 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMantis: Lightweight Calibrated Foundation Model for User-Friendly Time Series Classification
Feb 21, 2025In recent years, there has been increasing interest in developing foundation models for time series data that can generalize across diverse downstream tasks. While numerous forecasting-oriented foundation models have been introduced, there is a notable scarcity of models tailored for time series classification. To address this gap, we present Mantis, a new open-source foundation model for time series classification based on the Vision Transformer (ViT) architecture that has been pre-trained using a contrastive learning approach. Our experimental results show that Mantis outperforms existing foundation models both when the backbone is frozen and when fine-tuned, while achieving the lowest calibration error. In addition, we propose several adapters to handle the multivariate setting, reducing memory requirements and modeling channel interdependence.
Analysing Multi-Task Regression via Random Matrix Theory with Application to Time Series Forecasting
Jun 14, 2024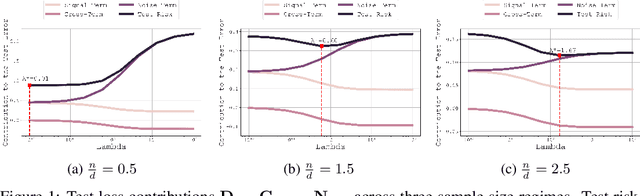
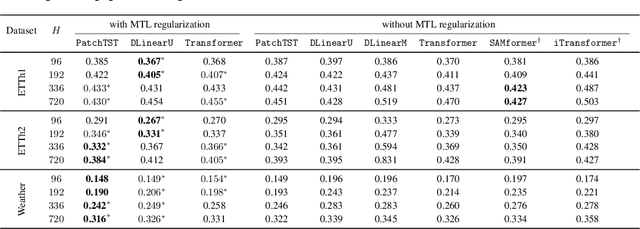
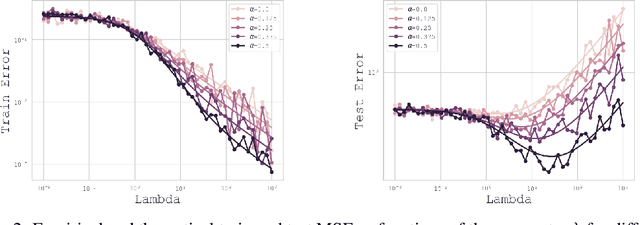
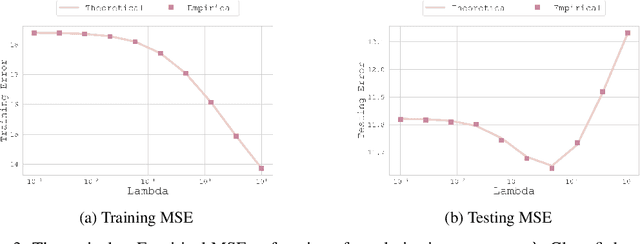
In this paper, we introduce a novel theoretical framework for multi-task regression, applying random matrix theory to provide precise performance estimations, under high-dimensional, non-Gaussian data distributions. We formulate a multi-task optimization problem as a regularization technique to enable single-task models to leverage multi-task learning information. We derive a closed-form solution for multi-task optimization in the context of linear models. Our analysis provides valuable insights by linking the multi-task learning performance to various model statistics such as raw data covariances, signal-generating hyperplanes, noise levels, as well as the size and number of datasets. We finally propose a consistent estimation of training and testing errors, thereby offering a robust foundation for hyperparameter optimization in multi-task regression scenarios. Experimental validations on both synthetic and real-world datasets in regression and multivariate time series forecasting demonstrate improvements on univariate models, incorporating our method into the training loss and thus leveraging multivariate information.
Data Augmentation for Multivariate Time Series Classification: An Experimental Study
Jun 10, 2024



Our study investigates the impact of data augmentation on the performance of multivariate time series models, focusing on datasets from the UCR archive. Despite the limited size of these datasets, we achieved classification accuracy improvements in 10 out of 13 datasets using the Rocket and InceptionTime models. This highlights the essential role of sufficient data in training effective models, paralleling the advancements seen in computer vision. Our work delves into adapting and applying existing methods in innovative ways to the domain of multivariate time series classification. Our comprehensive exploration of these techniques sets a new standard for addressing data scarcity in time series analysis, emphasizing that diverse augmentation strategies are crucial for unlocking the potential of both traditional and deep learning models. Moreover, by meticulously analyzing and applying a variety of augmentation techniques, we demonstrate that strategic data enrichment can enhance model accuracy. This not only establishes a benchmark for future research in time series analysis but also underscores the importance of adopting varied augmentation approaches to improve model performance in the face of limited data availability.
