 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC3PO: Optimized Large Language Model Cascades with Probabilistic Cost Constraints for Reasoning
Nov 10, 2025Large language models (LLMs) have achieved impressive results on complex reasoning tasks, but their high inference cost remains a major barrier to real-world deployment. A promising solution is to use cascaded inference, where small, cheap models handle easy queries, and only the hardest examples are escalated to more powerful models. However, existing cascade methods typically rely on supervised training with labeled data, offer no theoretical generalization guarantees, and provide limited control over test-time computational cost. We introduce C3PO (Cost Controlled Cascaded Prediction Optimization), a self-supervised framework for optimizing LLM cascades under probabilistic cost constraints. By focusing on minimizing regret with respect to the most powerful model (MPM), C3PO avoids the need for labeled data by constructing a cascade using only unlabeled model outputs. It leverages conformal prediction to bound the probability that inference cost exceeds a user-specified budget. We provide theoretical guarantees on both cost control and generalization error, and show that our optimization procedure is effective even with small calibration sets. Empirically, C3PO achieves state-of-the-art performance across a diverse set of reasoning benchmarks including GSM8K, MATH-500, BigBench-Hard and AIME, outperforming strong LLM cascading baselines in both accuracy and cost-efficiency. Our results demonstrate that principled, label-free cascade optimization can enable scalable LLM deployment.
Half Search Space is All You Need
May 19, 2025Neural Architecture Search (NAS) is a powerful tool for automating architecture design. One-Shot NAS techniques, such as DARTS, have gained substantial popularity due to their combination of search efficiency with simplicity of implementation. By design, One-Shot methods have high GPU memory requirements during the search. To mitigate this issue, we propose to prune the search space in an efficient automatic manner to reduce memory consumption and search time while preserving the search accuracy. Specifically, we utilise Zero-Shot NAS to efficiently remove low-performing architectures from the search space before applying One-Shot NAS to the pruned search space. Experimental results on the DARTS search space show that our approach reduces memory consumption by 81% compared to the baseline One-Shot setup while achieving the same level of accuracy.
Variation Matters: from Mitigating to Embracing Zero-Shot NAS Ranking Function Variation
Feb 27, 2025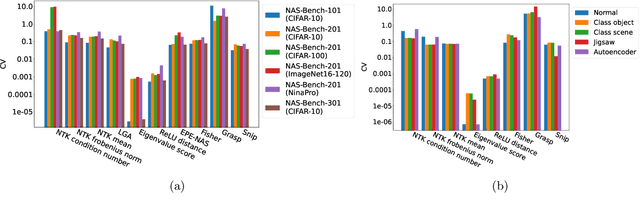

