 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Meets Queue-Reactive: A Framework for Realistic Limit Order Book Simulation
Jan 15, 2025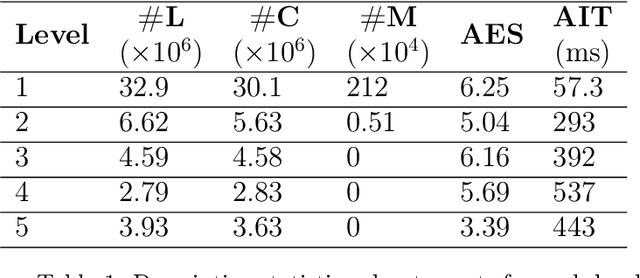

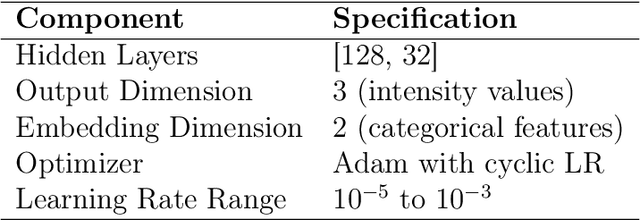
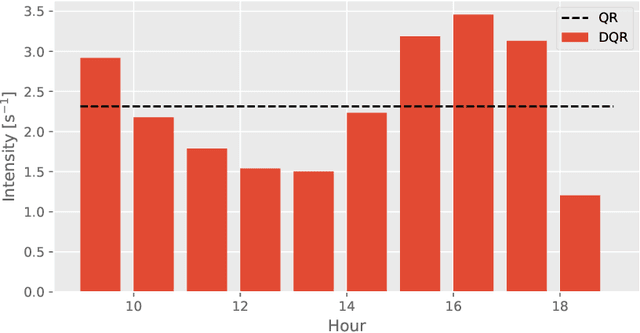
The Queue-Reactive model introduced by Huang et al. (2015) has become a standard tool for limit order book modeling, widely adopted by both researchers and practitioners for its simplicity and effectiveness. We present the Multidimensional Deep Queue-Reactive (MDQR) model, which extends this framework in three ways: it relaxes the assumption of queue independence, enriches the state space with market features, and models the distribution of order sizes. Through a neural network architecture, the model learns complex dependencies between different price levels and adapts to varying market conditions, while preserving the interpretable point-process foundation of the original framework. Using data from the Bund futures market, we show that MDQR captures key market properties including the square-root law of market impact, cross-queue correlations, and realistic order size patterns. The model demonstrates particular strength in reproducing both conditional and stationary distributions of order sizes, as well as various stylized facts of market microstructure. The model achieves this while maintaining the computational efficiency needed for practical applications such as strategy development through reinforcement learning or realistic backtesting.
Little Help Makes a Big Difference: Leveraging Active Learning to Improve Unsupervised Time Series Anomaly Detection
Jan 25, 2022



Key Performance Indicators (KPI), which are essentially time series data, have been widely used to indicate the performance of telecom networks. Based on the given KPIs, a large set of anomaly detection algorithms have been deployed for detecting the unexpected network incidents. Generally, unsupervised anomaly detection algorithms gain more popularity than the supervised ones, due to the fact that labeling KPIs is extremely time- and resource-consuming, and error-prone. However, those unsupervised anomaly detection algorithms often suffer from excessive false alarms, especially in the presence of concept drifts resulting from network re-configurations or maintenance. To tackle this challenge and improve the overall performance of unsupervised anomaly detection algorithms, we propose to use active learning to introduce and benefit from the feedback of operators, who can verify the alarms (both false and true ones) and label the corresponding KPIs with reasonable effort. Specifically, we develop three query strategies to select the most informative and representative samples to label. We also develop an efficient method to update the weights of Isolation Forest and optimally adjust the decision threshold, so as to eventually improve the performance of detection model. The experiments with one public dataset and one proprietary dataset demonstrate that our active learning empowered anomaly detection pipeline could achieve performance gain, in terms of F1-score, more than 50% over the baseline algorithm. It also outperforms the existing active learning based methods by approximately 6%-10%, with significantly reduced budget (the ratio of samples to be labeled).