 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic rating of incomplete hippocampal inversions evaluated across multiple cohorts
Aug 05, 2024



Incomplete Hippocampal Inversion (IHI), sometimes called hippocampal malrotation, is an atypical anatomical pattern of the hippocampus found in about 20% of the general population. IHI can be visually assessed on coronal slices of T1 weighted MR images, using a composite score that combines four anatomical criteria. IHI has been associated with several brain disorders (epilepsy, schizophrenia). However, these studies were based on small samples. Furthermore, the factors (genetic or environmental) that contribute to the genesis of IHI are largely unknown. Large-scale studies are thus needed to further understand IHI and their potential relationships to neurological and psychiatric disorders. However, visual evaluation is long and tedious, justifying the need for an automatic method. In this paper, we propose, for the first time, to automatically rate IHI. We proceed by predicting four anatomical criteria, which are then summed up to form the IHI score, providing the advantage of an interpretable score. We provided an extensive experimental investigation of different machine learning methods and training strategies. We performed automatic rating using a variety of deep learning models (conv5-FC3, ResNet and SECNN) as well as a ridge regression. We studied the generalization of our models using different cohorts and performed multi-cohort learning. We relied on a large population of 2,008 participants from the IMAGEN study, 993 and 403 participants from the QTIM/QTAB studies as well as 985 subjects from the UKBiobank. We showed that deep learning models outperformed a ridge regression. We demonstrated that the performances of the conv5-FC3 network were at least as good as more complex networks while maintaining a low complexity and computation time. We showed that training on a single cohort may lack in variability while training on several cohorts improves generalization.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2024:016
