 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnconstrained Scene Generation with Locally Conditioned Radiance Fields
Apr 01, 2021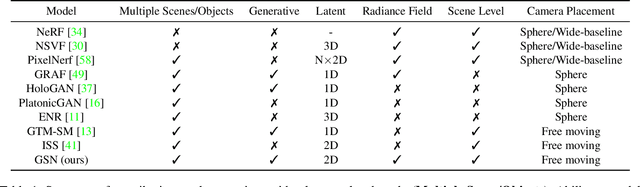
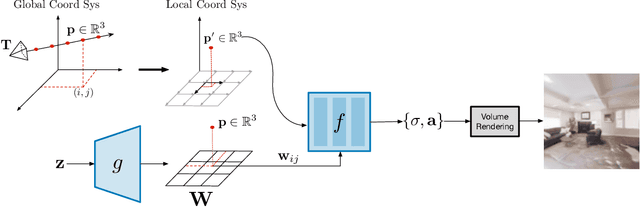

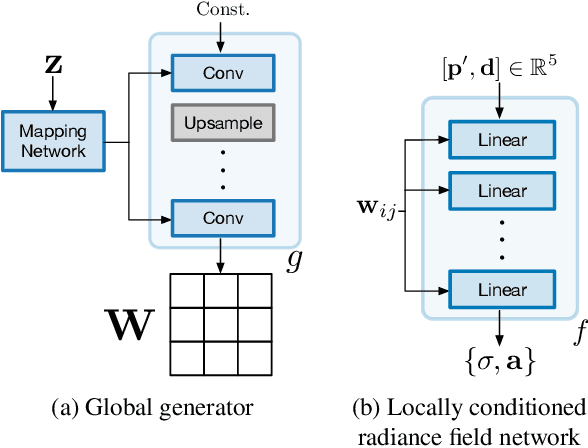
We tackle the challenge of learning a distribution over complex, realistic, indoor scenes. In this paper, we introduce Generative Scene Networks (GSN), which learns to decompose scenes into a collection of many local radiance fields that can be rendered from a free moving camera. Our model can be used as a prior to generate new scenes, or to complete a scene given only sparse 2D observations. Recent work has shown that generative models of radiance fields can capture properties such as multi-view consistency and view-dependent lighting. However, these models are specialized for constrained viewing of single objects, such as cars or faces. Due to the size and complexity of realistic indoor environments, existing models lack the representational capacity to adequately capture them. Our decomposition scheme scales to larger and more complex scenes while preserving details and diversity, and the learned prior enables high-quality rendering from viewpoints that are significantly different from observed viewpoints. When compared to existing models, GSN produces quantitatively higher-quality scene renderings across several different scene datasets.
The GIST and RIST of Iterative Self-Training for Semi-Supervised Segmentation
Mar 31, 2021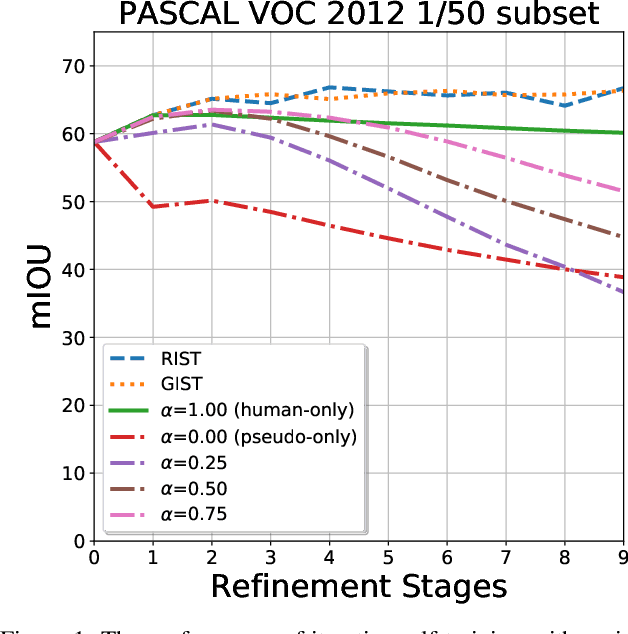
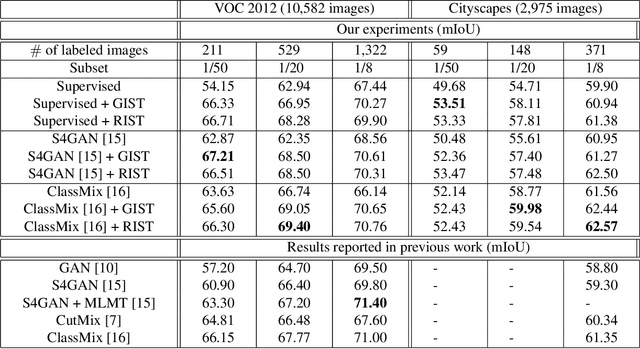

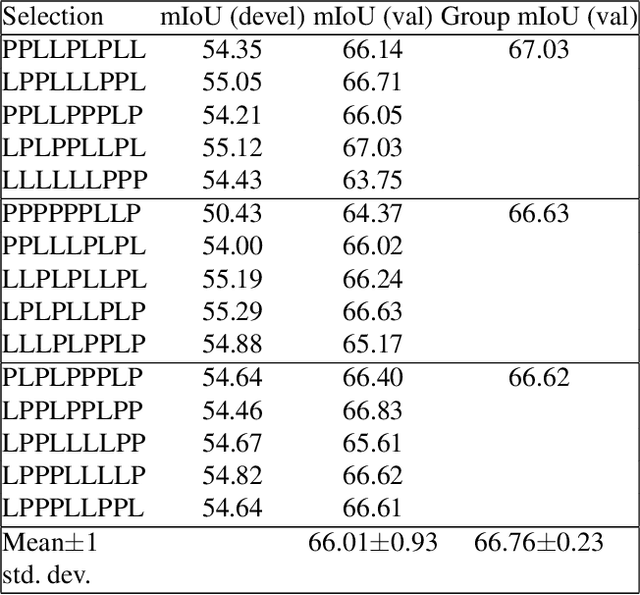
