 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Benefits of In-Tool Learning for Large Language Models
Aug 28, 2025Tool-augmented language models, equipped with retrieval, memory, or external APIs, are reshaping AI, yet their theoretical advantages remain underexplored. In this paper, we address this question by demonstrating the benefits of in-tool learning (external retrieval) over in-weight learning (memorization) for factual recall. We show that the number of facts a model can memorize solely in its weights is fundamentally limited by its parameter count. In contrast, we prove that tool-use enables unbounded factual recall via a simple and efficient circuit construction. These results are validated in controlled experiments, where tool-using models consistently outperform memorizing ones. We further show that for pretrained large language models, teaching tool-use and general rules is more effective than finetuning facts into memory. Our work provides both a theoretical and empirical foundation, establishing why tool-augmented workflows are not just practical, but provably more scalable.
Easing Optimization Paths: a Circuit Perspective
Jan 04, 2025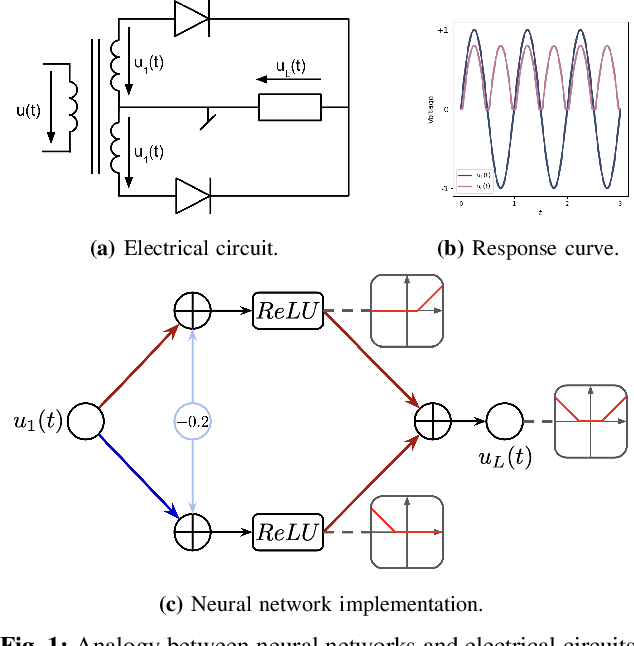
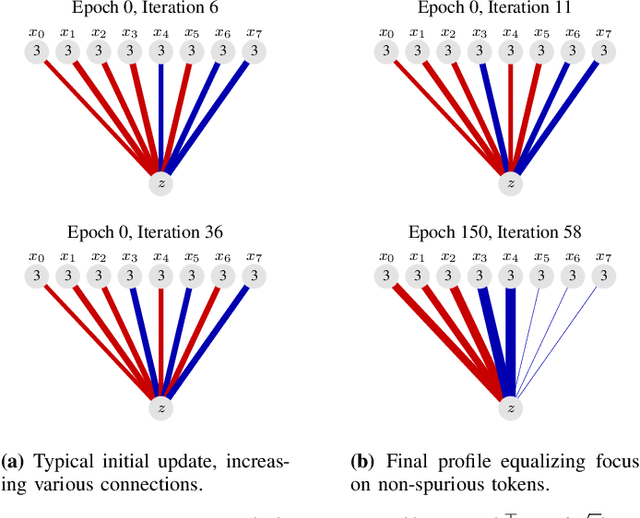
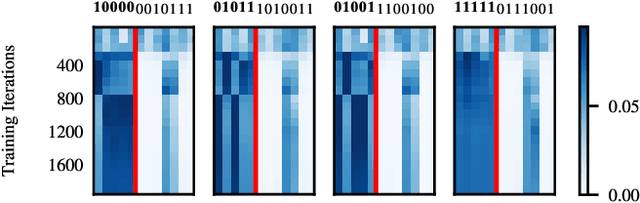
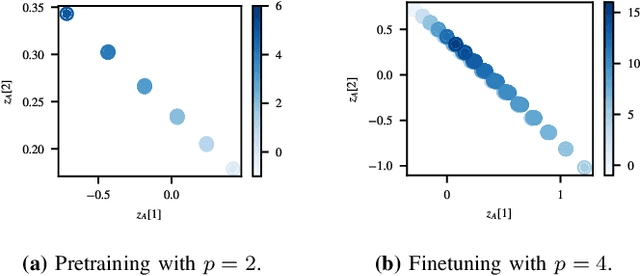
Gradient descent is the method of choice for training large artificial intelligence systems. As these systems become larger, a better understanding of the mechanisms behind gradient training would allow us to alleviate compute costs and help steer these systems away from harmful behaviors. To that end, we suggest utilizing the circuit perspective brought forward by mechanistic interpretability. After laying out our intuition, we illustrate how it enables us to design a curriculum for efficient learning in a controlled setting. The code is available at \url{https://github.com/facebookresearch/pal}.