Continuation of Nesterov's Smoothing for Regression with Structured Sparsity in High-Dimensional Neuroimaging
Apr 22, 2018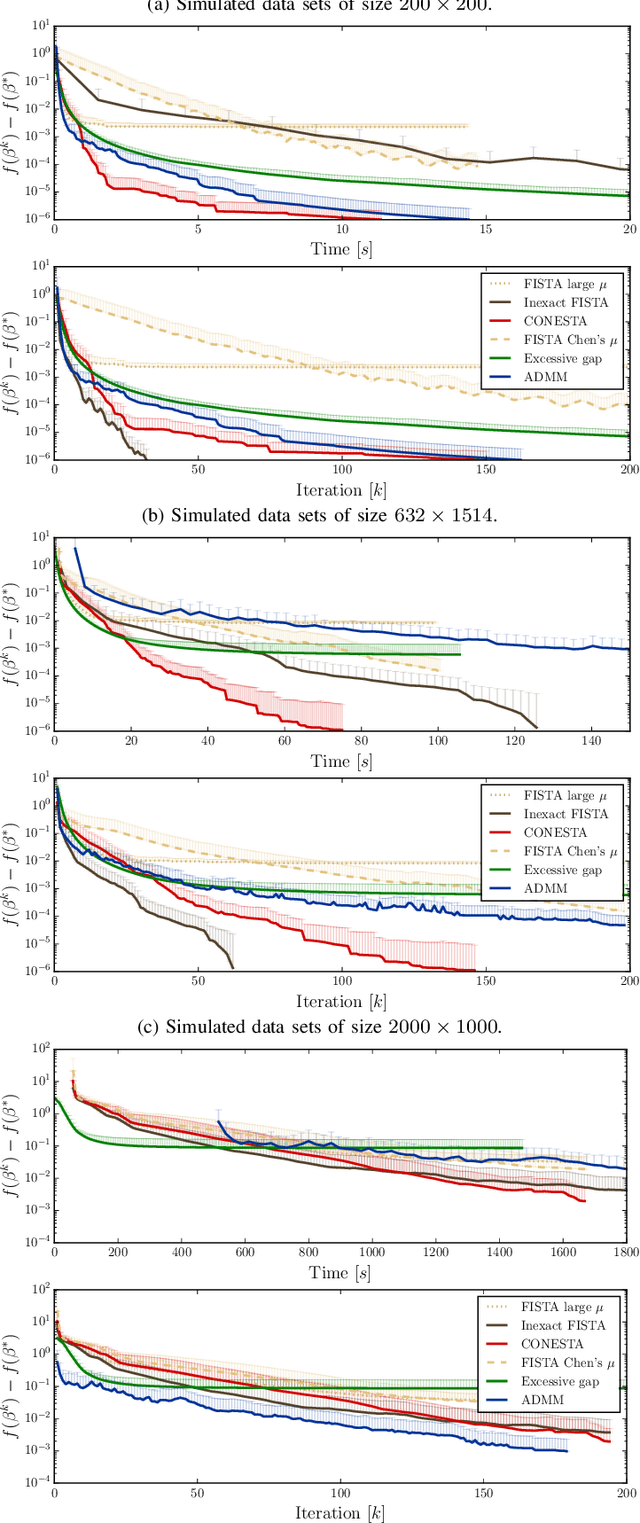
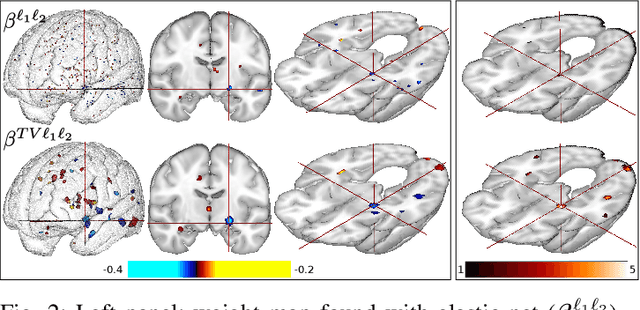
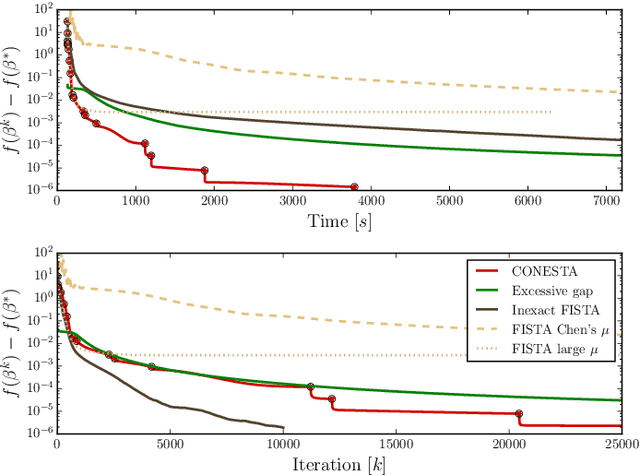
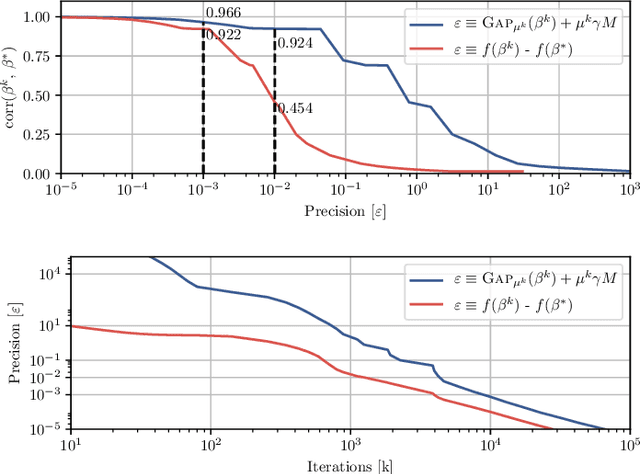
Predictive models can be used on high-dimensional brain images for diagnosis of a clinical condition. Spatial regularization through structured sparsity offers new perspectives in this context and reduces the risk of overfitting the model while providing interpretable neuroimaging signatures by forcing the solution to adhere to domain-specific constraints. Total Variation (TV) enforces spatial smoothness of the solution while segmenting predictive regions from the background. We consider the problem of minimizing the sum of a smooth convex loss, a non-smooth convex penalty (whose proximal operator is known) and a wide range of possible complex, non-smooth convex structured penalties such as TV or overlapping group Lasso. Existing solvers are either limited in the functions they can minimize or in their practical capacity to scale to high-dimensional imaging data. Nesterov's smoothing technique can be used to minimize a large number of non-smooth convex structured penalties but reasonable precision requires a small smoothing parameter, which slows down the convergence speed. To benefit from the versatility of Nesterov's smoothing technique, we propose a first order continuation algorithm, CONESTA, which automatically generates a sequence of decreasing smoothing parameters. The generated sequence maintains the optimal convergence speed towards any globally desired precision. Our main contributions are: To propose an expression of the duality gap to probe the current distance to the global optimum in order to adapt the smoothing parameter and the convergence speed. We provide a convergence rate, which is an improvement over classical proximal gradient smoothing methods. We demonstrate on both simulated and high-dimensional structural neuroimaging data that CONESTA significantly outperforms many state-of-the-art solvers in regard to convergence speed and precision.
