 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEG-X: Device-Agnostic and Noise-Robust Foundation Model for EEG
Nov 12, 2025



Foundation models for EEG analysis are still in their infancy, limited by two key challenges: (1) variability across datasets caused by differences in recording devices and configurations, and (2) the low signal-to-noise ratio (SNR) of EEG, where brain signals are often buried under artifacts and non-brain sources. To address these challenges, we present EEG-X, a device-agnostic and noise-robust foundation model for EEG representation learning. EEG-X introduces a novel location-based channel embedding that encodes spatial information and improves generalization across domains and tasks by allowing the model to handle varying channel numbers, combinations, and recording lengths. To enhance robustness against noise, EEG-X employs a noise-aware masking and reconstruction strategy in both raw and latent spaces. Unlike previous models that mask and reconstruct raw noisy EEG signals, EEG-X is trained to reconstruct denoised signals obtained through an artifact removal process, ensuring that the learned representations focus on neural activity rather than noise. To further enhance reconstruction-based pretraining, EEG-X introduces a dictionary-inspired convolutional transformation (DiCT) layer that projects signals into a structured feature space before computing reconstruction (MSE) loss, reducing noise sensitivity and capturing frequency- and shape-aware similarities. Experiments on datasets collected from diverse devices show that EEG-X outperforms state-of-the-art methods across multiple downstream EEG tasks and excels in cross-domain settings where pre-trained and downstream datasets differ in electrode layouts. The models and code are available at: https://github.com/Emotiv/EEG-X
KnowEEG: Explainable Knowledge Driven EEG Classification
May 01, 2025



Electroencephalography (EEG) is a method of recording brain activity that shows significant promise in applications ranging from disease classification to emotion detection and brain-computer interfaces. Recent advances in deep learning have improved EEG classification performance yet model explainability remains an issue. To address this key limitation of explainability we introduce KnowEEG; a novel explainable machine learning approach for EEG classification. KnowEEG