 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInnerThoughts: Disentangling Representations and Predictions in Large Language Models
Jan 29, 2025



Large language models (LLMs) contain substantial factual knowledge which is commonly elicited by multiple-choice question-answering prompts. Internally, such models process the prompt through multiple transformer layers, building varying representations of the problem within its hidden states. Ultimately, however, only the hidden state corresponding to the final layer and token position are used to predict the answer label. In this work, we propose instead to learn a small separate neural network predictor module on a collection of training questions, that take the hidden states from all the layers at the last temporal position as input and outputs predictions. In effect, such a framework disentangles the representational abilities of LLMs from their predictive abilities. On a collection of hard benchmarks, our method achieves considerable improvements in performance, sometimes comparable to supervised fine-tuning procedures, but at a fraction of the computational cost.
On Evaluation Metrics for Graph Generative Models
Jan 24, 2022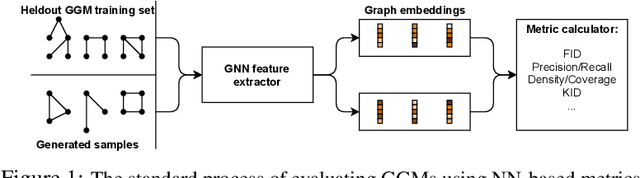
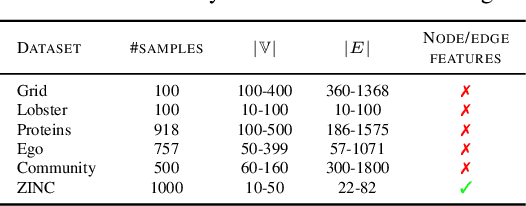
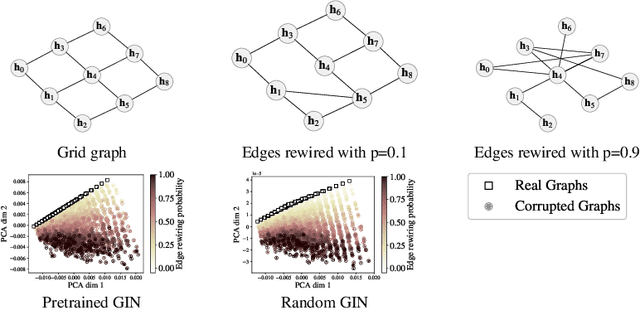
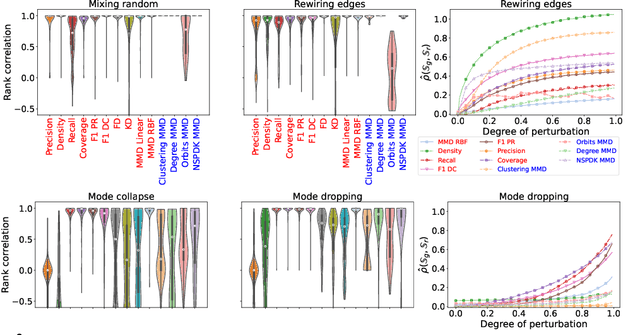
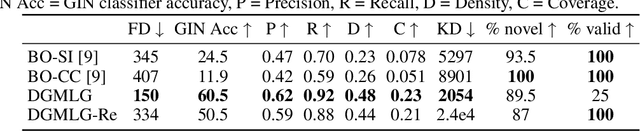
In image generation, generative models can be evaluated naturally by visually inspecting model outputs. However, this is not always the case for graph generative models (GGMs), making their evaluation challenging. Currently, the standard process for evaluating GGMs suffers from three critical limitations: i) it does not produce a single score which makes model selection challenging, ii) in many cases it fails to consider underlying edge and node features, and iii) it is prohibitively slow to perform. In this work, we mitigate these issues by searching for scalar, domain-agnostic, and scalable metrics for evaluating and ranking GGMs. To this end, we study existing GGM metrics and neural-network-based metrics emerging from generative models of images that use embeddings extracted from a task-specific network. Motivated by the power of certain Graph Neural Networks (GNNs) to extract meaningful graph representations without any training, we introduce several metrics based on the features extracted by an untrained random GNN. We design experiments to thoroughly test metrics on their ability to measure the diversity and fidelity of generated graphs, as well as their sample and computational efficiency. Depending on the quantity of samples, we recommend one of two random-GNN-based metrics that we show to be more expressive than pre-existing metrics. While we focus on applying these metrics to GGM evaluation, in practice this enables the ability to easily compute the dissimilarity between any two sets of graphs regardless of domain. Our code is released at: https://github.com/uoguelph-mlrg/GGM-metrics.
Building LEGO Using Deep Generative Models of Graphs
Dec 21, 2020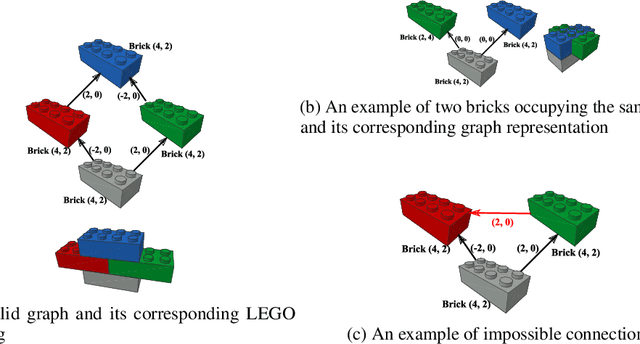
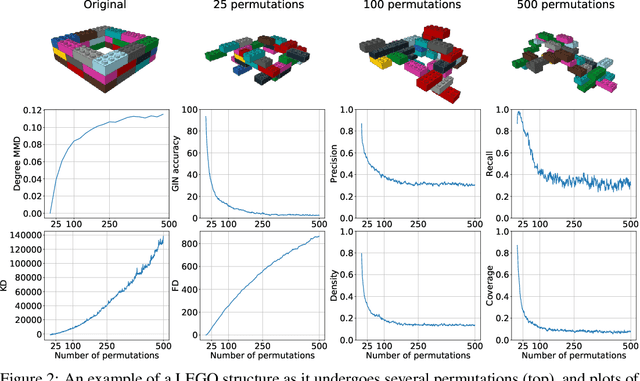
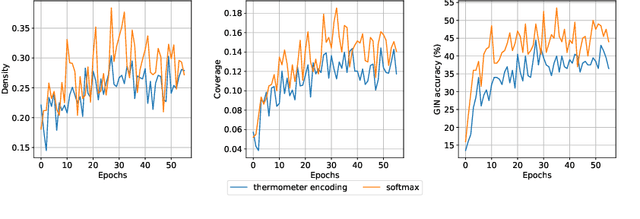
Generative models are now used to create a variety of high-quality digital artifacts. Yet their use in designing physical objects has received far less attention. In this paper, we advocate for the construction toy, LEGO, as a platform for developing generative models of sequential assembly. We develop a generative model based on graph-structured neural networks that can learn from human-built structures and produce visually compelling designs. Our code is released at: https://github.com/uoguelph-mlrg/GenerativeLEGO.