 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for Multivariate Time Series Classification: An Experimental Study
Jun 10, 2024



Our study investigates the impact of data augmentation on the performance of multivariate time series models, focusing on datasets from the UCR archive. Despite the limited size of these datasets, we achieved classification accuracy improvements in 10 out of 13 datasets using the Rocket and InceptionTime models. This highlights the essential role of sufficient data in training effective models, paralleling the advancements seen in computer vision. Our work delves into adapting and applying existing methods in innovative ways to the domain of multivariate time series classification. Our comprehensive exploration of these techniques sets a new standard for addressing data scarcity in time series analysis, emphasizing that diverse augmentation strategies are crucial for unlocking the potential of both traditional and deep learning models. Moreover, by meticulously analyzing and applying a variety of augmentation techniques, we demonstrate that strategic data enrichment can enhance model accuracy. This not only establishes a benchmark for future research in time series analysis but also underscores the importance of adopting varied augmentation approaches to improve model performance in the face of limited data availability.
Breaking Boundaries: Balancing Performance and Robustness in Deep Wireless Traffic Forecasting
Nov 28, 2023Balancing the trade-off between accuracy and robustness is a long-standing challenge in time series forecasting. While most of existing robust algorithms have achieved certain suboptimal performance on clean data, sustaining the same performance level in the presence of data perturbations remains extremely hard. In this paper, we study a wide array of perturbation scenarios and propose novel defense mechanisms against adversarial attacks using real-world telecom data. We compare our strategy against two existing adversarial training algorithms under a range of maximal allowed perturbations, defined using $\ell_{\infty}$-norm, $\in [0.1,0.4]$. Our findings reveal that our hybrid strategy, which is composed of a classifier to detect adversarial examples, a denoiser to eliminate noise from the perturbed data samples, and a standard forecaster, achieves the best performance on both clean and perturbed data. Our optimal model can retain up to $92.02\%$ the performance of the original forecasting model in terms of Mean Squared Error (MSE) on clean data, while being more robust than the standard adversarially trained models on perturbed data. Its MSE is 2.71$\times$ and 2.51$\times$ lower than those of comparing methods on normal and perturbed data, respectively. In addition, the components of our models can be trained in parallel, resulting in better computational efficiency. Our results indicate that we can optimally balance the trade-off between the performance and robustness of forecasting models by improving the classifier and denoiser, even in the presence of sophisticated and destructive poisoning attacks.
* Accepted for presentation at the ARTMAN workshop, part of the ACM Conference on Computer and Communications Security (CCS), 2023
Multivariate Time Series Anomaly Detection: Fancy Algorithms and Flawed Evaluation Methodology
Aug 24, 2023



Multivariate Time Series (MVTS) anomaly detection is a long-standing and challenging research topic that has attracted tremendous research effort from both industry and academia recently. However, a careful study of the literature makes us realize that 1) the community is active but not as organized as other sibling machine learning communities such as Computer Vision (CV) and Natural Language Processing (NLP), and 2) most proposed solutions are evaluated using either inappropriate or highly flawed protocols, with an apparent lack of scientific foundation. So flawed is one very popular protocol, the so-called \pa protocol, that a random guess can be shown to systematically outperform \emph{all} algorithms developed so far. In this paper, we review and evaluate many recent algorithms using more robust protocols and discuss how a normally good protocol may have weaknesses in the context of MVTS anomaly detection and how to mitigate them. We also share our concerns about benchmark datasets, experiment design and evaluation methodology we observe in many works. Furthermore, we propose a simple, yet challenging, baseline algorithm based on Principal Components Analysis (PCA) that surprisingly outperforms many recent Deep Learning (DL) based approaches on popular benchmark datasets. The main objective of this work is to stimulate more effort towards important aspects of the research such as data, experiment design, evaluation methodology and result interpretability, instead of putting the highest weight on the design of increasingly more complex and "fancier" algorithms.
A Generic Approach to Integrating Time into Spatial-Temporal Forecasting via Conditional Neural Fields
May 17, 2023Self-awareness is the key capability of autonomous systems, e.g., autonomous driving network, which relies on highly efficient time series forecasting algorithm to enable the system to reason about the future state of the environment, as well as its effect on the system behavior as time progresses. Recently, a large number of forecasting algorithms using either convolutional neural networks or graph neural networks have been developed to exploit the complex temporal and spatial dependencies present in the time series. While these solutions have shown significant advantages over statistical approaches, one open question is to effectively incorporate the global information which represents the seasonality patterns via the time component of time series into the forecasting models to improve their accuracy. This paper presents a general approach to integrating the time component into forecasting models. The main idea is to employ conditional neural fields to represent the auxiliary features extracted from the time component to obtain the global information, which will be effectively combined with the local information extracted from autoregressive neural networks through a layer-wise gated fusion module. Extensive experiments on road traffic and cellular network traffic datasets prove the effectiveness of the proposed approach.
Little Help Makes a Big Difference: Leveraging Active Learning to Improve Unsupervised Time Series Anomaly Detection
Jan 25, 2022