We consider the task of semi-supervised semantic segmentation, where we aim to produce pixel-wise semantic object masks given only a small number of human-labeled training examples. We focus on iterative self-training methods in which we explore the behavior of self-training over multiple refinement stages. We show that iterative self-training leads to performance degradation if done naively with a fixed ratio of human-labeled to pseudo-labeled training examples. We propose Greedy Iterative Self-Training (GIST) and Random Iterative Self-Training (RIST) strategies that alternate between training on either human-labeled data or pseudo-labeled data at each refinement stage, resulting in a performance boost rather than degradation. We further show that GIST and RIST can be combined with existing SOTA methods to boost performance, yielding new SOTA results in Pascal VOC 2012 and Cityscapes dataset across five out of six subsets.
Building LEGO Using Deep Generative Models of Graphs
Dec 21, 2020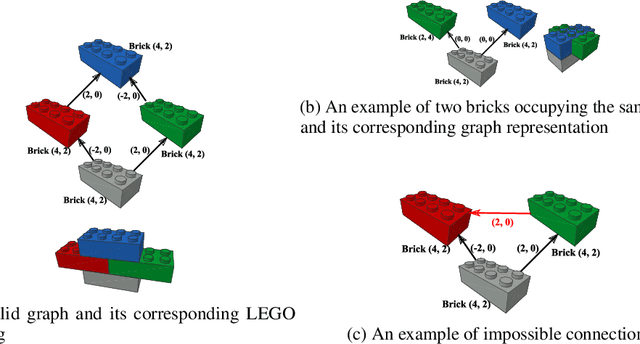
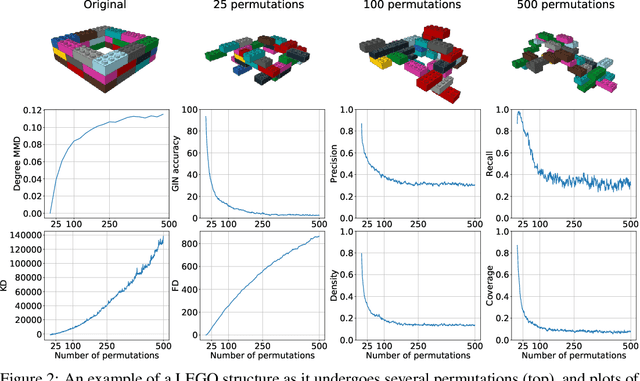
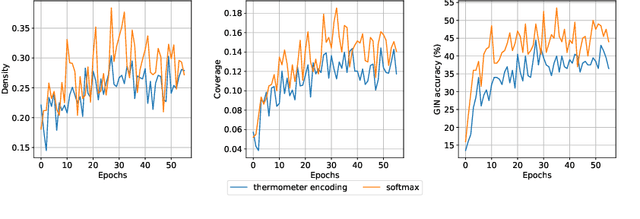
Generative models are now used to create a variety of high-quality digital artifacts. Yet their use in designing physical objects has received far less attention. In this paper, we advocate for the construction toy, LEGO, as a platform for developing generative models of sequential assembly. We develop a generative model based on graph-structured neural networks that can learn from human-built structures and produce visually compelling designs. Our code is released at: https://github.com/uoguelph-mlrg/GenerativeLEGO.