A general multiblock method for structured variable selection
Oct 29, 2016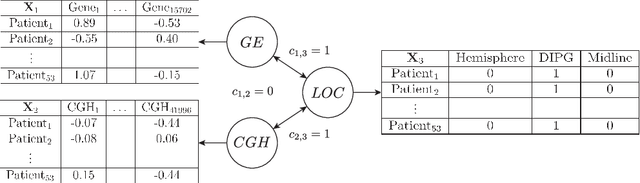
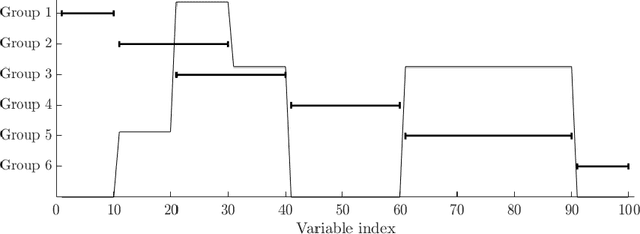
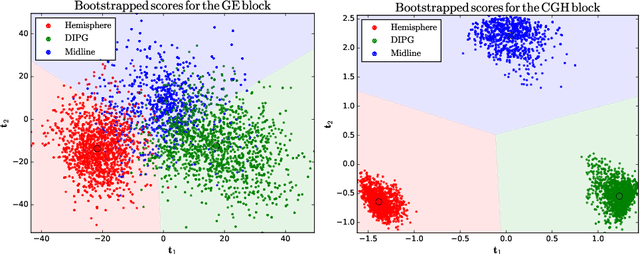
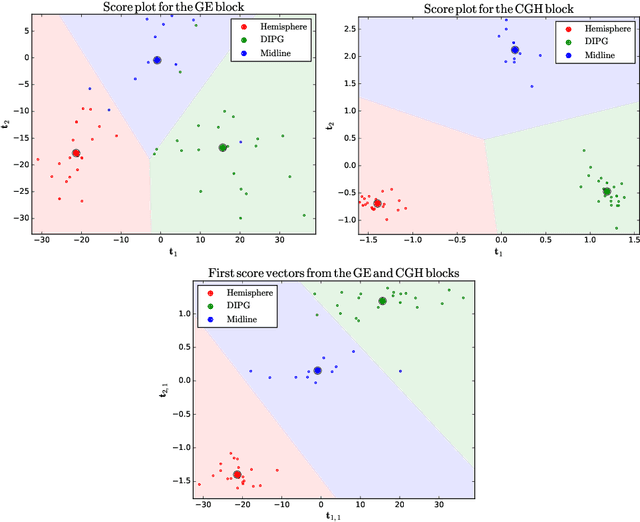
Regularised canonical correlation analysis was recently extended to more than two sets of variables by the multiblock method Regularised generalised canonical correlation analysis (RGCCA). Further, Sparse GCCA (SGCCA) was proposed to address the issue of variable selection. However, for technical reasons, the variable selection offered by SGCCA was restricted to a covariance link between the blocks (i.e., with $\tau=1$). One of the main contributions of this paper is to go beyond the covariance link and to propose an extension of SGCCA for the full RGCCA model (i.e., with $\tau\in[0, 1]$). In addition, we propose an extension of SGCCA that exploits structural relationships between variables within blocks. Specifically, we propose an algorithm that allows structured and sparsity-inducing penalties to be included in the RGCCA optimisation problem. The proposed multiblock method is illustrated on a real three-block high-grade glioma data set, where the aim is to predict the location of the brain tumours, and on a simulated data set, where the aim is to illustrate the method's ability to reconstruct the true underlying weight vectors.