Key Performance Indicators (KPI), which are essentially time series data, have been widely used to indicate the performance of telecom networks. Based on the given KPIs, a large set of anomaly detection algorithms have been deployed for detecting the unexpected network incidents. Generally, unsupervised anomaly detection algorithms gain more popularity than the supervised ones, due to the fact that labeling KPIs is extremely time- and resource-consuming, and error-prone. However, those unsupervised anomaly detection algorithms often suffer from excessive false alarms, especially in the presence of concept drifts resulting from network re-configurations or maintenance. To tackle this challenge and improve the overall performance of unsupervised anomaly detection algorithms, we propose to use active learning to introduce and benefit from the feedback of operators, who can verify the alarms (both false and true ones) and label the corresponding KPIs with reasonable effort. Specifically, we develop three query strategies to select the most informative and representative samples to label. We also develop an efficient method to update the weights of Isolation Forest and optimally adjust the decision threshold, so as to eventually improve the performance of detection model. The experiments with one public dataset and one proprietary dataset demonstrate that our active learning empowered anomaly detection pipeline could achieve performance gain, in terms of F1-score, more than 50% over the baseline algorithm. It also outperforms the existing active learning based methods by approximately 6%-10%, with significantly reduced budget (the ratio of samples to be labeled).
Anomalous Communications Detection in IoT Networks Using Sparse Autoencoders
Dec 26, 2019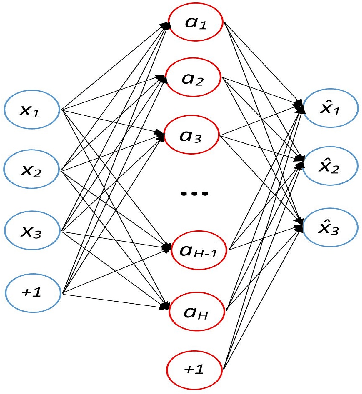
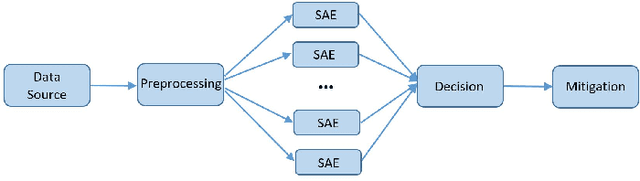
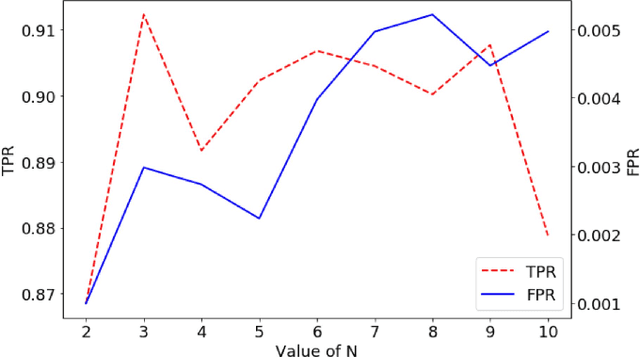

Nowadays, IoT devices have been widely deployed for enabling various smart services, such as, smart home or e-healthcare. However, security remains as one of the paramount concern as many IoT devices are vulnerable. Moreover, IoT malware are constantly evolving and getting more sophisticated. IoT devices are intended to perform very specific tasks, so their networking behavior is expected to be reasonably stable and predictable. Any significant behavioral deviation from the normal patterns would indicate anomalous events. In this paper, we present a method to detect anomalous network communications in IoT networks using a set of sparse autoencoders. The proposed approach allows us to differentiate malicious communications from legitimate ones. So that, if a device is compromised only malicious communications can be dropped while the service provided by the device is not totally interrupted. To characterize network behavior, bidirectional TCP flows are extracted and described using statistics on the size of the first N packets sent and received, along with statistics on the corresponding inter-arrival times between packets. A set of sparse autoencoders is then trained to learn the profile of the legitimate communications generated by an experimental smart home network. Depending on the value of N, the developed model achieves attack detection rates ranging from 86.9% to 91.2%, and false positive rates ranging from 0.1% to 0.5%.