Instance Selection for GANs
Jul 30, 2020
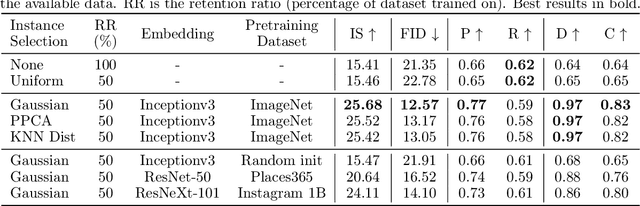
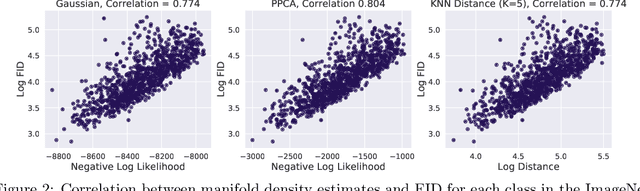
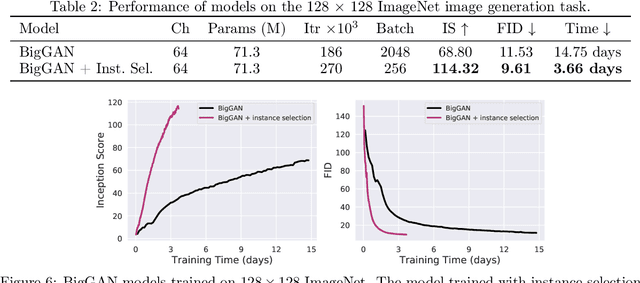
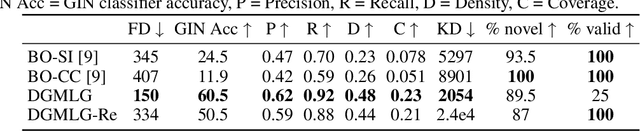
Recent advances in Generative Adversarial Networks (GANs) have led to their widespread adoption for the purposes of generating high quality synthetic imagery. While capable of generating photo-realistic images, these models often produce unrealistic samples which fall outside of the data manifold. Several recently proposed techniques attempt to avoid spurious samples, either by rejecting them after generation, or by truncating the model's latent space. While effective, these methods are inefficient, as large portions of model capacity are dedicated towards representing samples that will ultimately go unused. In this work we propose a novel approach to improve sample quality: altering the training dataset via instance selection before model training has taken place. To this end, we embed data points into a perceptual feature space and use a simple density model to remove low density regions from the data manifold. By refining the empirical data distribution before training we redirect model capacity towards high-density regions, which ultimately improves sample fidelity. We evaluate our method by training a Self-Attention GAN on ImageNet at 64x64 resolution, where we outperform the current state-of-the-art models on this task while using 1/2 of the parameters. We also highlight training time savings by training a BigGAN on ImageNet at 128x128 resolution, achieving a 66% increase in Inception Score and a 16% improvement in FID over the baseline model with less than 1/4 the training time.