Structured Sparse Principal Components Analysis with the TV-Elastic Net penalty
Sep 14, 2016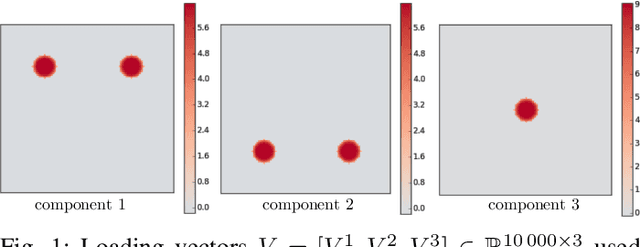
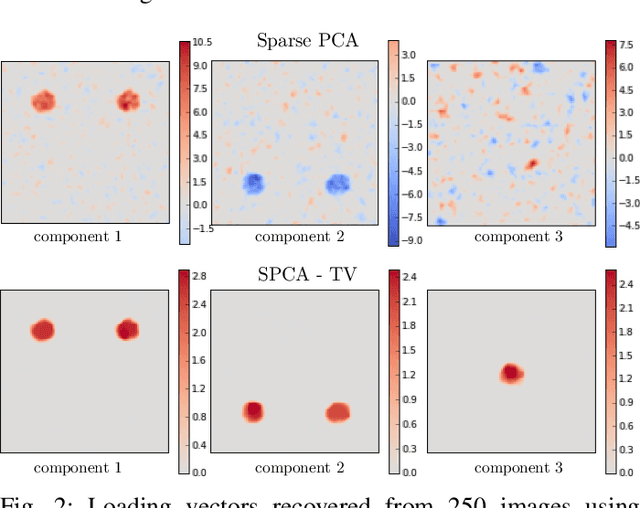
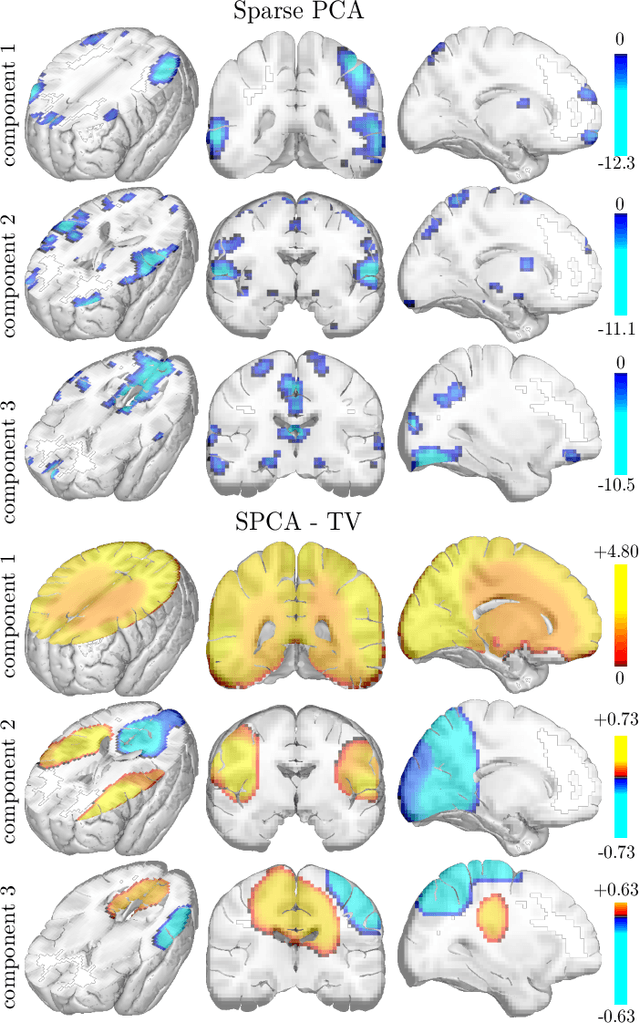
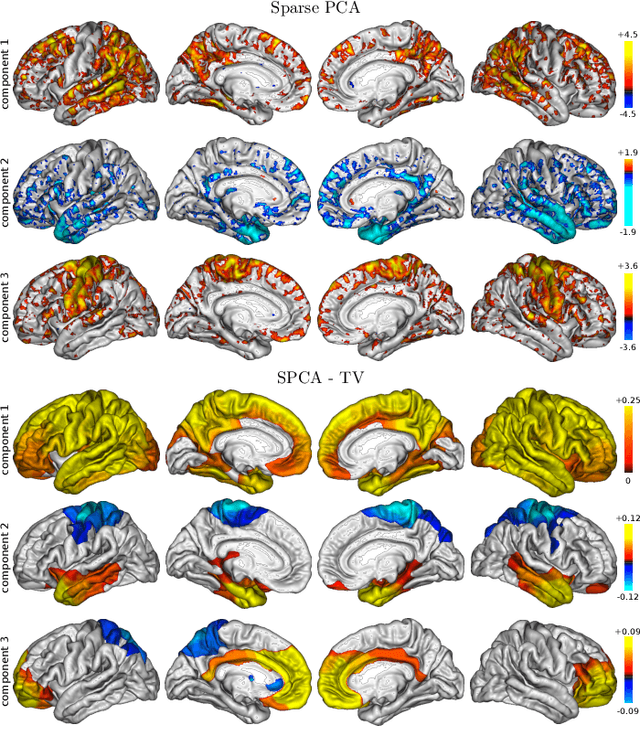
Principal component analysis (PCA) is an exploratory tool widely used in data analysis to uncover dominant patterns of variability within a population. Despite its ability to represent a data set in a low-dimensional space, the interpretability of PCA remains limited. However, in neuroimaging, it is essential to uncover clinically interpretable phenotypic markers that would account for the main variability in the brain images of a population. Recently, some alternatives to the standard PCA approach, such as Sparse PCA, have been proposed, their aim being to limit the density of the components. Nonetheless, sparsity alone does not entirely solve the interpretability problem, since it may yield scattered and unstable components. We hypothesized that the incorporation of prior information regarding the structure of the data may lead to improved relevance and interpretability of brain patterns. We therefore present a simple extension of the popular PCA framework that adds structured sparsity penalties on the loading vectors in order to identify the few stable regions in the brain images accounting for most of the