenting the results of benchmark comparisons of multiple algorithms over multiple datasets, such as the critical difference diagram introduced by Dem\v{s}ar (2006), have important shortcomings and, we show, are open to both inadvertent and intentional manipulation. To address these issues, we propose a new approach to presenting the results of benchmark comparisons, the Multiple Comparison Matrix (MCM), that prioritizes pairwise comparisons and precludes the means of manipulating experimental results in existing approaches. MCM can be used to show the results of an all-pairs comparison, or to show the results of a comparison between one or more selected algorithms and the state of the art. MCM is implemented in Python and is publicly available.
HYDRA: Competing convolutional kernels for fast and accurate time series classification
Mar 25, 2022



We demonstrate a simple connection between dictionary methods for time series classification, which involve extracting and counting symbolic patterns in time series, and methods based on transforming input time series using convolutional kernels, namely ROCKET and its variants. We show that by adjusting a single hyperparameter it is possible to move by degrees between models resembling dictionary methods and models resembling ROCKET. We present HYDRA, a simple, fast, and accurate dictionary method for time series classification using competing convolutional kernels, combining key aspects of both ROCKET and conventional dictionary methods. HYDRA is faster and more accurate than the most accurate existing dictionary methods, and can be combined with ROCKET and its variants to further improve the accuracy of these methods.
MultiRocket: Effective summary statistics for convolutional outputs in time series classification
Jan 31, 2021
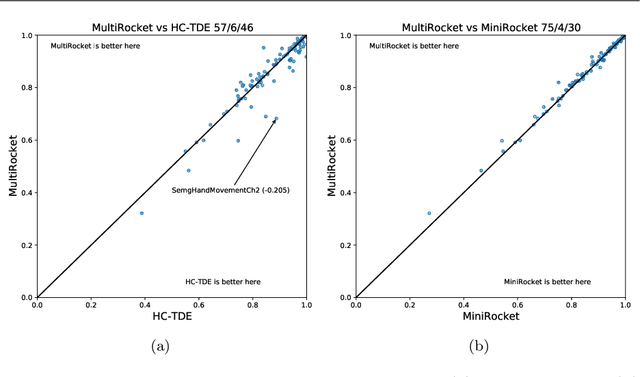

Rocket and MiniRocket, while two of the fastest methods for time series classification, are both somewhat less accurate than the current most accurate methods (namely, HIVE-COTE and its variants). We show that it is possible to significantly improve the accuracy of MiniRocket (and Rocket), with some additional computational expense, by expanding the set of features produced by the transform, making MultiRocket (for MiniRocket with Multiple Features) overall the single most accurate method on the datasets in the UCR archive, while still being orders of magnitude faster than any algorithm of comparable accuracy other than its precursors
MINIROCKET: A Very Fast (Almost) Deterministic Transform for Time Series Classification
Dec 16, 2020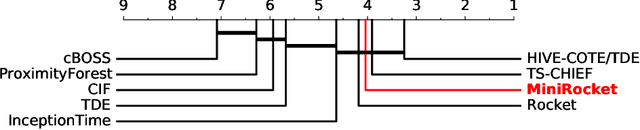