ProxyNCA++: Revisiting and Revitalizing Proxy Neighborhood Component Analysis
Apr 02, 2020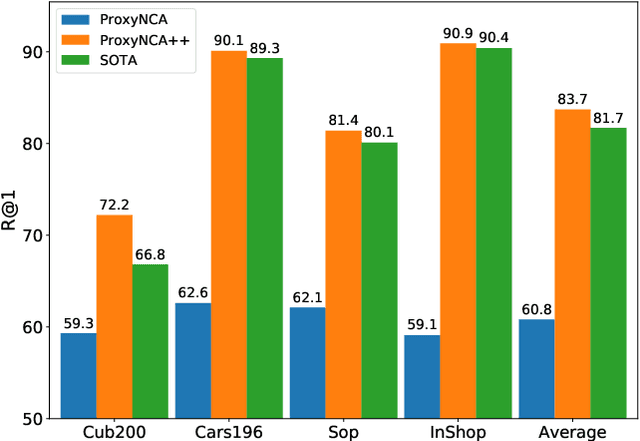
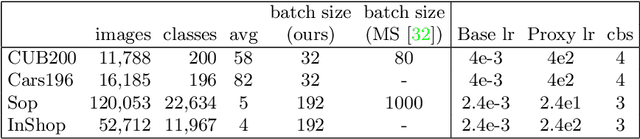
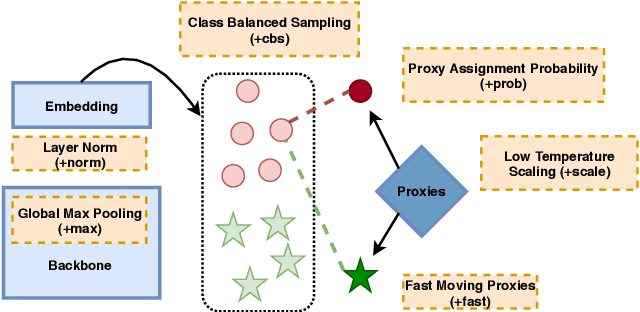

We consider the problem of distance metric learning (DML), where the task is to learn an effective similarity measure between images. We revisit ProxyNCA and incorporate several enhancements. We find that low temperature scaling is a performance-critical component and explain why it works. Besides, we also discover that Global Max Pooling works better in general when compared to Global Average Pooling. Additionally, our proposed fast moving proxies also addresses small gradient issue of proxies, and this component synergizes well with low temperature scaling and Global Max Pooling. Our enhanced model, called ProxyNCA++, achieves a 22.9 percentage point average improvement of Recall@1 across four different zero-shot retrieval datasets compared to the original ProxyNCA algorithm. Furthermore, we achieve state-of-the-art results on the CUB200, Cars196, Sop, and InShop datasets, achieving Recall@1 scores of 72.2, 90.1, 81.4, and 90.9, respectively.
On the Evaluation of Conditional GANs
Jul 11, 2019

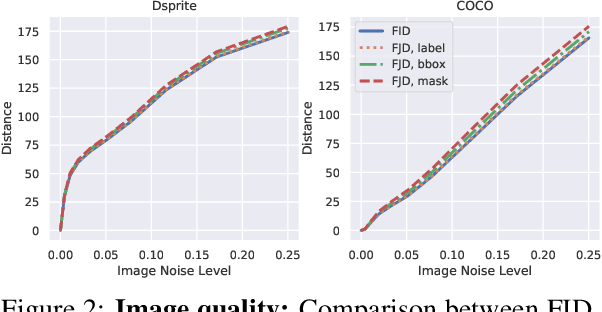
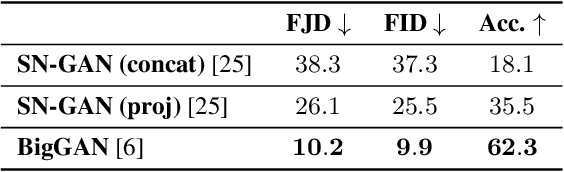
Conditional Generative Adversarial Networks (cGANs) are finding increasingly widespread use in many application domains. Despite outstanding progress, quantitative evaluation of such models often involves multiple distinct metrics to assess different desirable properties such as image quality, intra-conditioning diversity, and conditional consistency, making model benchmarking challenging. In this paper, we propose the Frechet Joint Distance (FJD), which implicitly captures the above mentioned properties in a single metric. FJD is defined as the Frechet Distance of the joint distribution of images and conditionings, making it less sensitive to the often limited per-conditioning sample size. As a result, it scales more gracefully to stronger forms of conditioning such as pixel-wise or multi-modal conditioning. We evaluate FJD on a modified version of the dSprite dataset as well as on the large scale COCO-Stuff dataset, and consistently highlight its benefits when compared to currently established metrics. Moreover, we use the newly introduced metric to compare existing cGAN-based models, with varying conditioning strengths, and show that FJD can be used as a promising single metric for model benchmarking.
Does Object Recognition Work for Everyone?