variability. Such structured sparsity can be obtained by combining l1 and total variation (TV) penalties, where the TV regularization encodes higher order information about the structure of the data. This paper presents the structured sparse PCA (denoted SPCA-TV) optimization framework and its resolution. We demonstrate the efficiency and versatility of SPCA-TV on three different data sets. The gains of SPCA-TV over unstructured approaches are significant,since SPCA-TV reveals the variability within a data set in the form of intelligible brain patterns that are easy to interpret, and are more stable across different samples.
Nonlinear functional mapping of the human brain
Sep 08, 2015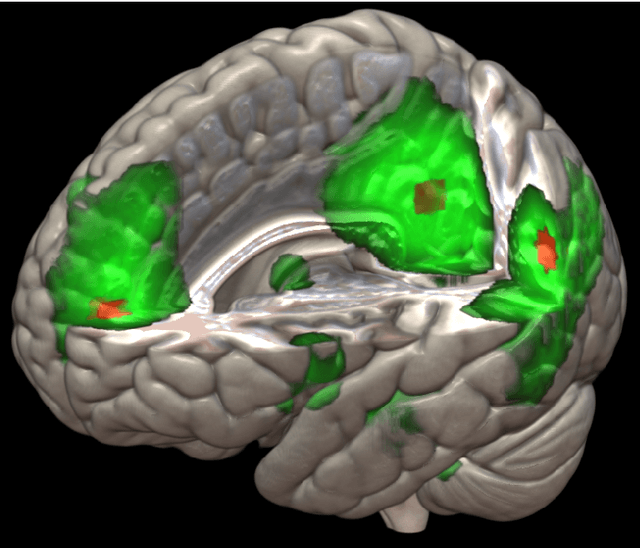
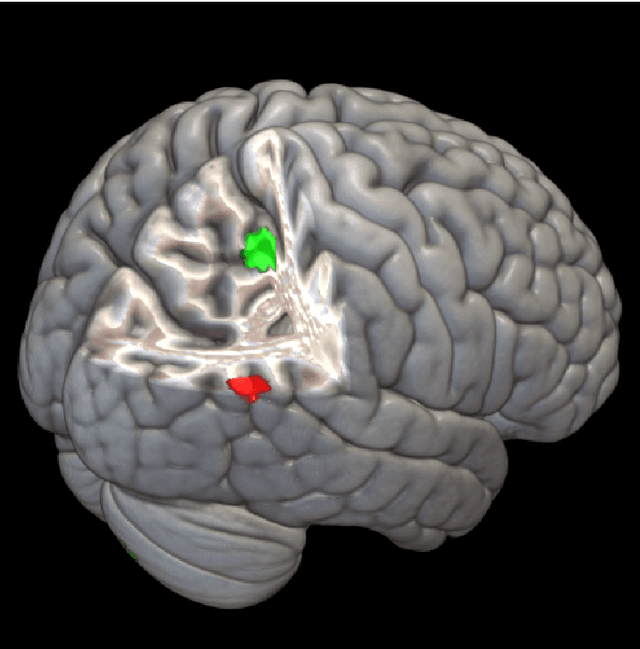
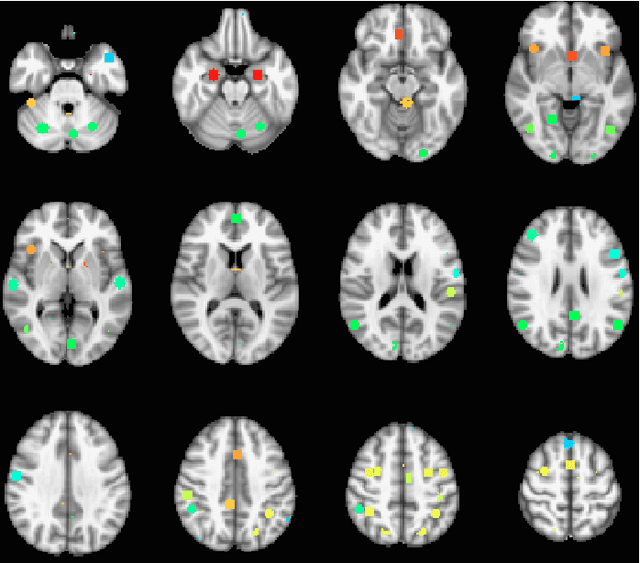
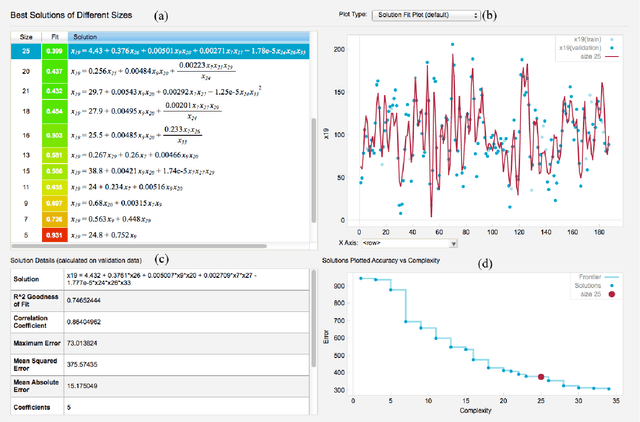
The field of neuroimaging has truly become data rich, and novel analytical methods capable of gleaning meaningful information from large stores of imaging data are in high demand. Those methods that might also be applicable on the level of individual subjects, and thus potentially useful clinically, are of special interest. In the present study, we introduce just such a method, called nonlinear functional mapping (NFM), and demonstrate its application in the analysis of resting state fMRI from a 242-subject subset of the IMAGEN project, a European study of adolescents that includes longitudinal phenotypic, behavioral, genetic, and neuroimaging data. NFM employs a computational technique inspired by biological evolution to discover and mathematically characterize interactions among ROI (regions of interest), without making linear or univariate assumptions. We show that statistics of the resulting interaction relationships comport with recent independent work, constituting a preliminary cross-validation. Furthermore, nonlinear terms are ubiquitous in the models generated by NFM, suggesting that some of the interactions characterized here are not discoverable by standard linear methods of analysis. We discuss one such nonlinear interaction in the context of a direct comparison with a procedure involving pairwise correlation, designed to be an analogous linear version of functional mapping. We find another such interaction that suggests a novel distinction in brain function between drinking and non-drinking adolescents: a tighter coupling of ROI associated with emotion, reward, and interoceptive processes such as thirst, among drinkers. Finally, we outline many improvements and extensions of the methodology to reduce computational expense, complement other analytical tools like graph-theoretic analysis, and allow for voxel level NFM to eliminate the necessity of ROI selection.