Unlocking the Potential of Transformers in Time Series Forecasting with Sharpness-Aware Minimization and Channel-Wise Attention
Feb 19, 2024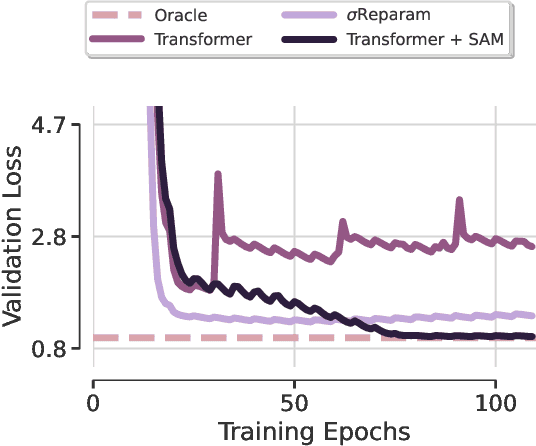
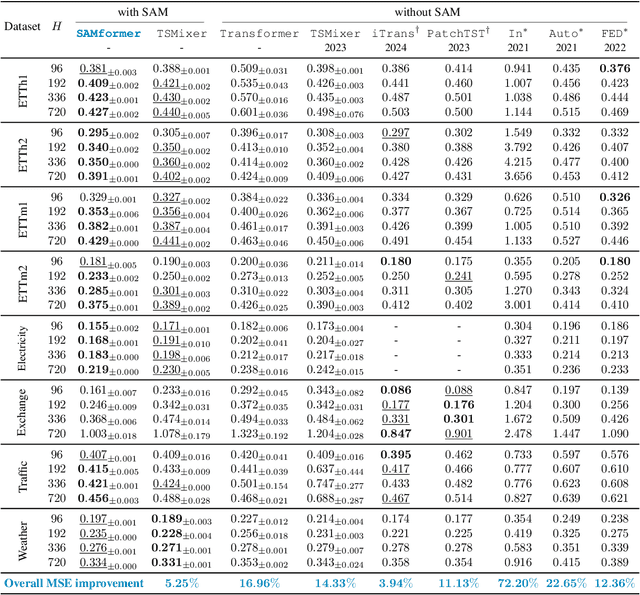
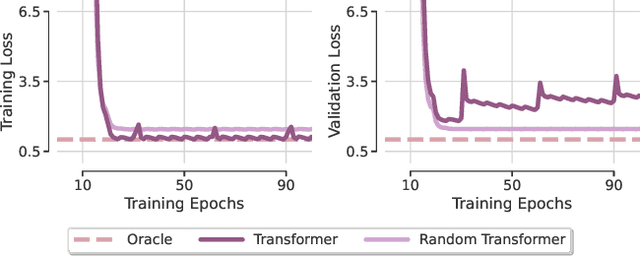
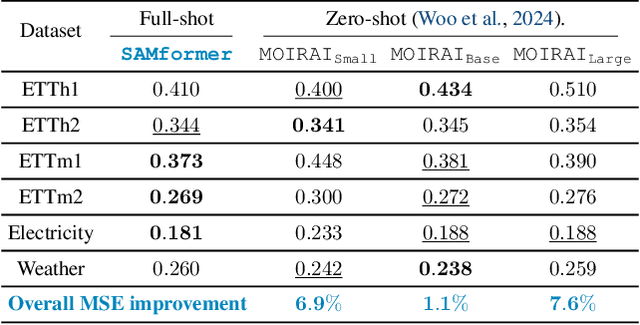
Transformer-based architectures achieved breakthrough performance in natural language processing and computer vision, yet they remain inferior to simpler linear baselines in multivariate long-term forecasting. To better understand this phenomenon, we start by studying a toy linear forecasting problem for which we show that transformers are incapable of converging to their true solution despite their high expressive power. We further identify the attention of transformers as being responsible for this low generalization capacity. Building upon this insight, we propose a shallow lightweight transformer model that successfully escapes bad local minima when optimized with sharpness-aware optimization. We empirically demonstrate that this result extends to all commonly used real-world multivariate time series datasets. In particular, SAMformer surpasses the current state-of-the-art model TSMixer by 14.33% on average, while having ~4 times fewer parameters. The code is available at https://github.com/romilbert/samformer.
Breaking Boundaries: Balancing Performance and Robustness in Deep Wireless Traffic Forecasting
Nov 28, 2023Balancing the trade-off between accuracy and robustness is a long-standing challenge in time series forecasting. While most of existing robust algorithms have achieved certain suboptimal performance on clean data, sustaining the same performance level in the presence of data perturbations remains extremely hard. In this paper, we study a wide array of perturbation scenarios and propose novel defense mechanisms against adversarial attacks using real-world telecom data. We compare our strategy against two existing adversarial training algorithms under a range of maximal allowed perturbations, defined using $\ell_{\infty}$-norm, $\in [0.1,0.4]$. Our findings reveal that our hybrid strategy, which is composed of a classifier to detect adversarial examples, a denoiser to eliminate noise from the perturbed data samples, and a standard forecaster, achieves the best performance on both clean and perturbed data. Our optimal model can retain up to $92.02\%$ the performance of the original forecasting model in terms of Mean Squared Error (MSE) on clean data, while being more robust than the standard adversarially trained models on perturbed data. Its MSE is 2.71$\times$ and 2.51$\times$ lower than those of comparing methods on normal and perturbed data, respectively. In addition, the components of our models can be trained in parallel, resulting in better computational efficiency. Our results indicate that we can optimally balance the trade-off between the performance and robustness of forecasting models by improving the classifier and denoiser, even in the presence of sophisticated and destructive poisoning attacks.
* Accepted for presentation at the ARTMAN workshop, part of the ACM Conference on Computer and Communications Security (CCS), 2023