 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-WM: Robotic Task and Motion Planning Guided by Hierarchical World Model
Feb 11, 2026World models are becoming central to robotic planning and control, as they enable prediction of future state transitions. Existing approaches often emphasize video generation or natural language prediction, which are difficult to directly ground in robot actions and suffer from compounding errors over long horizons. Traditional task and motion planning relies on symbolic logic world models, such as planning domains, that are robot-executable and robust for long-horizon reasoning. However, these methods typically operate independently of visual perception, preventing synchronized symbolic and perceptual state prediction. We propose a Hierarchical World Model (H-WM) that jointly predicts logical and visual state transitions within a unified bilevel framework. H-WM combines a high-level logical world model with a low-level visual world model, integrating the robot-executable, long-horizon robustness of symbolic reasoning with perceptual grounding from visual observations. The hierarchical outputs provide stable and consistent intermediate guidance for long-horizon tasks, mitigating error accumulation and enabling robust execution across extended task sequences. To train H-WM, we introduce a robotic dataset that aligns robot motion with symbolic states, actions, and visual observations. Experiments across vision-language-action (VLA) control policies demonstrate the effectiveness and generality of the approach.
A Balanced Neuro-Symbolic Approach for Commonsense Abductive Logic
Jan 26, 2026Although Large Language Models (LLMs) have demonstrated impressive formal reasoning abilities, they often break down when problems require complex proof planning. One promising approach for improving LLM reasoning abilities involves translating problems into formal logic and using a logic solver. Although off-the-shelf logic solvers are in principle substantially more efficient than LLMs at logical reasoning, they assume that all relevant facts are provided in a question and are unable to deal with missing commonsense relations. In this work, we propose a novel method that uses feedback from the logic solver to augment a logic problem with commonsense relations provided by the LLM, in an iterative manner. This involves a search procedure through potential commonsense assumptions to maximize the chance of finding useful facts while keeping cost tractable. On a collection of pure-logical reasoning datasets, from which some commonsense information has been removed, our method consistently achieves considerable improvements over existing techniques, demonstrating the value in balancing neural and symbolic elements when working in human contexts.
Cost and Complexity as Barriers to RTLS Adoption in SMEs: A Survey and Analysis
Dec 10, 2025Real-time location systems (RTLSs) are central to Industry 4.0 and emerging Industry 5.0, providing the spatiotemporal data required for asset tracking, workflow optimization, safety, and integration with WMS, MES, and digital twins. While large enterprises increasingly deploy RTLSs, adoption among small and medium-sized enterprises (SMEs) remains limited. This paper examines whether cost and installation complexity are primary barriers to SME adoption. We position RTLSs within the broader Industry 4.0 and Logistics 4.0 landscape and summarize their operational value. We then synthesize evidence from the literature on technical, financial, and organizational constraints, with emphasis on infrastructure requirements, calibration effort, integration with legacy systems, and human factors. To complement this analysis, we report results from an online survey of sixteen manufacturing and technology professionals in Canada and the United States. Respondents report strong perceived value for real-time tracking but identify upfront cost, installation effort, integration difficulty, and reliance on multiple anchor nodes as dominant obstacles. Most indicate acceptable upfront investments below $10,000 and express a clear preference for low-infrastructure deployments with minimized anchor counts. Building on these findings, we outline design directions for SME-focused RTLSs, including wireless and modular architectures, cloud-managed and self-calibrating systems, standardized integration interfaces, and anchor-minimizing or anchor-free localization methods. Overall, the results show that limited SME adoption stems less from insufficient perceived value than from misalignment between current RTLS deployment models and SME resource constraints.