Predictive support recovery with TV-Elastic Net penalty and logistic regression: an application to structural MRI
Jul 21, 2014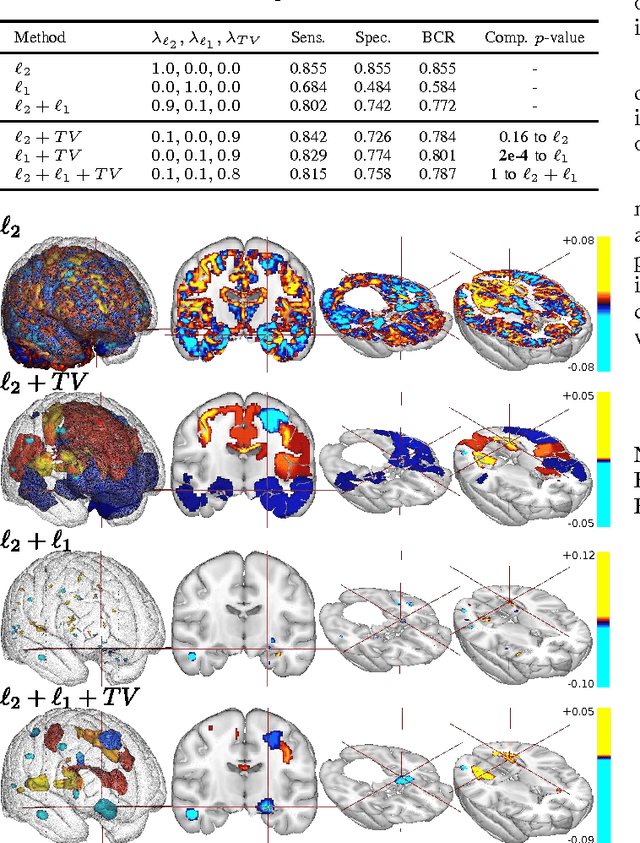
The use of machine-learning in neuroimaging offers new perspectives in early diagnosis and prognosis of brain diseases. Although such multivariate methods can capture complex relationships in the data, traditional approaches provide irregular (l2 penalty) or scattered (l1 penalty) predictive pattern with a very limited relevance. A penalty like Total Variation (TV) that exploits the natural 3D structure of the images can increase the spatial coherence of the weight map. However, TV penalization leads to non-smooth optimization problems that are hard to minimize. We propose an optimization framework that minimizes any combination of l1, l2, and TV penalties while preserving the exact l1 penalty. This algorithm uses Nesterov's smoothing technique to approximate the TV penalty with a smooth function such that the loss and the penalties are minimized with an exact accelerated proximal gradient algorithm. We propose an original continuation algorithm that uses successively smaller values of the smoothing parameter to reach a prescribed precision while achieving the best possible convergence rate. This algorithm can be used with other losses or penalties. The algorithm is applied on a classification problem on the ADNI dataset. We observe that the TV penalty does not necessarily improve the prediction but provides a major breakthrough in terms of support recovery of the predictive brain regions.
PyXNAT: XNAT in Python
Jan 29, 2013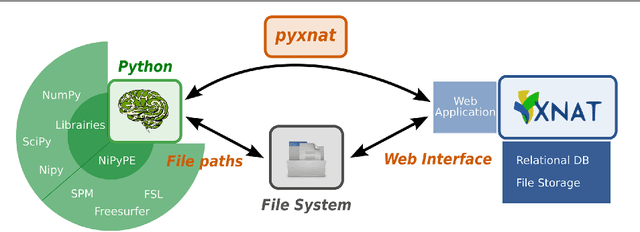


As neuroimaging databases grow in size and complexity, the time researchers spend investigating and managing the data increases to the expense of data analysis. As a result, investigators rely more and more heavily on scripting using high-level languages to automate data management and processing tasks. For this, a structured and programmatic access to the data store is necessary. Web services are a first step toward this goal. They however lack in functionality and ease of use because they provide only low level interfaces to databases. We introduce here PyXNAT, a Python module that interacts with The Extensible Neuroimaging Archive Toolkit (XNAT) through native Python calls across multiple operating systems. The choice of Python enables PyXNAT to expose the XNAT Web Services and unify their features with a higher level and more expressive language. PyXNAT provides XNAT users direct access to all the scientific packages in Python. Finally PyXNAT aims to be efficient and easy to use, both as a backend library to build XNAT clients and as an alternative frontend from the command line.