extracts a comprehensive set of per-electrode features, filters them using statistical tests, and integrates between-electrode connectivity statistics. These features are then input to our modified Random Forest model (Fusion Forest) that balances per electrode statistics with between electrode connectivity features in growing the trees of the forest. By incorporating knowledge from both the generalized time-series and EEG-specific domains, KnowEEG achieves performance comparable to or exceeding state-of-the-art deep learning models across five different classification tasks: emotion detection, mental workload classification, eyes open/closed detection, abnormal EEG classification, and event detection. In addition to high performance, KnowEEG provides inherent explainability through feature importance scores for understandable features. We demonstrate by example on the eyes closed/open classification task that this explainability can be used to discover knowledge about the classes. This discovered knowledge for eyes open/closed classification was proven to be correct by current neuroscience literature. Therefore, the impact of KnowEEG will be significant for domains where EEG explainability is critical such as healthcare.
MONSTER: Monash Scalable Time Series Evaluation Repository
Feb 21, 2025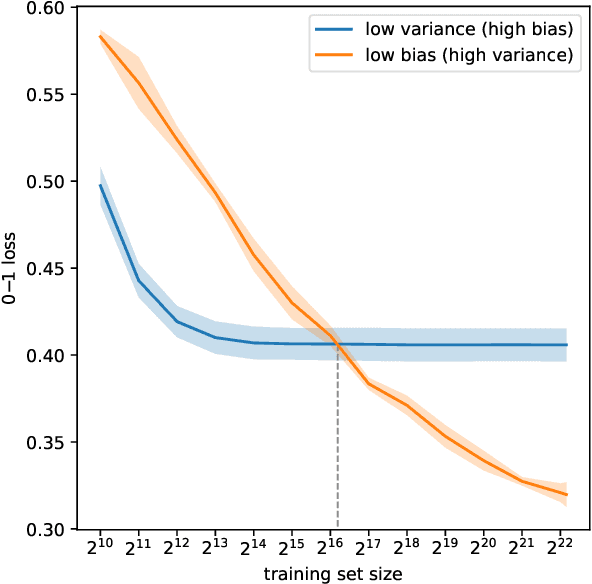
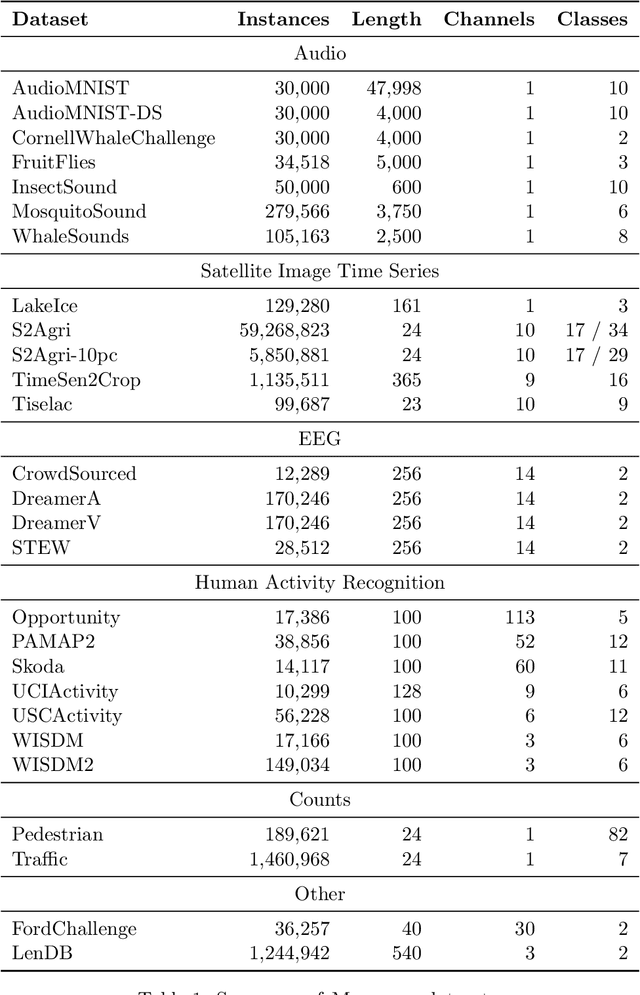
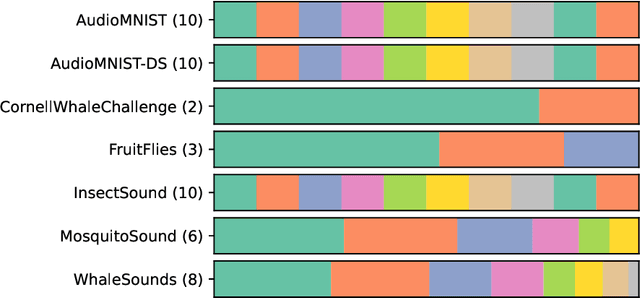
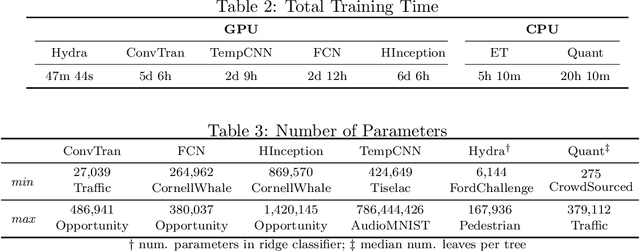
We introduce MONSTER-the MONash Scalable Time Series Evaluation Repository-a collection of large datasets for time series classification. The field of time series classification has benefitted from common benchmarks set by the UCR and UEA time series classification repositories. However, the datasets in these benchmarks are small, with median sizes of 217 and 255 examples, respectively. In consequence they favour a narrow subspace of models that are optimised to achieve low classification error on a wide variety of smaller datasets, that is, models that minimise variance, and give little weight to computational issues such as scalability. Our hope is to diversify the field by introducing benchmarks using larger datasets. We believe that there is enormous potential for new progress in the field by engaging with the theoretical and practical challenges of learning effectively from larger quantities of data.