Jun 18, 2019
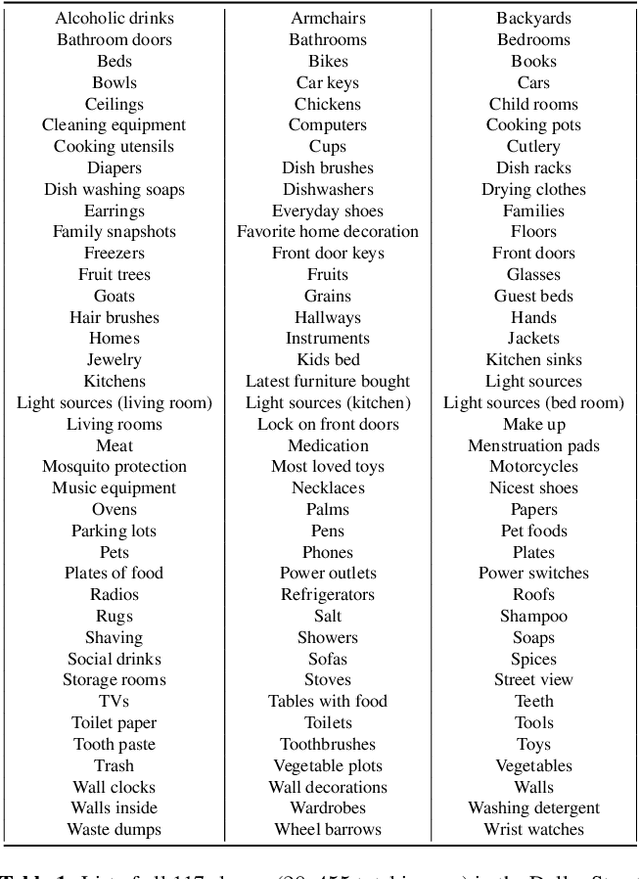
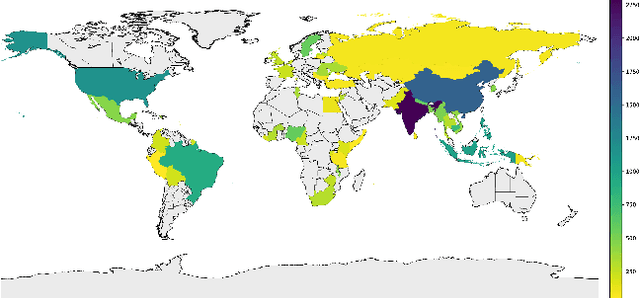

The paper analyzes the accuracy of publicly available object-recognition systems on a geographically diverse dataset. This dataset contains household items and was designed to have a more representative geographical coverage than commonly used image datasets in object recognition. We find that the systems perform relatively poorly on household items that commonly occur in countries with a low household income. Qualitative analyses suggest the drop in performance is primarily due to appearance differences within an object class (e.g., dish soap) and due to items appearing in a different context (e.g., toothbrushes appearing outside of bathrooms). The results of our study suggest that further work is needed to make object-recognition systems work equally well for people across different countries and income levels.