Scaling Laws with Hidden Structure
Nov 05, 2024Statistical learning in high-dimensional spaces is challenging without a strong underlying data structure. Recent advances with foundational models suggest that text and image data contain such hidden structures, which help mitigate the curse of dimensionality. Inspired by results from nonparametric statistics, we hypothesize that this phenomenon can be partially explained in terms of decomposition of complex tasks into simpler subtasks. In this paper, we present a controlled experimental framework to test whether neural networks can indeed exploit such ``hidden factorial structures.'' We find that they do leverage these latent patterns to learn discrete distributions more efficiently, and derive scaling laws linking model sizes, hidden factorizations, and accuracy. We also study the interplay between our structural assumptions and the models' capacity for generalization.
A Visual Case Study of the Training Dynamics in Neural Networks
Oct 31, 2024



This paper introduces a visual sandbox designed to explore the training dynamics of a small-scale transformer model, with the embedding dimension constrained to $d=2$. This restriction allows for a comprehensive two-dimensional visualization of each layer's dynamics. Through this approach, we gain insights into training dynamics, circuit transferability, and the causes of loss spikes, including those induced by the high curvature of normalization layers. We propose strategies to mitigate these spikes, demonstrating how good visualization facilitates the design of innovative ideas of practical interest. Additionally, we believe our sandbox could assist theoreticians in assessing essential training dynamics mechanisms and integrating them into future theories. The code is available at https://github.com/facebookresearch/pal.
$\mathbb{X}$-Sample Contrastive Loss: Improving Contrastive Learning with Sample Similarity Graphs
Jul 25, 2024



Learning good representations involves capturing the diverse ways in which data samples relate. Contrastive loss - an objective matching related samples - underlies methods from self-supervised to multimodal learning. Contrastive losses, however, can be viewed more broadly as modifying a similarity graph to indicate how samples should relate in the embedding space. This view reveals a shortcoming in contrastive learning: the similarity graph is binary, as only one sample is the related positive sample. Crucially, similarities \textit{across} samples are ignored. Based on this observation, we revise the standard contrastive loss to explicitly encode how a sample relates to others. We experiment with this new objective, called $\mathbb{X}$-Sample Contrastive, to train vision models based on similarities in class or text caption descriptions. Our study spans three scales: ImageNet-1k with 1 million, CC3M with 3 million, and CC12M with 12 million samples. The representations learned via our objective outperform both contrastive self-supervised and vision-language models trained on the same data across a range of tasks. When training on CC12M, we outperform CLIP by $0.6\%$ on both ImageNet and ImageNet Real. Our objective appears to work particularly well in lower-data regimes, with gains over CLIP of $16.8\%$ on ImageNet and $18.1\%$ on ImageNet Real when training with CC3M. Finally, our objective seems to encourage the model to learn representations that separate objects from their attributes and backgrounds, with gains of $3.3$-$5.6$\% over CLIP on ImageNet9. We hope the proposed solution takes a small step towards developing richer learning objectives for understanding sample relations in foundation models.
Iteration Head: A Mechanistic Study of Chain-of-Thought
Jun 04, 2024Chain-of-Thought (CoT) reasoning is known to improve Large Language Models both empirically and in terms of theoretical approximation power. However, our understanding of the inner workings and conditions of apparition of CoT capabilities remains limited. This paper helps fill this gap by demonstrating how CoT reasoning emerges in transformers in a controlled and interpretable setting. In particular, we observe the appearance of a specialized attention mechanism dedicated to iterative reasoning, which we coined "iteration heads". We track both the emergence and the precise working of these iteration heads down to the attention level, and measure the transferability of the CoT skills to which they give rise between tasks.