C3PO: Optimized Large Language Model Cascades with Probabilistic Cost Constraints for Reasoning
Nov 10, 2025Large language models (LLMs) have achieved impressive results on complex reasoning tasks, but their high inference cost remains a major barrier to real-world deployment. A promising solution is to use cascaded inference, where small, cheap models handle easy queries, and only the hardest examples are escalated to more powerful models. However, existing cascade methods typically rely on supervised training with labeled data, offer no theoretical generalization guarantees, and provide limited control over test-time computational cost. We introduce C3PO (Cost Controlled Cascaded Prediction Optimization), a self-supervised framework for optimizing LLM cascades under probabilistic cost constraints. By focusing on minimizing regret with respect to the most powerful model (MPM), C3PO avoids the need for labeled data by constructing a cascade using only unlabeled model outputs. It leverages conformal prediction to bound the probability that inference cost exceeds a user-specified budget. We provide theoretical guarantees on both cost control and generalization error, and show that our optimization procedure is effective even with small calibration sets. Empirically, C3PO achieves state-of-the-art performance across a diverse set of reasoning benchmarks including GSM8K, MATH-500, BigBench-Hard and AIME, outperforming strong LLM cascading baselines in both accuracy and cost-efficiency. Our results demonstrate that principled, label-free cascade optimization can enable scalable LLM deployment.
E-CARE: An Efficient LLM-based Commonsense-Augmented Framework for E-Commerce
Nov 06, 2025Finding relevant products given a user query plays a pivotal role in an e-commerce platform, as it can spark shopping behaviors and result in revenue gains. The challenge lies in accurately predicting the correlation between queries and products. Recently, mining the cross-features between queries and products based on the commonsense reasoning capacity of Large Language Models (LLMs) has shown promising performance. However, such methods suffer from high costs due to intensive real-time LLM inference during serving, as well as human annotations and potential Supervised Fine Tuning (SFT). To boost efficiency while leveraging the commonsense reasoning capacity of LLMs for various e-commerce tasks, we propose the Efficient Commonsense-Augmented Recommendation Enhancer (E-CARE). During inference, models augmented with E-CARE can access commonsense reasoning with only a single LLM forward pass per query by utilizing a commonsense reasoning factor graph that encodes most of the reasoning schema from powerful LLMs. The experiments on 2 downstream tasks show an improvement of up to 12.1% on precision@5.
GraphPPD: Posterior Predictive Modelling for Graph-Level Inference
Aug 23, 2025Accurate modelling and quantification of predictive uncertainty is crucial in deep learning since it allows a model to make safer decisions when the data is ambiguous and facilitates the users' understanding of the model's confidence in its predictions. Along with the tremendously increasing research focus on \emph{graph neural networks} (GNNs) in recent years, there have been numerous techniques which strive to capture the uncertainty in their predictions. However, most of these approaches are specifically designed for node or link-level tasks and cannot be directly applied to graph-level learning problems. In this paper, we propose a novel variational modelling framework for the \emph{posterior predictive distribution}~(PPD) to obtain uncertainty-aware prediction in graph-level learning tasks. Based on a graph-level embedding derived from one of the existing GNNs, our framework can learn the PPD in a data-adaptive fashion. Experimental results on several benchmark datasets exhibit the effectiveness of our approach.
Reasoning on a Budget: A Survey of Adaptive and Controllable Test-Time Compute in LLMs
Jul 02, 2025Large language models (LLMs) have rapidly progressed into general-purpose agents capable of solving a broad spectrum of tasks. However, current models remain inefficient at reasoning: they apply fixed inference-time compute regardless of task complexity, often overthinking simple problems while underthinking hard ones. This survey presents a comprehensive review of efficient test-time compute (TTC) strategies, which aim to improve the computational efficiency of LLM reasoning. We introduce a two-tiered taxonomy that distinguishes between L1-controllability, methods that operate under fixed compute budgets, and L2-adaptiveness, methods that dynamically scale inference based on input difficulty or model confidence. We benchmark leading proprietary LLMs across diverse datasets, highlighting critical trade-offs between reasoning performance and token usage. Compared to prior surveys on efficient reasoning, our review emphasizes the practical control, adaptability, and scalability of TTC methods. Finally, we discuss emerging trends such as hybrid thinking models and identify key challenges for future work towards making LLMs more computationally efficient, robust, and responsive to user constraints.