Leveraging Uncertainty Estimates for Predicting Segmentation Quality
Jul 02, 2018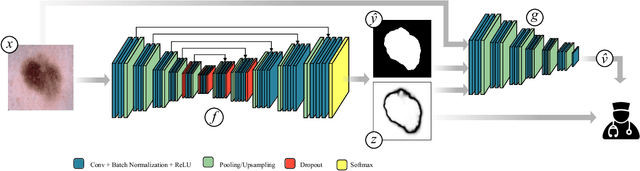
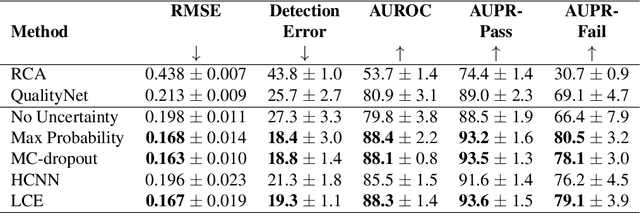
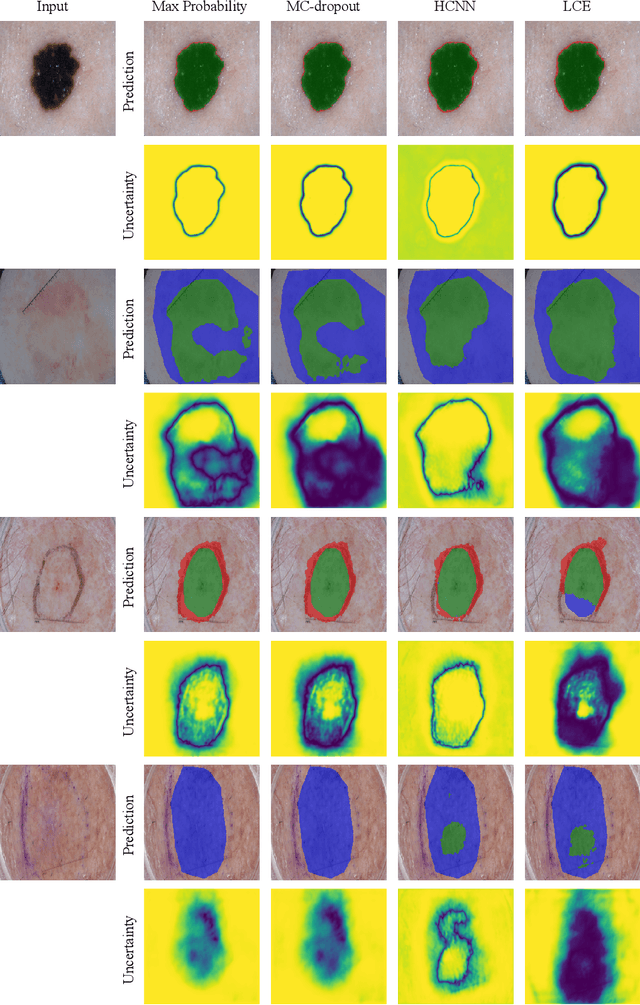
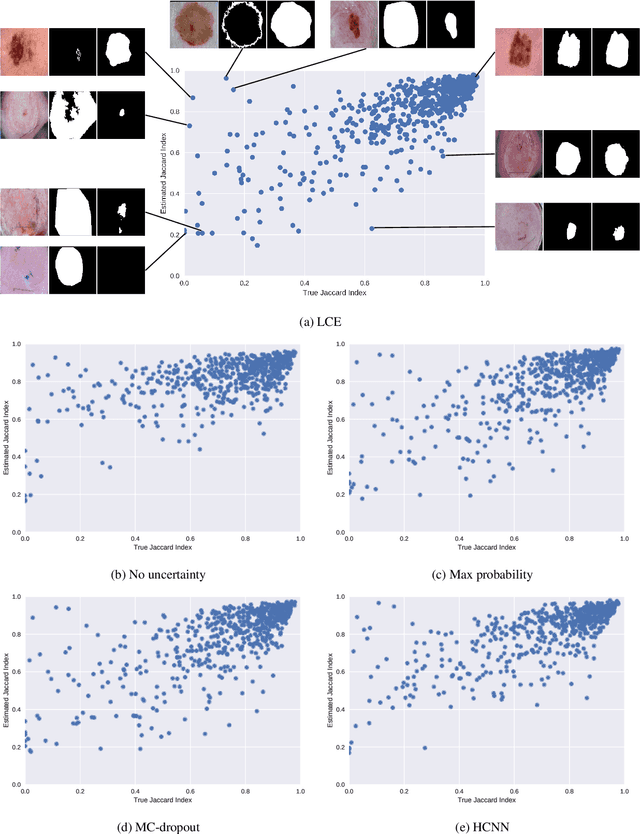
The use of deep learning for medical imaging has seen tremendous growth in the research community. One reason for the slow uptake of these systems in the clinical setting is that they are complex, opaque and tend to fail silently. Outside of the medical imaging domain, the machine learning community has recently proposed several techniques for quantifying model uncertainty (i.e.~a model knowing when it has failed). This is important in practical settings, as we can refer such cases to manual inspection or correction by humans. In this paper, we aim to bring these recent results on estimating uncertainty to bear on two important outputs in deep learning-based segmentation. The first is producing spatial uncertainty maps, from which a clinician can observe where and why a system thinks it is failing. The second is quantifying an image-level prediction of failure, which is useful for isolating specific cases and removing them from automated pipelines. We also show that reasoning about spatial uncertainty, the first output, is a useful intermediate representation for generating segmentation quality predictions, the second output. We propose a two-stage architecture for producing these measures of uncertainty, which can accommodate any deep learning-based medical segmentation pipeline.