Learning Associative Memories with Gradient Descent
Feb 28, 2024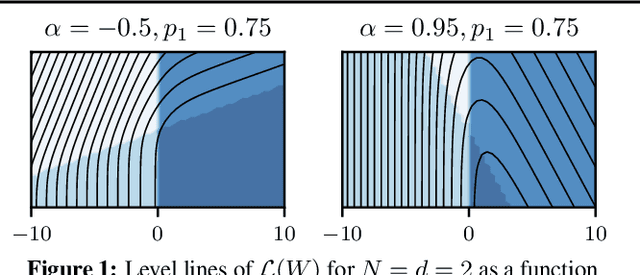
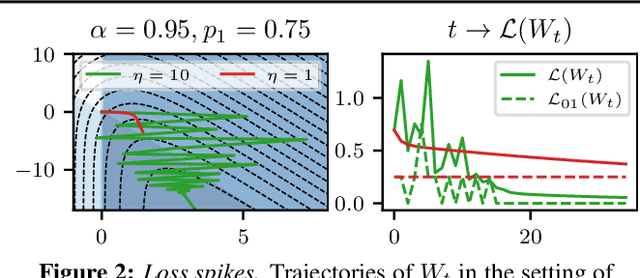
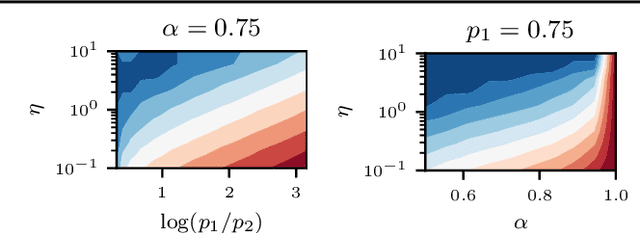
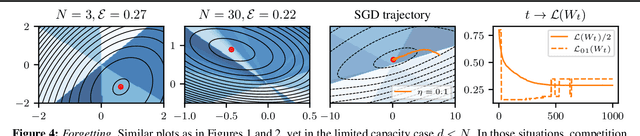
This work focuses on the training dynamics of one associative memory module storing outer products of token embeddings. We reduce this problem to the study of a system of particles, which interact according to properties of the data distribution and correlations between embeddings. Through theory and experiments, we provide several insights. In overparameterized regimes, we obtain logarithmic growth of the ``classification margins.'' Yet, we show that imbalance in token frequencies and memory interferences due to correlated embeddings lead to oscillatory transitory regimes. The oscillations are more pronounced with large step sizes, which can create benign loss spikes, although these learning rates speed up the dynamics and accelerate the asymptotic convergence. In underparameterized regimes, we illustrate how the cross-entropy loss can lead to suboptimal memorization schemes. Finally, we assess the validity of our findings on small Transformer models.
Mode Estimation with Partial Feedback
Feb 20, 2024
The combination of lightly supervised pre-training and online fine-tuning has played a key role in recent AI developments. These new learning pipelines call for new theoretical frameworks. In this paper, we formalize core aspects of weakly supervised and active learning with a simple problem: the estimation of the mode of a distribution using partial feedback. We show how entropy coding allows for optimal information acquisition from partial feedback, develop coarse sufficient statistics for mode identification, and adapt bandit algorithms to our new setting. Finally, we combine those contributions into a statistically and computationally efficient solution to our problem.
Touring sampling with pushforward maps
Nov 23, 2023The number of sampling methods could be daunting for a practitioner looking to cast powerful machine learning methods to their specific problem. This paper takes a theoretical stance to review and organize many sampling approaches in the ``generative modeling'' setting, where one wants to generate new data that are similar to some training examples. By revealing links between existing methods, it might prove useful to overcome some of the current challenges in sampling with diffusion models, such as long inference time due to diffusion simulation, or the lack of diversity in generated samples.
Scaling Laws for Associative Memories
Oct 04, 2023Learning arguably involves the discovery and memorization of abstract rules. The aim of this paper is to study associative memory mechanisms. Our model is based on high-dimensional matrices consisting of outer products of embeddings, which relates to the inner layers of transformer language models. We derive precise scaling laws with respect to sample size and parameter size, and discuss the statistical efficiency of different estimators, including optimization-based algorithms. We provide extensive numerical experiments to validate and interpret theoretical results, including fine-grained visualizations of the stored memory associations.