EEG2Rep: Enhancing Self-supervised EEG Representation Through Informative Masked Inputs
Feb 17, 2024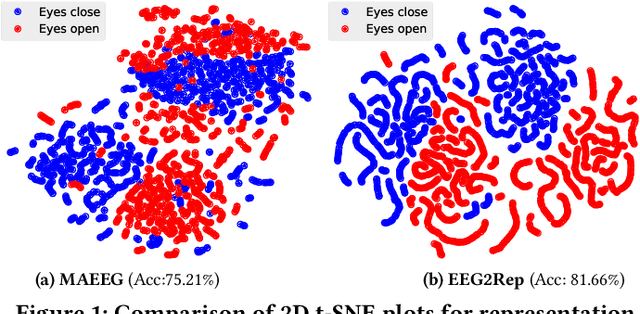
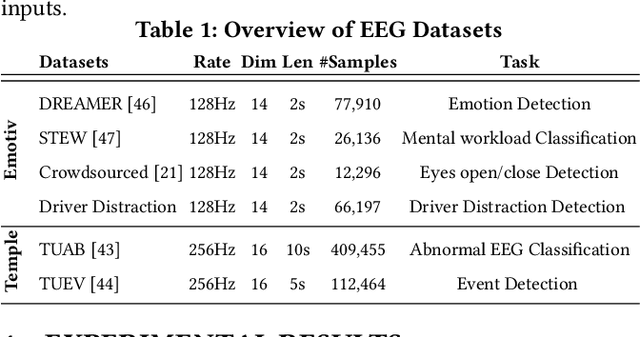
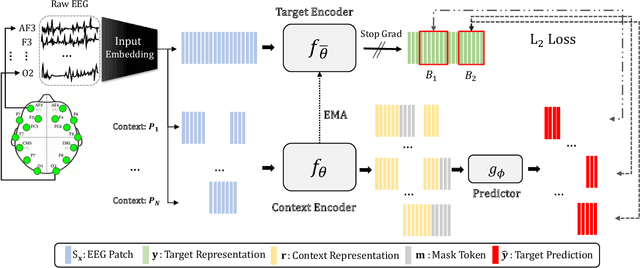
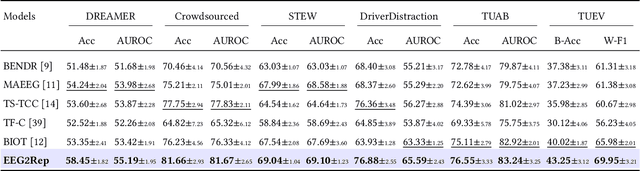
Self-supervised approaches for electroencephalography (EEG) representation learning face three specific challenges inherent to EEG data: (1) The low signal-to-noise ratio which challenges the quality of the representation learned, (2) The wide range of amplitudes from very small to relatively large due to factors such as the inter-subject variability, risks the models to be dominated by higher amplitude ranges, and (3) The absence of explicit segmentation in the continuous-valued sequences which can result in less informative representations. To address these challenges, we introduce EEG2Rep, a self-prediction approach for self-supervised representation learning from EEG. Two core novel components of EEG2Rep are as follows: 1) Instead of learning to predict the masked input from raw EEG, EEG2Rep learns to predict masked input in latent representation space, and 2) Instead of conventional masking methods, EEG2Rep uses a new semantic subsequence preserving (SSP) method which provides informative masked inputs to guide EEG2Rep to generate rich semantic representations. In experiments on 6 diverse EEG tasks with subject variability, EEG2Rep significantly outperforms state-of-the-art methods. We show that our semantic subsequence preserving improves the existing masking methods in self-prediction literature and find that preserving 50\% of EEG recordings will result in the most accurate results on all 6 tasks on average. Finally, we show that EEG2Rep is robust to noise addressing a significant challenge that exists in EEG data. Models and code are available at: https://github.com/Navidfoumani/EEG2Rep
Series2Vec: Similarity-based Self-supervised Representation Learning for Time Series Classification
Dec 12, 2023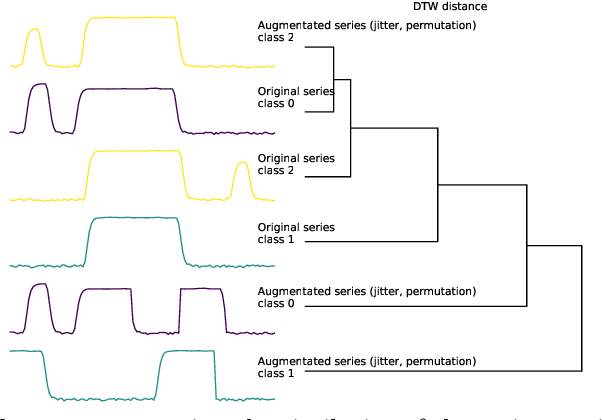
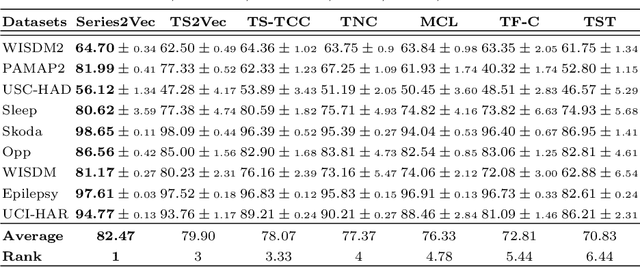
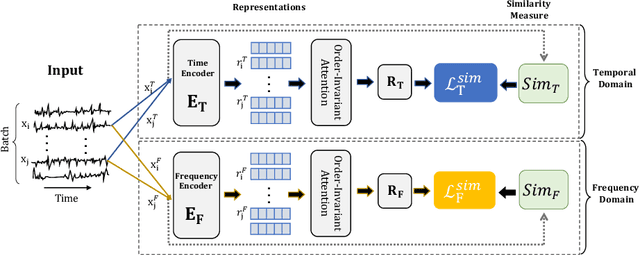

We argue that time series analysis is fundamentally different in nature to either vision or natural language processing with respect to the forms of meaningful self-supervised learning tasks that can be defined. Motivated by this insight, we introduce a novel approach called \textit{Series2Vec} for self-supervised representation learning. Unlike other self-supervised methods in time series, which carry the risk of positive sample variants being less similar to the anchor sample than series in the negative set, Series2Vec is trained to predict the similarity between two series in both temporal and spectral domains through a self-supervised task. Series2Vec relies primarily on the consistency of the unsupervised similarity step, rather than the intrinsic quality of the similarity measurement, without the need for hand-crafted data augmentation. To further enforce the network to learn similar representations for similar time series, we propose a novel approach that applies order-invariant attention to each representation within the batch during training. Our evaluation of Series2Vec on nine large real-world datasets, along with the