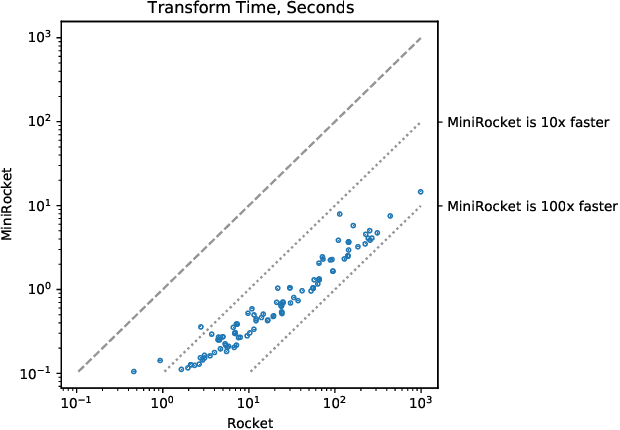
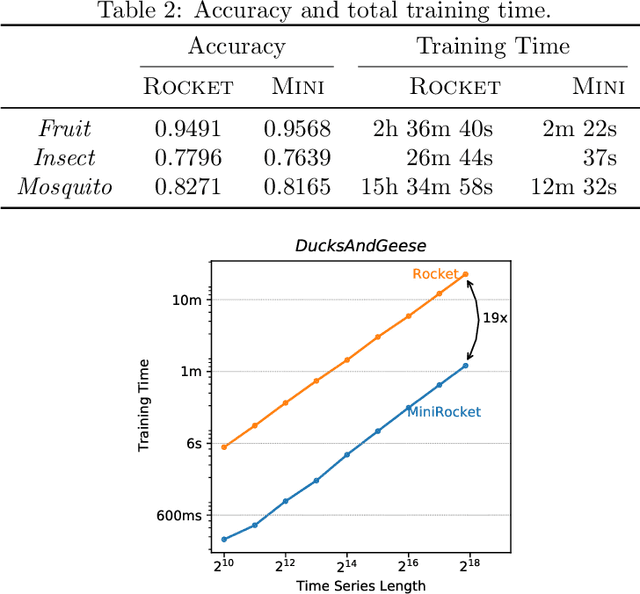
Until recently, the most accurate methods for time series classification were limited by high computational complexity. ROCKET achieves state-of-the-art accuracy with a fraction of the computational expense of most existing methods by transforming input time series using random convolutional kernels, and using the transformed features to train a linear classifier. We reformulate ROCKET into a new method, MINIROCKET, making it up to 75 times faster on larger datasets, and making it almost deterministic (and optionally, with additional computational expense, fully deterministic), while maintaining essentially the same accuracy. Using this method, it is possible to train and test a classifier on all of 109 datasets from the UCR archive to state-of-the-art accuracy in less than 10 minutes. MINIROCKET is significantly faster than any other method of comparable accuracy (including ROCKET), and significantly more accurate than any other method of even roughly-similar computational expense. As such, we suggest that MINIROCKET should now be considered and used as the default variant of ROCKET.
ROCKET: Exceptionally fast and accurate time series classification using random convolutional kernels
Oct 29, 2019

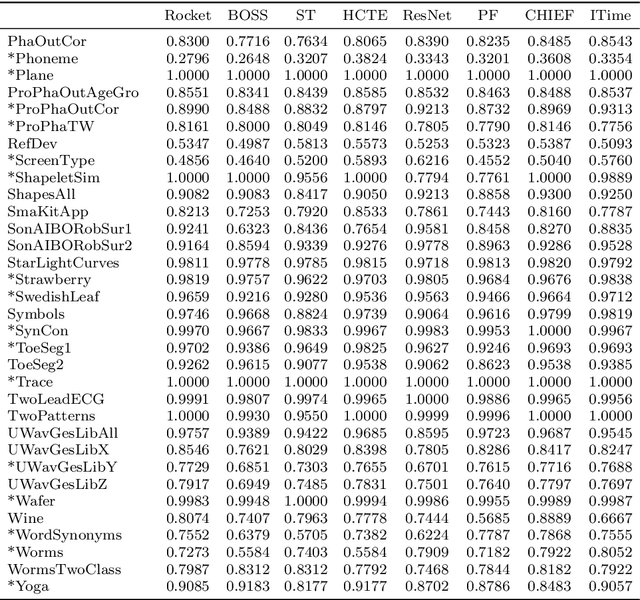

Most methods for time series classification that attain state-of-the-art accuracy have high computational complexity, requiring significant training time even for smaller datasets, and are intractable for larger datasets. Additionally, many existing methods focus on a single type of feature such as shape or frequency. Building on the recent success of convolutional neural networks for time series classification, we show that simple linear classifiers using random convolutional kernels achieve state-of-the-art accuracy with a fraction of the computational expense of existing methods.