SKOLR: Structured Koopman Operator Linear RNN for Time-Series Forecasting
Jun 17, 2025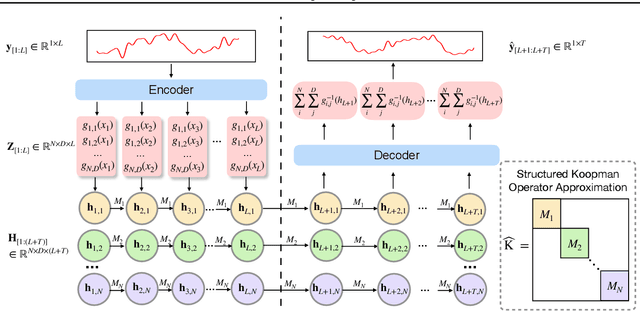



Koopman operator theory provides a framework for nonlinear dynamical system analysis and time-series forecasting by mapping dynamics to a space of real-valued measurement functions, enabling a linear operator representation. Despite the advantage of linearity, the operator is generally infinite-dimensional. Therefore, the objective is to learn measurement functions that yield a tractable finite-dimensional Koopman operator approximation. In this work, we establish a connection between Koopman operator approximation and linear Recurrent Neural Networks (RNNs), which have recently demonstrated remarkable success in sequence modeling. We show that by considering an extended state consisting of lagged observations, we can establish an equivalence between a structured Koopman operator and linear RNN updates. Building on this connection, we present SKOLR, which integrates a learnable spectral decomposition of the input signal with a multilayer perceptron (MLP) as the measurement functions and implements a structured Koopman operator via a highly parallel linear RNN stack. Numerical experiments on various forecasting benchmarks and dynamical systems show that this streamlined, Koopman-theory-based design delivers exceptional performance.
One Demo Is All It Takes: Planning Domain Derivation with LLMs from A Single Demonstration
May 23, 2025Pre-trained Large Language Models (LLMs) have shown promise in solving planning problems but often struggle to ensure plan correctness, especially for long-horizon tasks. Meanwhile, traditional robotic task and motion planning (TAMP) frameworks address these challenges more reliably by combining high-level symbolic search with low-level motion planning. At the core of TAMP is the planning domain, an abstract world representation defined through symbolic predicates and actions. However, creating these domains typically involves substantial manual effort and domain expertise, limiting generalizability. We introduce Planning Domain Derivation with LLMs (PDDLLM), a novel approach that combines simulated physical interaction with LLM reasoning to improve planning performance. The method reduces reliance on humans by inferring planning domains from a single annotated task-execution demonstration. Unlike prior domain-inference methods that rely on partially predefined or language descriptions of planning domains, PDDLLM constructs domains entirely from scratch and automatically integrates them with low-level motion planning skills, enabling fully automated long-horizon planning. PDDLLM is evaluated on over 1,200 diverse tasks spanning nine environments and benchmarked against six LLM-based planning baselines, demonstrating superior long-horizon planning performance, lower token costs, and successful deployment on multiple physical robot platforms.
Half Search Space is All You Need
May 19, 2025Neural Architecture Search (NAS) is a powerful tool for automating architecture design. One-Shot NAS techniques, such as DARTS, have gained substantial popularity due to their combination of search efficiency with simplicity of implementation. By design, One-Shot methods have high GPU memory requirements during the search. To mitigate this issue, we propose to prune the search space in an efficient automatic manner to reduce memory consumption and search time while preserving the search accuracy. Specifically, we utilise Zero-Shot NAS to efficiently remove low-performing architectures from the search space before applying One-Shot NAS to the pruned search space. Experimental results on the DARTS search space show that our approach reduces memory consumption by 81% compared to the baseline One-Shot setup while achieving the same level of accuracy.