 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVSS-BERT: Explainable Natural Language Processing to Determine the Severity of a Computer Security Vulnerability from its Description
Nov 16, 2021

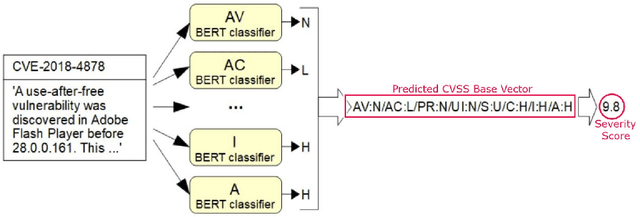

When a new computer security vulnerability is publicly disclosed, only a textual description of it is available. Cybersecurity experts later provide an analysis of the severity of the vulnerability using the Common Vulnerability Scoring System (CVSS). Specifically, the different characteristics of the vulnerability are summarized into a vector (consisting of a set of metrics), from which a severity score is computed. However, because of the high number of vulnerabilities disclosed everyday this process requires lot of manpower, and several days may pass before a vulnerability is analyzed. We propose to leverage recent advances in the field of Natural Language Processing (NLP) to determine the CVSS vector and the associated severity score of a vulnerability from its textual description in an explainable manner. To this purpose, we trained multiple BERT classifiers, one for each metric composing the CVSS vector. Experimental results show that our trained classifiers are able to determine the value of the metrics of the CVSS vector with high accuracy. The severity score computed from the predicted CVSS vector is also very close to the real severity score attributed by a human expert. For explainability purpose, gradient-based input saliency method was used to determine the most relevant input words for a given prediction made by our classifiers. Often, the top relevant words include terms in agreement with the rationales of a human cybersecurity expert, making the explanation comprehensible for end-users.
Anomalous Communications Detection in IoT Networks Using Sparse Autoencoders
Dec 26, 2019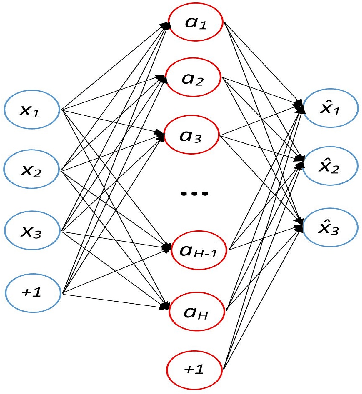
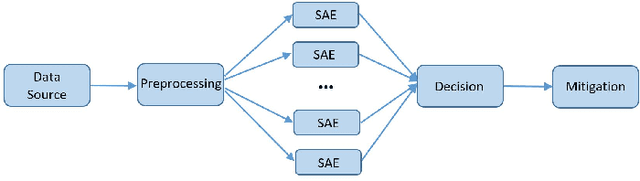
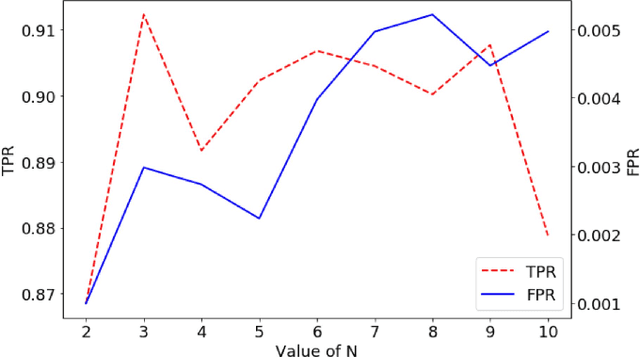

Nowadays, IoT devices have been widely deployed for enabling various smart services, such as, smart home or e-healthcare. However, security remains as one of the paramount concern as many IoT devices are vulnerable. Moreover, IoT malware are constantly evolving and getting more sophisticated. IoT devices are intended to perform very specific tasks, so their networking behavior is expected to be reasonably stable and predictable. Any significant behavioral deviation from the normal patterns would indicate anomalous events. In this paper, we present a method to detect anomalous network communications in IoT networks using a set of sparse autoencoders. The proposed approach allows us to differentiate malicious communications from legitimate ones. So that, if a device is compromised only malicious communications can be dropped while the service provided by the device is not totally interrupted. To characterize network behavior, bidirectional TCP flows are extracted and described using statistics on the size of the first N packets sent and received, along with statistics on the corresponding inter-arrival times between packets. A set of sparse autoencoders is then trained to learn the profile of the legitimate communications generated by an experimental smart home network. Depending on the value of N, the developed model achieves attack detection rates ranging from 86.9% to 91.2%, and false positive rates ranging from 0.1% to 0.5%.