Learning Confidence for Out-of-Distribution Detection in Neural Networks
Feb 13, 2018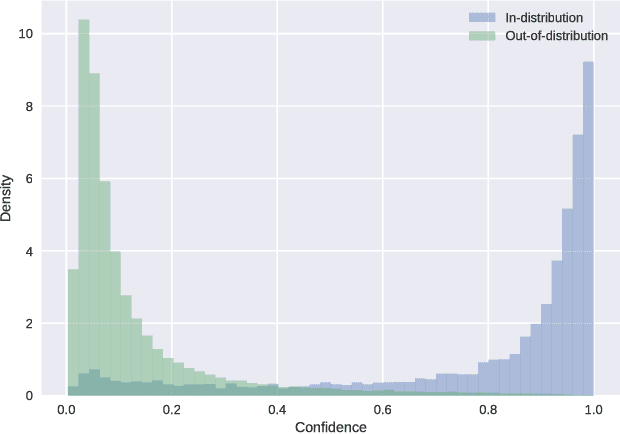
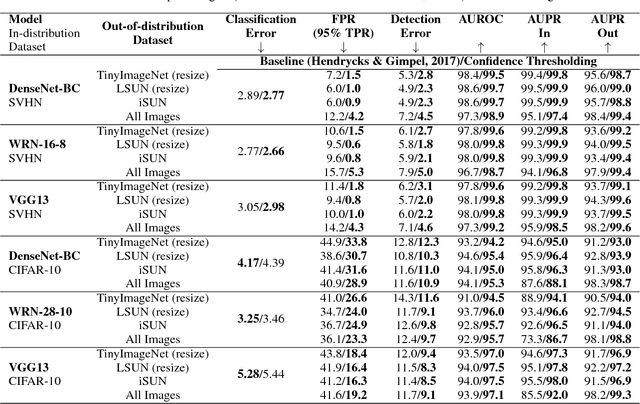
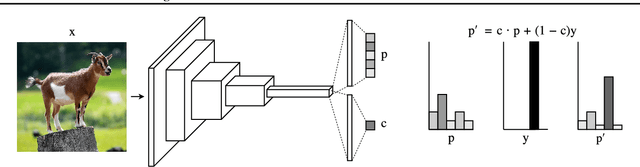
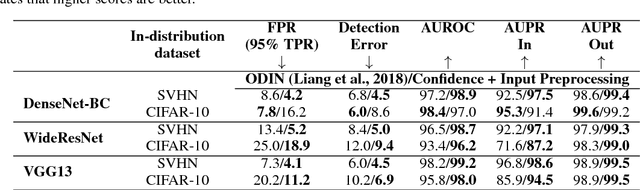
Modern neural networks are very powerful predictive models, but they are often incapable of recognizing when their predictions may be wrong. Closely related to this is the task of out-of-distribution detection, where a network must determine whether or not an input is outside of the set on which it is expected to safely perform. To jointly address these issues, we propose a method of learning confidence estimates for neural networks that is simple to implement and produces intuitively interpretable outputs. We demonstrate that on the task of out-of-distribution detection, our technique surpasses recently proposed techniques which construct confidence based on the network's output distribution, without requiring any additional labels or access to out-of-distribution examples. Additionally, we address the problem of calibrating out-of-distribution detectors, where we demonstrate that misclassified in-distribution examples can be used as a proxy for out-of-distribution examples.
Improved Regularization of Convolutional Neural Networks with Cutout
Nov 29, 2017



Convolutional neural networks are capable of learning powerful representational spaces, which are necessary for tackling complex learning tasks. However, due to the model capacity required to capture such representations, they are often susceptible to overfitting and therefore require proper regularization in order to generalize well. In this paper, we show that the simple regularization technique of randomly masking out square regions of input during training, which we call cutout, can be used to improve the robustness and overall performance of convolutional neural networks. Not only is this method extremely easy to implement, but we also demonstrate that it can be used in conjunction with existing forms of data augmentation and other regularizers to further improve model performance. We evaluate this method by applying it to current state-of-the-art architectures on the CIFAR-10, CIFAR-100, and SVHN datasets, yielding new state-of-the-art results of 2.56%, 15.20%, and 1.30% test error respectively. Code is available at https://github.com/uoguelph-mlrg/Cutout