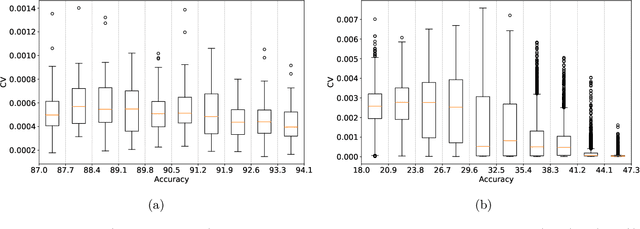

Neural Architecture Search (NAS) is a powerful automatic alternative to manual design of a neural network. In the zero-shot version, a fast ranking function is used to compare architectures without training them. The outputs of the ranking functions often vary significantly due to different sources of randomness, including the evaluated architecture's weights' initialization or the batch of data used for calculations. A common approach to addressing the variation is to average a ranking function output over several evaluations. We propose taking into account the variation in a different manner, by viewing the ranking function output as a random variable representing a proxy performance metric. During the search process, we strive to construct a stochastic ordering of the performance metrics to determine the best architecture. Our experiments show that the proposed stochastic ordering can effectively boost performance of a search on standard benchmark search spaces.
Sparse Decomposition of Graph Neural Networks
Oct 25, 2024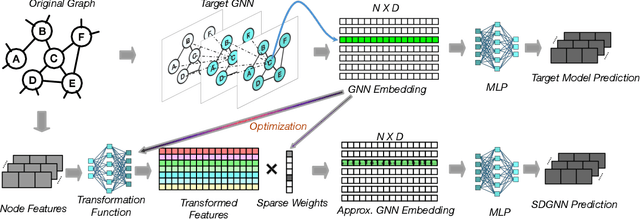
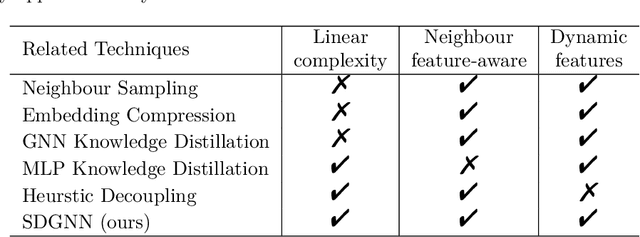
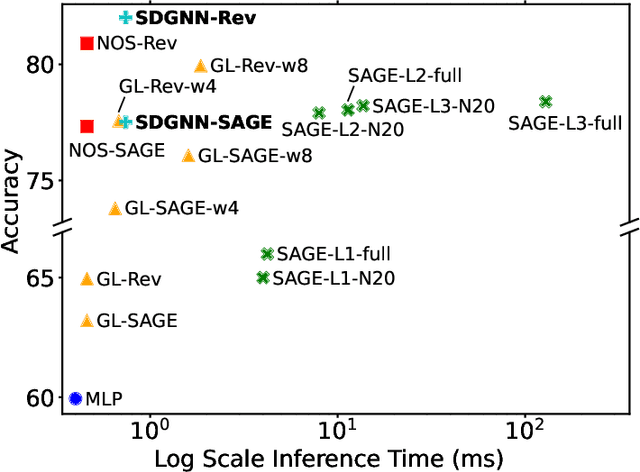

Graph Neural Networks (GNN) exhibit superior performance in graph representation learning, but their inference cost can be high, due to an aggregation operation that can require a memory fetch for a very large number of nodes. This inference cost is the major obstacle to deploying GNN models with \emph{online prediction} to reflect the potentially dynamic node features. To address this, we propose an approach to reduce the number of nodes that are included during aggregation. We achieve this through a sparse decomposition, learning to approximate node representations using a weighted sum of linearly transformed features of a carefully selected subset of nodes within the extended neighbourhood. The approach achieves linear complexity with respect to the average node degree and the number of layers in the graph neural network. We introduce an algorithm to compute the optimal parameters for the sparse decomposition, ensuring an accurate approximation of the original GNN model, and present effective strategies to reduce the training time and improve the learning process. We demonstrate via extensive experiments that our method outperforms other baselines designed for inference speedup, achieving significant accuracy gains with comparable inference times for both node classification and spatio-temporal forecasting tasks.
Graph Knowledge Distillation to Mixture of Experts
Jun 17, 2024In terms of accuracy, Graph Neural Networks (GNNs) are the best architectural choice for the node classification task. Their drawback in real-world deployment is the latency that emerges from the neighbourhood processing operation. One solution to the latency issue is to perform knowledge distillation from a trained GNN to a Multi-Layer Perceptron (MLP), where the MLP processes only the features of the node being classified (and possibly some pre-computed structural information). However, the performance of such MLPs in both transductive and inductive settings remains inconsistent for existing knowledge distillation techniques. We propose to address the performance concerns by using a specially-designed student model instead of an MLP. Our model, named Routing-by-Memory (RbM), is a form of Mixture-of-Experts (MoE), with a design that enforces expert specialization. By encouraging each expert to specialize on a certain region on the hidden representation space, we demonstrate experimentally that it is possible to derive considerably more consistent performance across multiple datasets.