UCR/UEA archive, shows enhanced performance compared to current state-of-the-art self-supervised techniques for time series. Additionally, our extensive experiments show that Series2Vec performs comparably with fully supervised training and offers high efficiency in datasets with limited-labeled data. Finally, we show that the fusion of Series2Vec with other representation learning models leads to enhanced performance for time series classification. Code and models are open-source at \url{https://github.com/Navidfoumani/Series2Vec.}
Improving Position Encoding of Transformers for Multivariate Time Series Classification
May 26, 2023Transformers have demonstrated outstanding performance in many applications of deep learning. When applied to time series data, transformers require effective position encoding to capture the ordering of the time series data. The efficacy of position encoding in time series analysis is not well-studied and remains controversial, e.g., whether it is better to inject absolute position encoding or relative position encoding, or a combination of them. In order to clarify this, we first review existing absolute and relative position encoding methods when applied in time series classification. We then proposed a new absolute position encoding method dedicated to time series data called time Absolute Position Encoding (tAPE). Our new method incorporates the series length and input embedding dimension in absolute position encoding. Additionally, we propose computationally Efficient implementation of Relative Position Encoding (eRPE) to improve generalisability for time series. We then propose a novel multivariate time series classification (MTSC) model combining tAPE/eRPE and convolution-based input encoding named ConvTran to improve the position and data embedding of time series data. The proposed absolute and relative position encoding methods are simple and efficient. They can be easily integrated into transformer blocks and used for downstream tasks such as forecasting, extrinsic regression, and anomaly detection. Extensive experiments on 32 multivariate time-series datasets show that our model is significantly more accurate than state-of-the-art convolution and transformer-based models. Code and models are open-sourced at \url{https://github.com/Navidfoumani/ConvTran}.
Deep Learning for Time Series Classification and Extrinsic Regression: A Current Survey
Feb 06, 2023



Time Series Classification and Extrinsic Regression are important and challenging machine learning tasks. Deep learning has revolutionized natural language processing and computer vision and holds great promise in other fields such as time series analysis where the relevant features must often be abstracted from the raw data but are not known a priori. This paper surveys the current state of the art in the fast-moving field of deep learning for time series classification and extrinsic regression. We review different network architectures and training methods used for these tasks and discuss the challenges and opportunities when applying deep learning to time series data. We also summarize two critical applications of time series classification and extrinsic regression, human activity recognition and satellite earth observation.